机器学习建模全流程及资料总结(4)
五. 结果分析
结果分析我们包含两部分,一是训练过程的分析,二是模型效果的分析。
5.1 模型误差评估
关于偏差和方差的问题不再叙述,偏差和方差是统计模型必有,除了增加数据以外,主要还是通过调整模型的超参来降低偏差和方差。
调参问题——网格搜素GridSearchCV和随机搜素RandomizedSearchCV可以提供一定的方案,但是最主要的几点观点是:
1)在数据量足够的情况下,xgboost 一般不需要大费周章调参,其他模型也是如此,在比赛中一点提升很有用,在项目中可能并不;另外所谓的提升也是存在偏差的,提升是在验证集上的,如何客观评价模型的提升更重要;
2)了解模型原理,掌握调参技巧,合理调参;xgboost 可调的 树深,最小子节点权重,学习率等,其他参数一般不调;
3)调参后带来提升,也可能带来更高的偏差和方差,因此调参必须紧密结合评估指标。
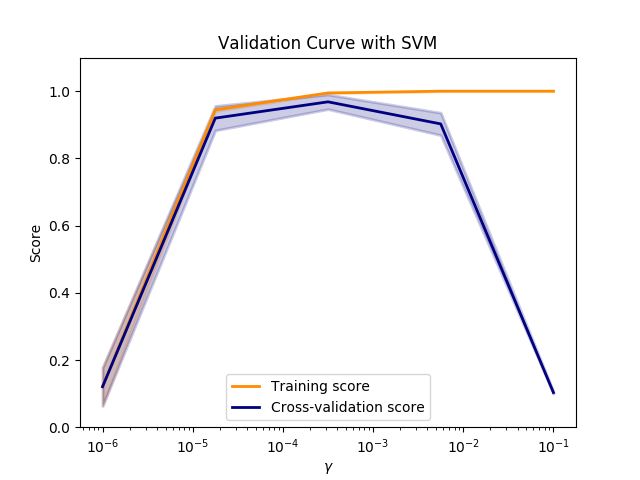
验证曲线
绘制单个超参数对训练分数和验证分数的影响,有时有助于发现该估计是否因为某些超参数的值 而出现过拟合或欠拟合。
可以用 validation_curve方法,不满意的话自己写个循环即可,即每个循环选取超参数的一个值,然后cv训练得到训练集和验证集的分数,画如下曲线,然后可以得到参数大概最佳值。
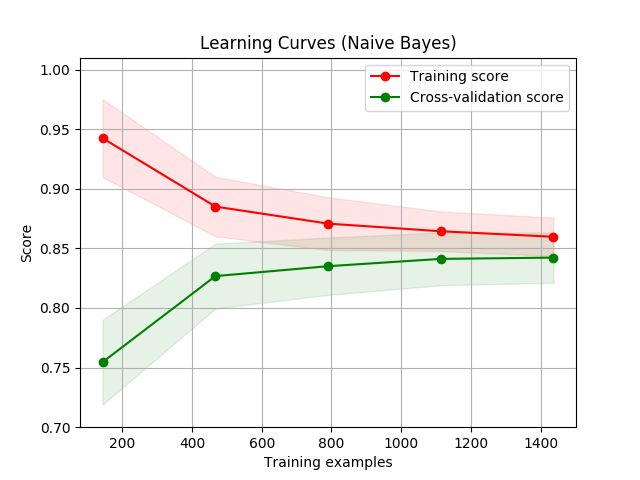
学习曲线
学习曲线显示了对于不同数量的训练样本的估计器的验证和训练评分。它可以帮助我们发现从增加更多的训 练数据中能获益多少,以及估计是否受到更多来自方差或偏差的影响。
注意学习曲线的含义。
还有一种我们经常关注的,就是随着训练的轮次,训练集和测试集上的分数,用来判断是否过拟合,以及训练的收敛性。
5.2 模型效果分析
这里我们介绍几个重要的评估指标。推荐几篇文章看,不多叙述。如下以二分类问题为准。
机器学习之分类性能度量指标 : ROC曲线、AUC值、正确率、召回率
机器学习模型性能评估(一):错误率与精度、P-R曲线和ROC曲线
机器学习模型性能评估二:代价曲线与性能评估方法总结
一维评估指标包括:准确率,召回率,f1分数。称之为一维,他们对应于分类模型的一个阈值下的分类表现。进而可以画出一个混淆矩阵。metrics.classification_report 是个不错的api
二维评估指标包括: ROC曲线,AUC值,AUC 的含义需要掌握,ROC 的横坐标纵坐标。AUC 的意义还可以理解为正样本排在负样本前面的概率,对于不平衡的数据,这一指标往往不好用。
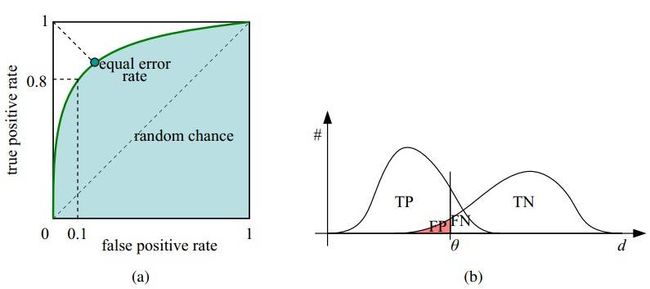
模型评估常用指标这一篇是综合一维二维指标的介绍。
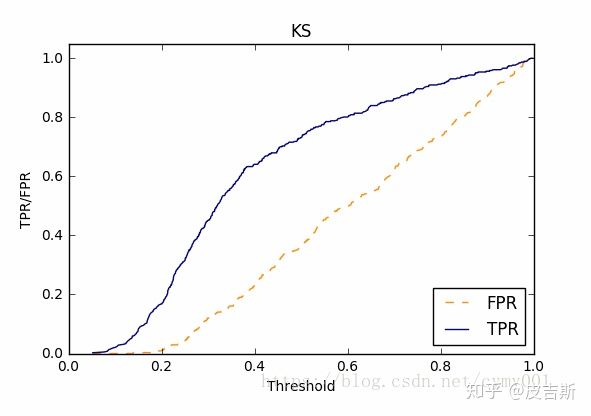
再着重介绍一下ks曲线和逾期率曲线。在风控业务上这一曲线是十分重要的。ks值就是ks曲线中两条曲线之间的最大间隔距离。但是在实际情况,模型并不是要选取ks值附近作为阈值,而是根据业务允许的坏账定通过率的,因此,还有一种曲线可以表达这种需求。
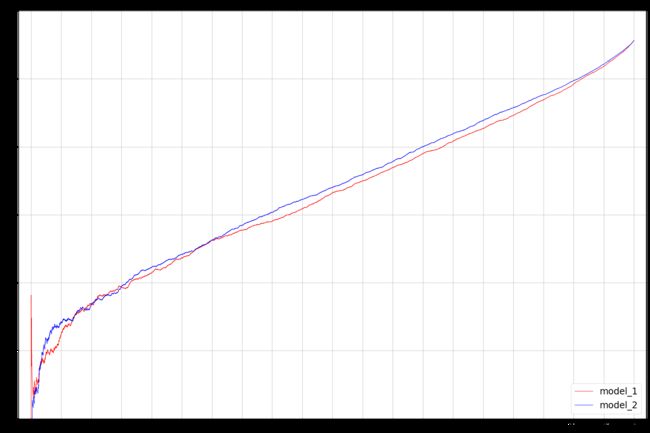
如上图所示,对应不同通过率(也可认为是分数/阈值)下坏账的比例(即坏账数/通过数),尤其是当两个模型AUC差不多时,比较两个模型业务上的效果。曲线画法也很简单,将所有数据(分数,label)排序,然后一个一个通过。下面的方法可供参考。lsta,lstb是两个模型对于一组测试数据(分数,label)的排序后的列表。
def plot_passover_curve(lsta, lstb, name):
plt.figure(figsize=(30,20))
plt.grid()
pass_r = []
over1_r = []
over1 = 0
over2_r = []
over2 = 0
tot = len(lsta)
for i in range(tot):
pass_r.append((i+1)/tot)
over1 += lsta[i][1]
over1_r.append(over1/(i+1))
over2 += lstb[i][1]
over2_r.append(over2/(i+1))
plt.plot(pass_r, over1_r, lw=1, color='r', label='model_1')
plt.plot(pass_r, over2_r, lw=1, color='b', label='model_2')
plt.xlim([-0.02, 1.02])
plt.ylim([0, 0.3])
plt.xticks(np.linspace(0, 1.0, 21))
plt.yticks(np.linspace(0, 0.30, 7))
plt.xlabel('pass_rate')
plt.ylabel('overdue rate')
plt.title('%s pass rate - overdue rate' % name,fontsize=22)
plt.legend(loc="lower right", prop=font1)
plt.show()
font1 = {'family' : 'Times New Roman',
'weight' : 'normal',
'size' : 24}机器学习模型/做项目及分析的完整流程基本就这些了~
系列文章结束(完)