数据降维处理:PCA之奇异值分解(SVD)介绍
请点击上面公众号,免费订阅。
《实例》阐述算法,通俗易懂,助您对算法的理解达到一个新高度。包含但不限于:经典算法,机器学习,深度学习,LeetCode 题解,Kaggle 实战。期待您的到来!
01
—
回顾
昨天实践了一个数据降维的例子,用到了5个二维的样本点,通过特征值分解法,将样本降维为1个维度,这个过程又称为数据压缩,关于这篇文章,请参考:
数据降维处理:PCA之特征值分解法例子解析
今天来进一步谈谈数据降维,以实现主成分提取的另一种应用非常广泛的方法:奇异值分解法,它和特征值分解法有些相似,但是从某些角度讲,比特征值分解法更强大。
在阐述矩阵分解法时,提到了一个非常重要的概念,向量在正交基上的投影,今天再温习下,一个向量是多少,一定是相对于正交基而获取的,如果正交基变了,这个向量的方向也就变了,因此要想确定向量的方向,就得找到它位于的由正交基确定的空间;第二,一个向量在某个主轴的投影就是这个向量点乘这个主轴的方向向量,这个也是PCA之矩阵分解法和奇异矩阵分解法的理论基础。
下面,再介绍一个非常重要的关于矩阵的线性变换的操作:旋转和压缩,这些都是以上两种方法的基础。
02
—
向量的旋转变换
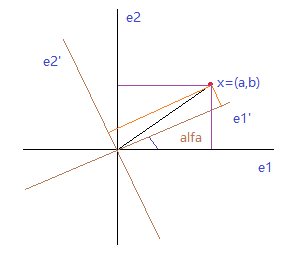
如下所示,在由 (e1,e2) 正交基确定的空间中,一个样本点 x = (a,b),如果将原来的正交基 (e1,e2) 旋转一个角度 alfa 后,新的正交基变为 (e1',e2'),求样本点在新的空间中的坐标 x' = (a',b') 和这种旋转变换的矩阵 u 。
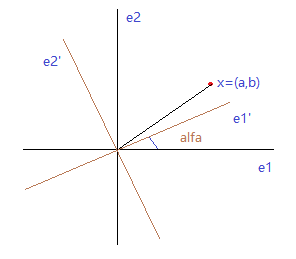
利用向量在主轴上的投影由点乘这个知识点,可以得到:
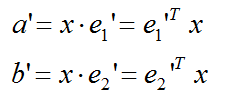
化为矩阵表达:
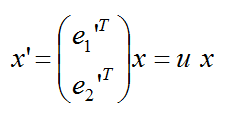
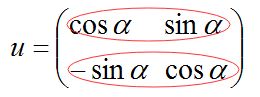
通过上式可以看到,u 就是变换矩阵的,并且通过上图可以求出 u 的各个元素,因为旋转角度 alfa 已经求出; 并且根据新的基(e1', e2')肯定也是正交的这个原则,所以 u 必然是正交矩阵。
这样向量 x 通过 u 变换矩阵,获得了一次旋转,由刚开始的矩形(由紫色边确定的),旋转到由橙色边确定的矩形,并且仅仅是做了一次旋转,向量 x 的大小没有发生任何改变。如果要想改变向量的长度,比如压缩这个向量 x,只需要乘以一个标量 lamda(lambda < 1)即可。
有了向量旋转变换的知识储备,再来理解奇异值分解,还是回过头去想特征值分解,都可能会变得好理解了,接下来分析奇异值分解法是如何做到压缩数据,并且能确保数据的主要信息不丢失的呢?
03
—
奇异值分解
通过上面的分析,可以看出要想定位到主成分确定的正交基上,首先得保证变换后的基必须还是正交基,还记得利用特征值分解法求第一主成分的方向向量吗? 我们求出 X X' (其中X'表示X的转置)对应的特征向量,并按照特征值的大小依次排序,取前 k 个特征值对应的特征量,组成一个特征矩阵,然后数据映射到这个矩阵上,便压缩数据为 k 维,在奇异值分解方法中,一个正交基仍然使用 X X' 的特征向量,但是不同的是:
1. 奇异值分解法,使用两个正交基,分别称为左奇异向量和右奇异向量,一般用 u 表示左奇异向量,其中 X' X 矩阵的特征向量确定了这个左奇异向量;一般用 v 表示右奇异向量,它的值是和特征值分解法用到的X X' 确定的特征值向量是一致的。
2. 中间的对角矩阵不再像特征值分解法那样由特征值组成的对角阵,而是特征值开根号,并成为奇异值,这是方法名字由来,奇异值和特征值有点类似,可以类别着理解吧。
3. 特征值分解法分解的矩阵必须是方阵,这就是PCA特征值分解必须要对 XX' 分解的原因,而奇异值分解法可以对任意矩阵分解。
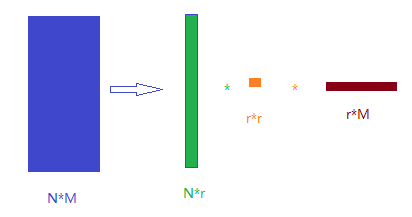
4. 奇异值分解任意一个 N * M 的矩阵为如下的样子:
![]()
如何推理出U, 中间的奇异阵, V 的shape呢,因为 U 和 V 都是正交矩阵,所以U 和 V 是方阵,所以 U 为 N * N的方阵,V为 M * M 的方阵,由此可知中间的奇异阵为 N * M 的对角阵。
U 和 V 为什么都是正交阵呢? 因为在第二节中介绍说过只有正交阵才能完成向量的旋转,正是依靠这两个正交阵,奇异值分解法能完成两个方向的数据压缩,而特征值分解法由于只有一个正交阵所以只能完成一个方向的数据压缩。
一点说明:
奇异值σ的梯度比较大,在许多情况下,从大到小排序后的奇异值的前10%的和,就占了全部的奇异值之和的99%以上。也就是说,我们也可以用前 r 个奇异值来近似描述 我们的数据,这样奇异值压缩后的数据占的空间就大大缩小了,可以看到压缩后的3个矩阵的面积原来相比大大缩小了。
04
—
总结
今天总结了奇异值分解的基本原理。在明天的推送中,将介绍如何把一个矩阵 N*M ,分解为3个矩阵,其中两个为正交阵,中间为奇异阵。
同时可以看出奇异值分解法压缩数据,可以完成两个方向的压缩,可以按行和按列进行将维,当按行压缩时,可以理解为样本有重复的数据,按列压缩就是将维了,那么这个过程是怎样做到的呢?
接下来,再借助相关的数据集,比较下利用SVD和EVD在做PCA时的一些实际应用和不同之处吧。
如果您想了解机器学习的其他相关算法和实战,请参考《算法channel》已推送的其他文章:
1 机器学习:不得不知的概念(1)
2 机器学习:不得不知的概念(2)
3 机器学习:不得不知的概念(3)
4 回归分析简介
5 最小二乘法:背后的假设和原理(前篇)
6 最小二乘法原理(后):梯度下降求权重参数
7 机器学习之线性回归:算法兑现为python代码
8 机器学习之线性回归:OLS 无偏估计及相关性python分析
9 机器学习线性回归:谈谈多重共线性问题及相关算法
10 机器学习:说说L1和L2正则化
11 机器学习逻辑回归:原理解析及代码实现
12 机器学习逻辑回归:算法兑现为python代码
13 机器学习:谈谈决策树
14 机器学习:对决策树剪枝
15 机器学习决策树:sklearn分类和回归
16 机器学习决策树:提炼出分类器算法
17 机器学习:说说贝叶斯分类
18 朴素贝叶斯分类器:例子解释
19 朴素贝叶斯分类:拉普拉斯修正
20 机器学习:单词拼写纠正器python实现
21 机器学习:半朴素贝叶斯分类器
22 机器学习期望最大算法:实例解析
23 机器学习高斯混合模型(前篇):聚类原理分析
24 机器学习高斯混合模型(中篇):聚类求解
25 机器学习高斯混合模型(后篇):GMM求解完整代码实现
26 高斯混合模型:不掉包实现多维数据聚类分析
27 高斯混合模型:GMM求解完整代码实现
28 数据降维处理:背景及基本概念
29 数据降维处理:PCA之特征值分解法例子解析
请记住:每天一小步,日积月累一大步!

《实例》阐述算法,通俗易懂,助您对算法的理解达到一个新高度。包含但不限于:经典算法,机器学习,深度学习,LeetCode 题解,Kaggle 实战。期待您的到来!