jmeter常用功能(实战详解)
目录
- 环境准备
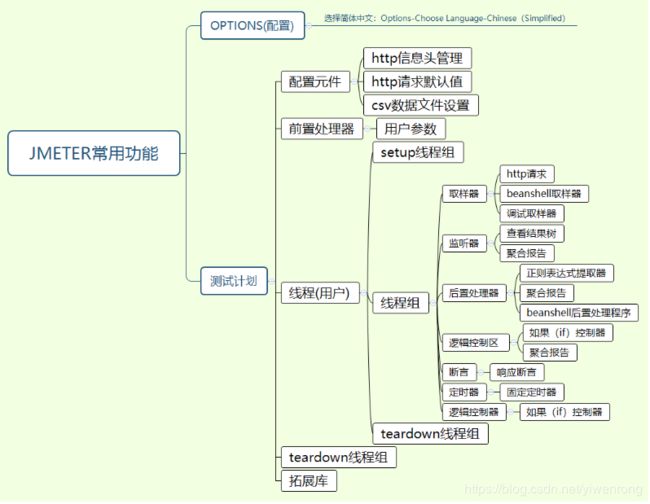
- 一、常用功能图
- 二、功能配置
- 2.1 jmeter修改为中文界面
- 2.2 配置元件
- 2.2.1 Http信息头管理
- 2.2.2 Http请求默认值
- 2.3 取样器
- 2.3.1 调试取样器
- 2.4 逻辑控制器
- 2.4.1 如果(if)控制器
- 三、参数化
- 3.1 CSV数据文件设置
- 3.2 用户定义变量
- 3.3 函数助手
- 3.3.1 Random(随机数)
- 3.3.2 __CSVRead
- 3.4 用户参数
- 3.5 全局变量
- 四、模拟用户操作
- 4.1 用户访问
- 取样器
- 4.1.1 Http请求
- 4.2 模拟多用户访问
- 线程组
- 4.2.1 Setup线程组
- 4.2.2 线程组(普通)
- 4.2.3 TearDown线程组
- 4.3 多用户访问控制
- 定时器
- 4.3.1 常数吞吐量定时器(控制TPS)
- 4.3.2 固定时器(时间间隔)
- 五、关联断言
- 5.1 断言
- 5.1.1 响应断言
- 5.2 后置处理器
- 5.2.1 正则表达式提取器(关联)
- 六、结果报告
- 监视器
- 6.1 聚合报告
- 6.2 察看结果树
- 6.3 用表格察看结果
- 七、功能拓展
- 7.1 方法一:把jar包加入到classpath
- 7.2 方法二:把jar包放到lib/ext下
- 7.3 方法三:把jar包放到自定义目录下
- 八、问题
- 8.1 Http请求响应内容中文乱码
- 第一种方法:配置内容编码设置
- 第二种方法:BeanShell后置处理程序
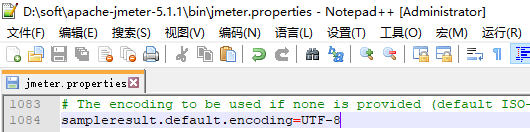
- 第三种方法:配置jmeter.properties文件
环境准备
- 首先需要安装JDK,具体参照安装配置JDK
- jmeter软件最新下载地址,本例内容基于 jmeter 5.1.1 版本开展
- 修改jmeter.properties文件配置:#sampleresult.default.encoding=ISO-8859-1 改为sampleresult.default.encoding=UTF-8
- Http接口信息如下(本篇文章所有例子都是基于此接口信息,可用mock模拟此接口)
POST:
URL:http://127.0.0.1:9999/postts
Content-Type: application/json
入参:
{
"usename": "test",
"password" : "test"
}
返回值:"success":"true"
GET:
URL:http://127.0.0.1:9999/geturl
返回值:"success": "get"
一、常用功能图
二、功能配置
2.1 jmeter修改为中文界面
操作步骤:
- 临时修改:jmeter界面>>Options>>Choose Language>>Chinese(Simplified)
- 永久修改:修改jmeter.properties文件配置:#language=en 改为language=zh_CN
2.2 配置元件
2.2.1 Http信息头管理
操作步骤:
- 选择测试计划>>右键>>添加>>配置元件>>Http信息头管理
- 输入名称 Content-Type 值输入 application/json
注:一般json形式的传参方式需要按此配置信息头

2.2.2 Http请求默认值
应用场景:有两个环境测试环境ip=192.168.1.188,预生产环境:ip=192.168.1.88,用Http请求默认值配置ip,可轻松实现两个环境之间的切换
操作步骤:
- 选择测试计划>>右键>>添加>>配置元件>>Http请求默认值
- 设置如下
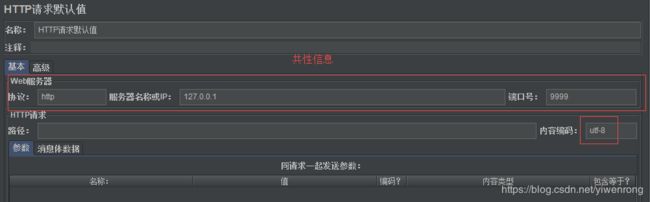
3. 如上图在Http请求默认值设置共性信息,在http请求取样器无需再设置ip,请求会调用默认值
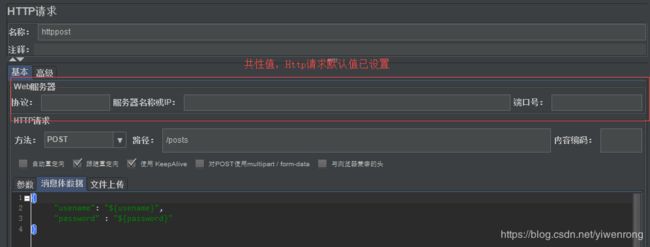
说明:Http请求默认值说白了就是统一设置Http请求属性参数,如协议、服务器名称或ip、端口号等的默认值,当Http请求属性参数不填的情况下调用默认值,但是如果Http请求对这些参数有定义,那么优先使用自定义参数
2.3 取样器
2.3.1 调试取样器
操作步骤:
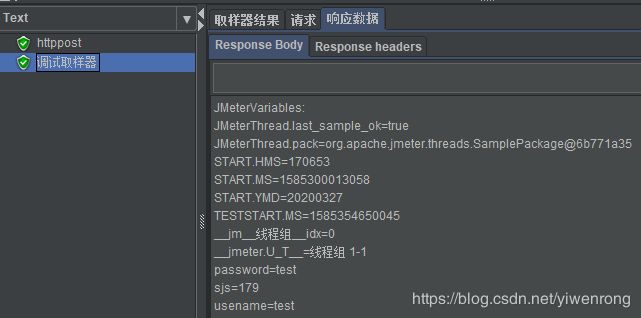
选择线程组>>右键>>添加>>取样器>>调试取样器>>设置打印jmeter变量:

说明:可通过设置查看jmeter属性、变量以及系统属性等值,一般与监听器>>察看结果树配合使用
查看结果树值:如打印(变量)password=(值)test
2.4 逻辑控制器
2.4.1 如果(if)控制器
操作步骤:
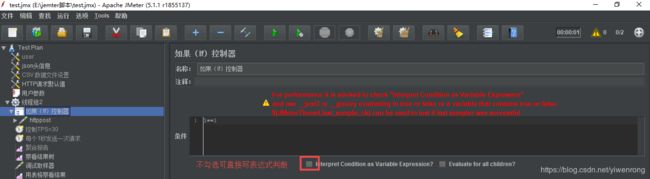
- 选择线程组>>右键>>添加>>逻辑控制器>>如果(if)控制器
- 不勾选“interpret condition as variable expression”,输入 1==1
- 执行之后结果为true,必定会执行如果控制器下的http请求
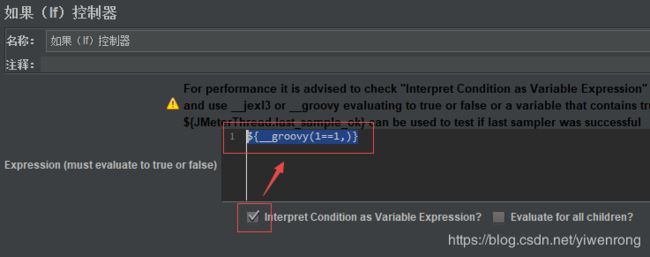
说明:如上图,不勾选“interpret condition as variable expression”,那就可以直接用表达式 1== 1判断为true执行http请求,如勾选“interpret condition as variable expression”,不能直接用表达式1==1,需借助函数助手_jexl3和_groovy函数计算为true/false,如果为true才可以执行http请求,如下图
三、参数化
3.1 CSV数据文件设置
前提条件:如D盘有文件cs.txt内容如下
#第一个参数,第二个参数,与CSV数据文件设置的分隔符设置相关
test,test
user,pwd
操作步骤:
- 选择测试计划>>右键>>添加>>配置元件>>CSV数据文件设置
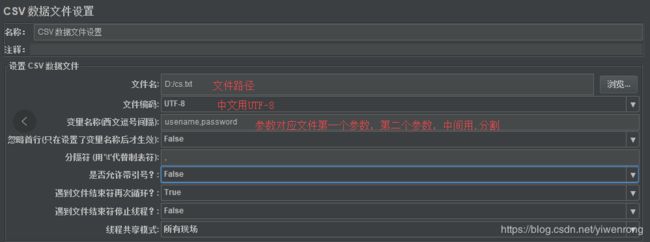
说明:
- CSV数据文件支持 .csv,.dat ,.txt为后缀的文件
- 如上图配置,如果设置线程组1个线程循环3次,则结果如下:
#参数调用格式${usename},${password}
线程组 1-1 内容:
password=test
usename=test
线程组 1-2 内容:
password=pwd
usename=user
线程组 1-3 内容:
password=test
usename=test
3.2 用户定义变量
操作步骤:
- 选择测试计划>>右键>>添加>>配置元件>>用户定义的变量
- 输入名称、值、描述
- 调用变量格式${名称}:如 ${usename}

3.3 函数助手
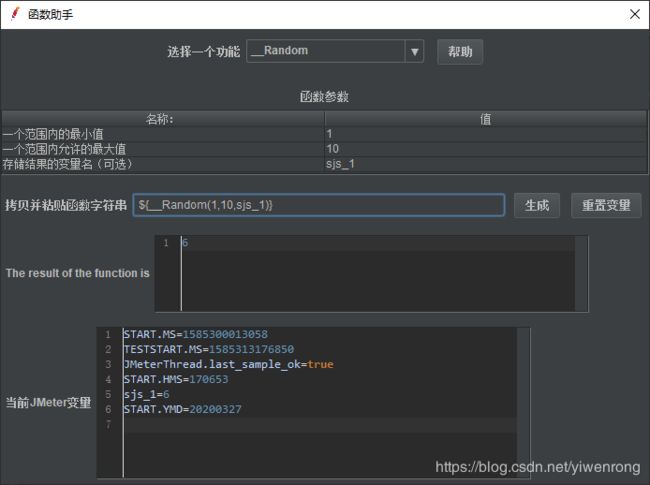
3.3.1 Random(随机数)
操作步骤:
- Tools>>函数助手对话框
- 设置随机数 1<=sjs_1<=10,点击生成
- 调用变量 ${__Random(1,10,sjs_1)}
注:设置随机数:100<=sjs<=200,直接调用变量:${__Random(100,200,sjs)}
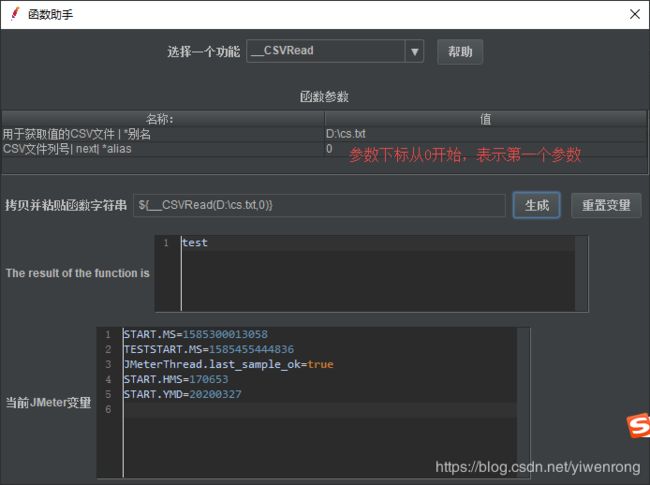
3.3.2 __CSVRead
操作步骤:
- Tools>>函数助手对话框
- 输入文件绝对路径,输入参数下标,0表示第一个参数,点击生成
- 调用变量:${__CSVRead(D:\cs.txt,0)}
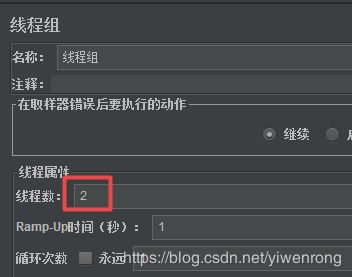
3.4 用户参数
前提条件:设置线程数=2,循环测试=1
操作步骤:
- 选择测试计划>>右键>>添加>>前置处理器>>用户参数
- 输入名称、用户值
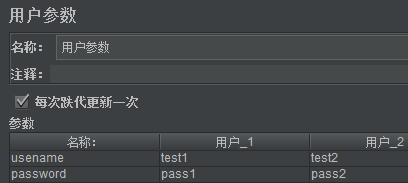
用户参数说明:
名称:参数名称
用户:参数值
每次迭代更新一次:如果有多个线程(线程组线程数设置大于1)使用变量时勾选,不同的线程用不同的值,如果不勾选,所有线程用的是同一个值
参数:
1.可以定义多个参数,每个参数可以赋多个值
2.在用户值中,可以使用变量,如使用CSV函数 ${__CSVRead(D:\cs.txt,0)},在勾选每次迭代更新一次时,每一个线程都会生成新的值。
- 在http请求调用变量格式:如${usename}
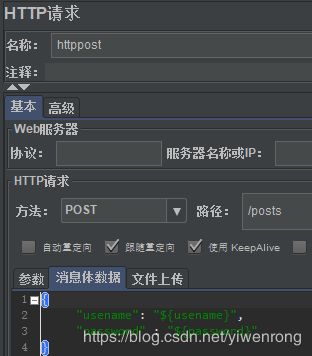
- 结果:
#线程1 内容:
POST data:
{
"usename": "test1",
"password" : "pass1"
}
#线程2 内容:
POST data:
{
"usename": "test2",
"password" : "pass2"
}
3.5 全局变量
应用场景:登录获取token信息(一次请求,setUP线程组),用于订单查询、购买、结账等(多次请求,线程组)操作
操作路径:新建一个setUP线程组,名称线程组1,自定义一个全局变量;新建一个普通线程组,名称:线程组2;线程组2调用线程1的全局变量
操作步骤:
- 选择测试计划>>右键>>添加>>线程(用户)>>Setup线程组
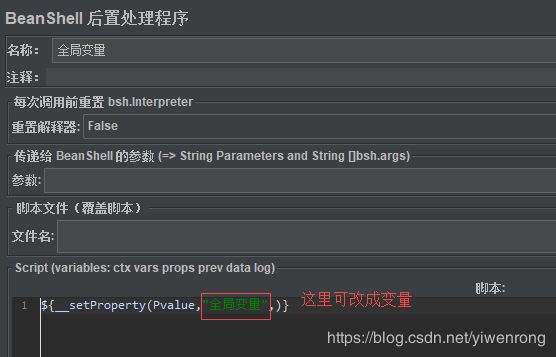
- 选择线程组>>右键>>添加>>后置处理器>>BeanShell后置处理程序
- 脚本输入 ${__setProperty(Pvalue,“全局变量”,)}
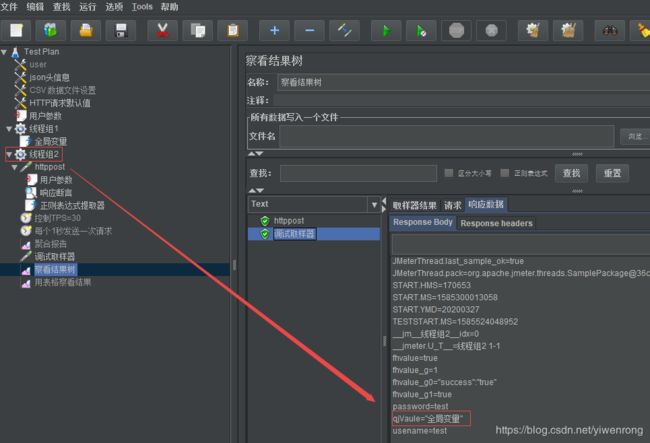
- 在线程组2调用全局变量: ${__property(Pvalue)}
结果:
四、模拟用户操作
4.1 用户访问
取样器
4.1.1 Http请求
应用场景:如访问百度
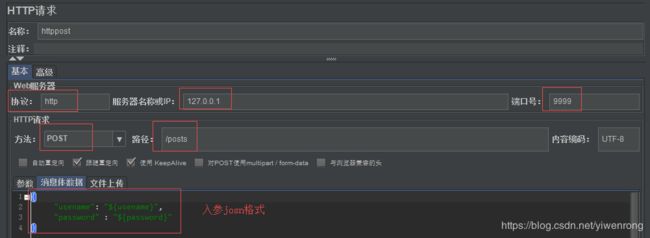
操作步骤:选择线程组>>右键>>添加>>取样器>>http请求
说明:
端口号: https协议默认端口:443;http协议端口号:80,端口号不填则默认80
参数:${usename},usename在用户定义变量已定义;因入参为json格式,因此需在消息体数据 填写入参,具体如下图
4.2 模拟多用户访问
线程组
4.2.1 Setup线程组
操作步骤:
选择测试计划>>右键>>添加>>线程(用户)>>Setup线程组
说明:
- 所有操作都在普通线程组前执行,
- 应用场景举例:
A、测试数据库操作功能时,用于执行打开数据库连接的操作。
B、测试用户购物功能时,用于执行用户的注册、登录等操作- 其他属性参照4.2.2 线程组(普通)说明
4.2.2 线程组(普通)
应用场景:N个用户日夜不停的访问百度
操作步骤:
选择测试计划>>右键>>添加>>线程(用户)>>线程组
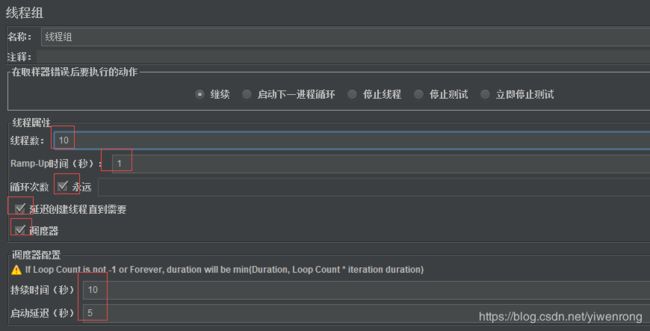
说明:
- 在取样器错误后要执行的动作
- 继续:忽略错误,继续执行;
- 启动下一进程循环: 忽略错误,线程当前循环终止,执行下一个循环;
- 停止线程:当前线程停止执行,不影响其他线程正常执行;
- 停止测试:整个测试会在所有当前正在执行的线程执行完毕后停止;
- 立即停止测试:整个测试会立即停止执行,当前正在执行的取样器可能会被中断;
这几个配置项控制了“当遇到错误的时候测试的执行策略”是否会继续执,一般默认“继续”
- 线程数
用户并发数,例如10个用户访问,则线程设置=10- Ramp-Up period(秒)
- 设置启动所有线程所需要的时间。如果选择了10个线程,并且ramp-up period是100秒,那么JMeter将使用100秒启动并运行10个线程。每个线程将在前一个线程启动后10(100/10)秒后启动。
- 当这个值设置的很小、线程数又设置的很大时,在刚开始执行时会对服务器产生很大的负荷
- 循环次数
可填写次数,如线程数=10,循环测试=5,聚合报告总样本=10*5=50,也可以勾选永远复选框,勾选之后请求一直发送- 持续时间
持续时间设置10秒,必须勾选循环测试复选框+调度复选框,只有这样可持续发送10秒钟请求- 启动延时
持续时间设置10秒,启动延迟时间设置5秒,必须勾选循环测试复选框+调度复选框+延迟创建线程直到需要复选框,只有这样,启动之后,延迟5秒钟,持续发送10秒钟请求
4.2.3 TearDown线程组
操作步骤:
选择测试计划>>右键>>添加>>线程(用户)>>TearDown线程组
说明:
1.所有操作都在普通线程组后执行
2.应用场景举例:
A、测试数据库操作功能时,用于执行关闭数据库连接的操作。
B、测试用户购物功能时,用于执行用户的退出等操作。
3.其他属性参照4.2.1.2 线程组(普通)说明
4.3 多用户访问控制
定时器
4.3.1 常数吞吐量定时器(控制TPS)
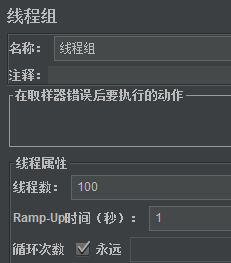
应用场景:用户每秒30的频率访问百度
前提条件:
在一个线程组下有一个http请求,线程组设置如下:
操作步骤:
- 选择要线程组>>右键>>添加>>定时器>>常数吞吐量定时器
- 输入自定义名称,目标吞吐量(TPS)输入 1800
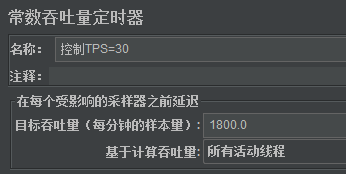
说明:目标吞吐量是按每分钟的样本量计算,所以实际值=30(TPS)*60=1800
- This thread only(只有此线程):控制每个线程的吞吐量,选择这种模式时,总的吞吐量为设置的target Throughput 乘以该线程的数量
- All active threads(所有活动的线程):设置的target Throughput 将分配在每个活跃线程上,每个活跃线程在上一次运行结束后等待合理的时间后再次运行。活跃线程指同一时刻同时运行的线程。
- All active threads in current thread group(当前线程组钟的所有活动线程):设置的target Throughput 将分配在当前线程组的每一个活跃线程上,当测试计划中只有一个线程组时,该选项和All active threads 选项的效果完全相同。
- All avtive threads(shared)(所有活动线程(共享)):与All active threads的选项基本相同。唯一区别是,每个活跃线程都会在所有活跃线程上一次运行结束后等待合理的时间后再次运行。
- All active threads in current thread group(shared)(当前线程组钟的所有活动线程(共享)):与All active threads in current thread group 基本相同,唯一的区别是,每个活跃线程都会在所有活跃线程的上一次运行结束后等待合理的时间后再次运行
聚合报告结果:
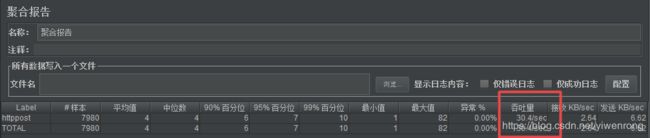
说明:如上图吞吐量(TPS)一直控制在30
4.3.2 固定时器(时间间隔)
应用场景:用户每隔一秒访问百度
操作步骤:
- 选择要线程组>>右键>>添加>>定时器>>固定时器
- 自定义设置Name,Teread Delay…输入 1000
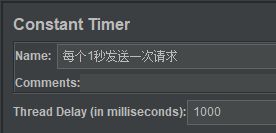
说明:单位毫秒,1000毫秒=1秒钟,如上设置,即可控制每一次http请求间隔1秒钟发送
五、关联断言
5.1 断言
5.1.1 响应断言
应用场景:判断其正确性,例如登录是否成功;
前提条件:入参正确,请求返回的正确返回值:“success”:“true”;
操作步骤:
- 选择Http请求>>右键>>添加>>断言>>响应断言
- 添加>>测试模式输入:“success”:“true”
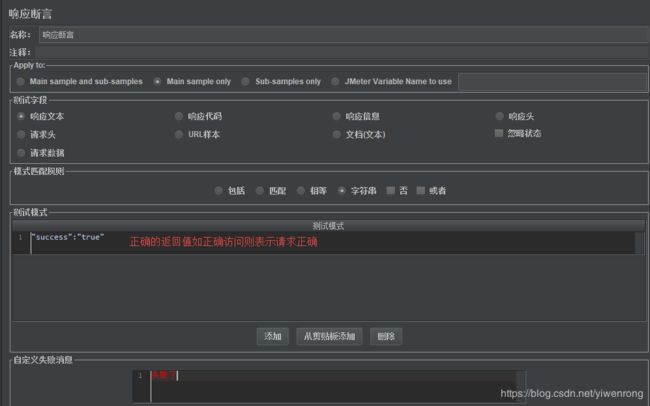
结果
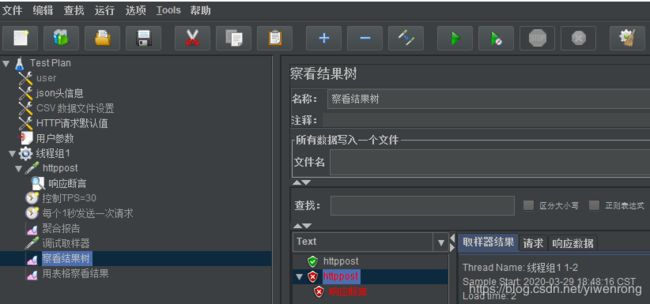
说明:如上图结果,其中一个请求响应返回"success":"true"与测试模式设置一致,则返回正常状态=200,察看结果树显示绿色,其中一个请求相应返回空,则返回异常状态=400,显示红色
5.2 后置处理器
5.2.1 正则表达式提取器(关联)
应用场景:下一个请求需要用到上一个请求的返回值,例如购买一件商品必须首先知道商品的价格;
前提条件:入参正确,请求返回的正确返回值:“success”:“true”;
操作步骤:
- 选择Http请求>>右键>>添加>>后置处理器->正则表达式提取器
- 输入引用名称:fhvalue;正则表达式:“success”:"(.*?)";模板: 1 1 1;匹配数字:1
- 参数调用${fhvalue},本例值为:true
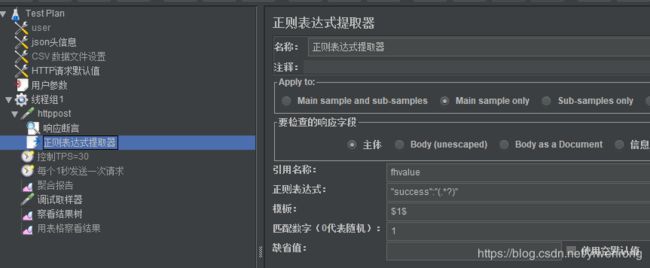
说明:
A.引用名称:下一个请求要引用的参数名称,如填写Atask,则可用${Atask}引用它。
B.正则表达式:
():括起来的部分就是要提取的。
.:匹配任何字符串。
+:一次或多次。
?:在找到第一个匹配项后停止。
B.模板:用$$引用起来,如果在正则表达式中有多个正则表达式,则可以是$2$$3$等等,表示解析到的第几个值给title。如:$1$表示解析到的第1个值
C.匹配数字:0代表随机取值,1代表全部取值,通常情况下填0
D.缺省值:如果参数没有取得到值,那默认给一个值让它取,我填的Error。
六、结果报告
监视器
6.1 聚合报告
操作步骤:
选择线程组>>右键>>添加>>监视器>>聚合报告
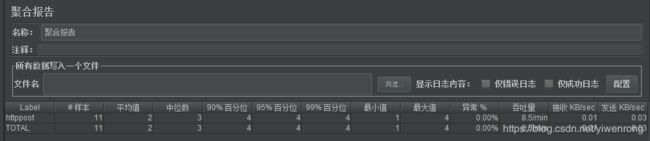
说明: 性能测试重要参考依据,关键指标信息描述如下:
Samples(样本) -- 本次场景中一共完成了多少个线程
Average(平均值) -- 平均响应时间(ms)
Median (中位数)-- 统计意义上面的响应时间的中值
90% Line(90%) -- 所有线程中90%的线程的响应时间都小于xx
95% Line(95%) -- 所有线程中95%的线程的响应时间都小于xx
99% Line(99%) -- 所有线程中99%的线程的响应时间都小于xx
Min (最小值)-- 最小响应时间
Max(最大值) -- 最大响应时间
Error (异常%)-- 出错率
Troughput(吞吐量) -- 吞吐量
Received KB/sec(接收) -- 以接收流量做衡量的吞吐量
Sent KB/sec(发送) -- 以发送流量做衡量的吞吐量
6.2 察看结果树
操作步骤:选择线程组>>右键>>添加>>监视器>>察看结果树
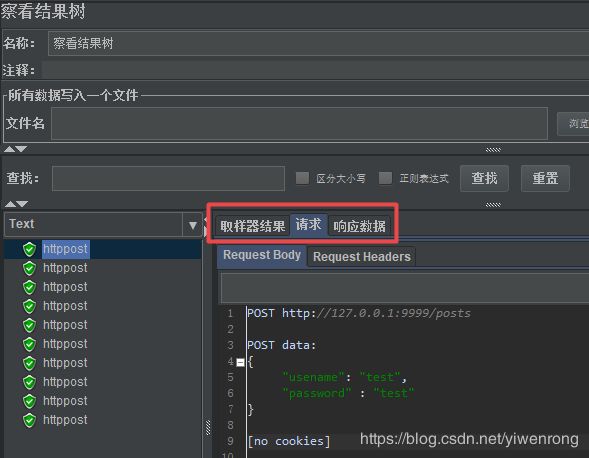
说明:一般作为调试使用,例如查看http的请求动作与响应结果,验证其是否正确
6.3 用表格察看结果
操作步骤:选择线程组>>右键>>添加>>监视器>>用表格察看结果
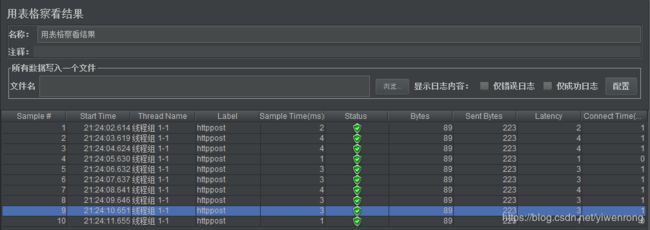
说明:一般作为调试使用,例如查看http的请求情况,按线程统计请求时间、状态、流量等情况
七、功能拓展
应用场景:传一个字母按时间生成一个流水号,例如当前时间是:2020年03月30日12点45分18秒,传一个字母A,生成流水A20200330124518
前提条件:准备一个可生成流水号的jar包:serialNum.jar,具体生成方法点击此
7.1 方法一:把jar包加入到classpath
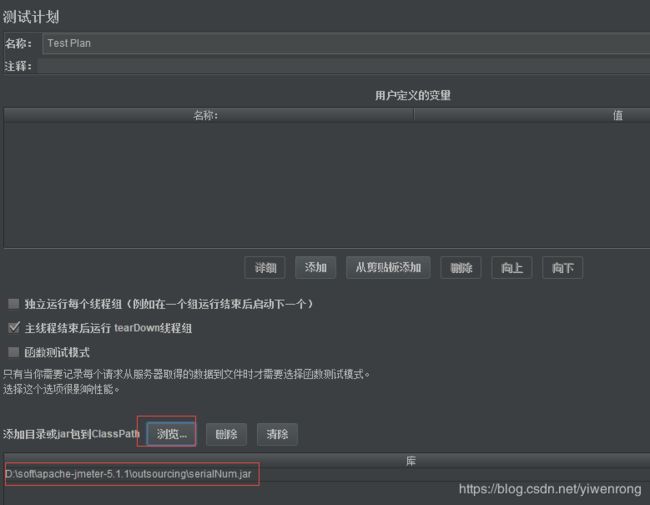
操作步骤:
1.选择测试计划>>浏览>>选择serialNum.jar(文件可在任意目录下),如图
2.新建一个BeanShell,选择线程组>>右键>>添加>>采样器>>BeanShell取样器,输入脚本:
#import 包名1.包名N.java文件名
import serialNum.SetserialNum;
#实例化
SetserialNum serial = new SetserialNum();
#调用生产流水方法
String seristrNum = serial.setNum("A");
#参数赋值
vars.put("seristrNum", seristrNum);
#打印日志
log.info(seristrNum)
- 选项>>勾选日志查看复选框>>运行>>结果如下图
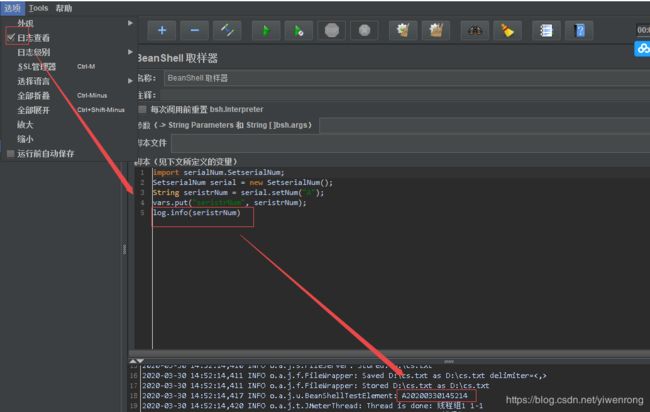
说明:上图标红部分的操作是为了打印日志,前置处理/后置处理器也可以添加BeanShell处理程序,可根据实际情况选择使用
7.2 方法二:把jar包放到lib/ext下
操作步骤:
- 把serialNum.jar文件放入jmeter lib/ext文件目录下
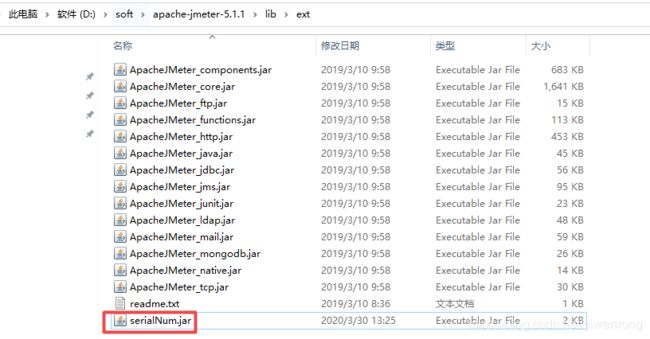
- 重启jmeter
- 参照方法一第2,3步
7.3 方法三:把jar包放到自定义目录下
说明:如果是前面两种方式,肯能你会发现,不方便管理自己的jar包,第三种方式易于管理自己的jar包,也防止误删
操作步骤:
- 在jmeter的bin同级目录下创建文件夹outsourcing,把我们的erialNum.jar包放到这个文件夹中

- 在bin目录下的jmeter.properties文件中,查找dependencies,修改内容如下
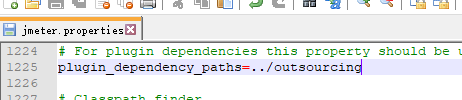
- 保存后,重启jmeter
- 参照方法一第2,3步
八、问题
8.1 Http请求响应内容中文乱码
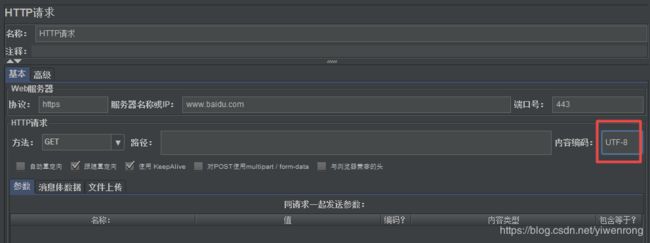
第一种方法:配置内容编码设置
内容编码设置:UTF-8
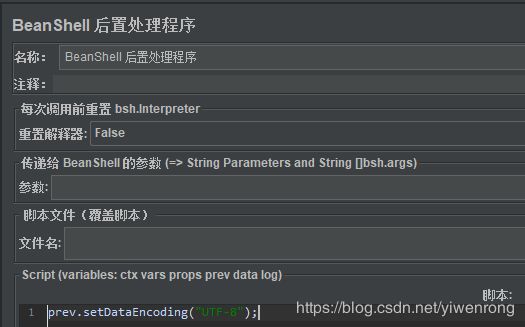
第二种方法:BeanShell后置处理程序
操作步骤:
- 选择线程组>>右键>>添加>>后置处理器>>BeanShell后置处理程序
- BeanShell后置处理程序输入脚本:prev.setDataEncoding(“UTF-8”);
第三种方法:配置jmeter.properties文件
操作步骤:修改配置jmeter.properties文件:#sampleresult.default.encoding=ISO-8859-1 改为sampleresult.default.encoding=UTF-8