Java多线程爬虫爬取京东商品信息
前言
网络爬虫,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。爬虫可以通过模拟浏览器访问网页,从而获取数据,一般网页里会有很多个URL,爬虫可以访问这些URL到达其他网页,相当于形成了一种数据结构——图,我们通过广度优先搜索和深度优先搜索的方式来遍历这个图,从而做到不断爬取数据的目的。最近准备做一个电商网站,商品的原型就打算从一些电商网站上爬取,这里使用了HttpClient和Jsoup实现了一个简答的爬取商品的demo,采用了多线程的方式,并将爬取的数据持久化到了数据库。
项目环境搭建
整体使用技术
我IDE使用了Spring Tool Suite(sts),你也可以使用Eclipse或者是IDEA,安利使用IDEA,真的好用,谁用谁知道。
整个项目使用Maven进行构建吗,使用Springboot进行自动装配,使用HttpClient对网页进行抓取,Jsoup对网页进行解析,数据库连接池使用Druild,还使用了工具类Guava和Commons.lang3。
项目结构
在sts里面新建一个maven工程,创建如下的包 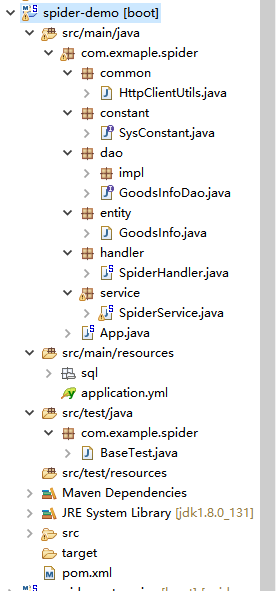
- common 一些通用工具类
- constant 系统常量
- dao 数据库访问层
- service 服务层
- handler 调度控制层
- entity 实体层
这样分层的意义是使得项目结构层次清晰,每层都有着其对应的职责,便于扩展和维护
pom文件
这里使用maven进行构建,还没有了解maven的童鞋自行去了解,使用maven的好处是不用自己导入jar包和完整的生命周期控制,注意,使用阿里云的镜像速度回加快很多。项目的pom.xml文件如下
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.exmaplegroupId>
<artifactId>spider-demoartifactId>
<version>0.0.1-SNAPSHOTversion>
<packaging>jarpackaging>
<name>spider-demoname>
<url>http://maven.apache.orgurl>
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<java.version>1.8java.version>
<jsoup.version>1.10.3jsoup.version>
<guava.version>22.0guava.version>
<lang3.version>3.6lang3.version>
<mysql.version>5.1.42mysql.version>
<druid.version>1.1.0druid.version>
properties>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>1.5.4.RELEASEversion>
<relativePath />
parent>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jdbcartifactId>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druid-spring-boot-starterartifactId>
<version>${druid.version}version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>org.apache.httpcomponentsgroupId>
<artifactId>httpclientartifactId>
dependency>
<dependency>
<groupId>org.jsoupgroupId>
<artifactId>jsoupartifactId>
<version>${jsoup.version}version>
dependency>
<dependency>
<groupId>com.google.guavagroupId>
<artifactId>guavaartifactId>
<version>${guava.version}version>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-lang3artifactId>
<version>${lang3.version}version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.34version>
dependency>
dependencies>
<build>
<finalName>spider-demofinalName>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<configuration>
<source>${java.version}source>
<target>${java.version}target>
configuration>
plugin>
plugins>
build>
project>application.yml文件
spring boot的配置文件有两种形式,放在src/main/resources目录下,分别是application.yml和application.properties
这里为了配置更加简洁,使用了application.yml作为我们的配置文件
application.yml
# mysql
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/spider?useUnicode=true&characterEncoding=UTF-8&&useSSL=true
username: root
password: 123这里可以在url,username和pssword里换成自己环境对应的配置
sql文件
这里我们创建了一个数据库和一张表,以便后面将商品信息持久化到数据库
db.sql
USE spider;
CREATE TABLE `goods_info` (
`id` INT(11) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`goods_id` VARCHAR(255) NOT NULL COMMENT '商品ID',
`goods_name` VARCHAR(255) NOT NULL COMMENT '商品名称',
`img_url` VARCHAR(255) NOT NULL COMMENT '商品图片地址',
`goods_price` VARCHAR(255) NOT NULL COMMENT '商品标价',
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8 COMMENT='商品信息表';网页的分析
网址URL的分析
我们要爬取的网页的URL的基本地址是https://search.jd.com/Search
我们打开这个网页,在搜索框内搜索零食,我们看一下我们的浏览器的地址栏的URL的变化,发现浏览器的地址栏变成了https://search.jd.com/Search?keyword=零食&enc=utf-8&wq=零食&pvid=2c636c9dc26c4e6e88e0dea0357b81a3
我们就可以对参数进行分析,keyword和wq应该是代表要搜索的关键字,enc代表的编码,pvid不知道是什么,我们把这个参数去掉看能不能访问https://search.jd.com/Search?keyword=零食&enc=utf-8&wq=零食,发现这个URL也是可以正常访问到这个网址的,那么我们就可以暂时忽略这个参数,参数就设置就设置keyword,wq和enc
这里我们要设置的参数就是
- keyword 零食
- wq 零食
- enc utf-8
网页内容的分析
我们打开我们要爬取数据的页面 
使用浏览器-检查元素 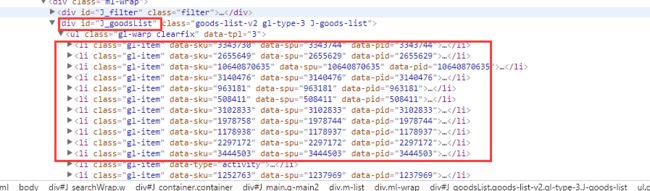
通过查看源码,我们发现JD的商品列表放在id是J_goodsList的div下的的class是gl-warp clearfix的ul标签下的class是gl-item的li标签下
再分别审查各个元素,我们发现
- li标签的data-sku的属性值就是商品的ID
- li标签下的class为p-name p-name-type-2的em的值就是商品的名称
- li标签下的class为p-price的strong标签下的i标签的值是商品的价格
- li标签下的class为p-img的img标签的src值就是商品的图片URL
对网页进行了分析以后,我们就可以通过对DOM结点的选择来筛选我们想要的数据了
代码的编写
这里我们封装了HttpClientUtils作为我们的工具类,以便以后使用
HttpClientUtils工具类
HttpClient.java
package com.exmaple.spider.common;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.http.HttpEntity;
import org.apache.http.NameValuePair;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.entity.ContentType;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.exmaple.spider.constant.SysConstant;
/**
* HttpClient工具类
*
* @author ZGJ
* @date 2017年7月14日
*/
public class HttpClientUtils {
private final static Logger logger = LoggerFactory.getLogger(HttpClientUtils.class);
private final static String GET_METHOD = "GET";
private final static String POST_METHOD = "POST";
/**
* GET请求
*
* @param url
* 请求url
* @param headers
* 头部
* @param params
* 参数
* @return
*/
public static String sendGet(String url, Map headers, Map params) {
// 创建HttpClient对象
CloseableHttpClient client = HttpClients.createDefault();
StringBuilder reqUrl = new StringBuilder(url);
String result = "";
/*
* 设置param参数
*/
if (params != null && params.size() > 0) {
reqUrl.append("?");
for (Entry param : params.entrySet()) {
reqUrl.append(param.getKey() + "=" + param.getValue() + "&");
}
url = reqUrl.subSequence(0, reqUrl.length() - 1).toString();
}
logger.debug("[url:" + url + ",method:" + GET_METHOD + "]");
HttpGet httpGet = new HttpGet(url);
/**
* 设置头部
*/
logger.debug("Header\n");
if (headers != null && headers.size() > 0) {
for (Entry header : headers.entrySet()) {
httpGet.addHeader(header.getKey(), header.getValue());
logger.debug(header.getKey() + " : " + header.getValue());
}
}
CloseableHttpResponse response = null;
try {
response = client.execute(httpGet);
/**
* 请求成功
*/
if (response.getStatusLine().getStatusCode() == 200) {
HttpEntity entity = response.getEntity();
result = EntityUtils.toString(entity, SysConstant.DEFAULT_CHARSET);
}
} catch (IOException e) {
logger.error("网络请求出错,请检查原因");
} finally {
// 关闭资源
try {
if (response != null) {
response.close();
}
client.close();
} catch (IOException e) {
logger.error("网络关闭错误错,请检查原因");
}
}
return result;
}
/**
* POST请求
*
* @param url
* 请求url
* @param headers
* 头部
* @param params
* 参数
* @return
*/
public static String sendPost(String url, Map headers, Map params) {
CloseableHttpClient client = HttpClients.createDefault();
String result = "";
HttpPost httpPost = new HttpPost(url);
/**
* 设置参数
*/
if (params != null && params.size() > 0) {
List paramList = new ArrayList<>();
for (Entry param : params.entrySet()) {
paramList.add(new BasicNameValuePair(param.getKey(), param.getValue()));
}
logger.debug("[url: " + url + ",method: " + POST_METHOD + "]");
// 模拟表单提交
try {
UrlEncodedFormEntity entity = new UrlEncodedFormEntity(paramList, SysConstant.DEFAULT_CHARSET);
httpPost.setEntity(entity);
} catch (UnsupportedEncodingException e) {
logger.error("不支持的编码");
}
/**
* 设置头部
*/
if (headers != null && headers.size() > 0) {
logger.debug("Header\n");
if (headers != null && headers.size() > 0) {
for (Entry header : headers.entrySet()) {
httpPost.addHeader(header.getKey(), header.getValue());
logger.debug(header.getKey() + " : " + header.getValue());
}
}
}
CloseableHttpResponse response = null;
try {
response = client.execute(httpPost);
HttpEntity entity = response.getEntity();
result = EntityUtils.toString(entity, SysConstant.DEFAULT_CHARSET);
} catch (IOException e) {
logger.error("网络请求出错,请检查原因");
} finally {
try {
if (response != null) {
response.close();
}
client.close();
} catch (IOException e) {
logger.error("网络关闭错误");
}
}
}
return result;
}
/**
* post请求发送json
* @param url
* @param json
* @param headers
* @return
*/
public static String senPostJson(String url, String json, Map headers) {
CloseableHttpClient client = HttpClients.createDefault();
String result = "";
HttpPost httpPost = new HttpPost(url);
StringEntity stringEntity = new StringEntity(json, ContentType.APPLICATION_JSON);
httpPost.setEntity(stringEntity);
logger.debug("[url: " + url + ",method: " + POST_METHOD + ", json: " + json + "]");
/**
* 设置头部
*/
if (headers != null && headers.size() > 0) {
logger.debug("Header\n");
if (headers != null && headers.size() > 0) {
for (Entry header : headers.entrySet()) {
httpPost.addHeader(header.getKey(), header.getValue());
logger.debug(header.getKey() + " : " + header.getValue());
}
}
}
CloseableHttpResponse response = null;
try {
response = client.execute(httpPost);
HttpEntity entity = response.getEntity();
result = EntityUtils.toString(entity, SysConstant.DEFAULT_CHARSET);
} catch (IOException e) {
logger.error("网络请求出错,请检查原因");
} finally {
try {
if (response != null) {
response.close();
}
client.close();
} catch (IOException e) {
logger.error("网络关闭错误");
}
}
return result;
}
} SyConstant.java 系统常量
SysConstant.java
package com.exmaple.spider.constant;
/**
* 系统全局常量
* @author ZGJ
* @date 2017年7月15日
*/
public interface SysConstant {
/**
* 系统默认字符集
*/
String DEFAULT_CHARSET = "utf-8";
/**
* 需要爬取的网站
*/
String BASE_URL = "https://search.jd.com/Search";
interface Header {
String ACCEPT = "Accept";
String ACCEPT_ENCODING = "Accept-Encoding";
String ACCEPT_LANGUAGE = "Accept-Language";
String CACHE_CONTROL = "Cache-Controle";
String COOKIE = "Cookie";
String HOST = "Host";
String PROXY_CONNECTION = "Proxy-Connection";
String REFERER = "Referer";
String USER_AGENT = "User-Agent";
}
/**
* 默认日期格式
*/
String DEFAULT_DATE_FORMAT = "yyy-MM-dd HH:mm:ss";
}
GoodsInfo 商品信息
GoodsInfo.java
package com.exmaple.spider.entity;
public class GoodsInfo {
private Integer id;
private String goodsId;
private String goodsName;
private String imgUrl;
private String goodsPrice;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getGoodsId() {
return goodsId;
}
public void setGoodsId(String goodsId) {
this.goodsId = goodsId;
}
public String getGoodsName() {
return goodsName;
}
public void setGoodsName(String goodsName) {
this.goodsName = goodsName;
}
public String getImgUrl() {
return imgUrl;
}
public void setImgUrl(String imgUrl) {
this.imgUrl = imgUrl;
}
public String getGoodsPrice() {
return goodsPrice;
}
public void setGoodsPrice(String goodsPrice) {
this.goodsPrice = goodsPrice;
}
public GoodsInfo(String goodsId, String goodsName, String imgUrl, String goodsPrice) {
super();
this.goodsId = goodsId;
this.goodsName = goodsName;
this.imgUrl = imgUrl;
this.goodsPrice = goodsPrice;
}
}GoodsInfoDao 商品信息Dao层
因为这里仅仅涉及到把商品信息写入到数据库比较简单的操作,并没有使用MyBatis或者Hibernate框架,只是使用了Spring的JdbcTemplate对数据进行插入操作
GoodsInfoDao.java
package com.exmaple.spider.dao;
import java.util.List;
import com.exmaple.spider.entity.GoodsInfo;
/**
* 商品Dao层
* @author ZGJ
* @date 2017年7月15日
*/
public interface GoodsInfoDao {
/**
* 插入商品信息
* @param infos
*/
void saveBatch(List infos);
} GoodsInfoDaoImpl.java
package com.exmaple.spider.dao.impl;
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Repository;
import com.exmaple.spider.dao.GoodsInfoDao;
import com.exmaple.spider.entity.GoodsInfo;
@Repository
public class GoodsInfoDaoImpl implements GoodsInfoDao {
@Autowired
private JdbcTemplate jdbcTemplate;
@Override
public void saveBatch(List infos) {
String sql = "REPLACE INTO goods_info(" + "goods_id," + "goods_name," + "goods_price," + "img_url) "
+ "VALUES(?,?,?,?)";
for(GoodsInfo info : infos) {
jdbcTemplate.update(sql, info.getGoodsId(), info.getGoodsName(), info.getGoodsPrice(), info.getImgUrl());
}
}
} 商品的Dao层实现了向数据库里插入商品信息,使用JdbcTemplate和占位符的方式设置sql语句
SpiderService 爬虫服务层
SpiderService.java
package com.exmaple.spider.service;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.commons.lang3.StringUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.alibaba.fastjson.JSON;
import com.exmaple.spider.common.HttpClientUtils;
import com.exmaple.spider.constant.SysConstant;
import com.exmaple.spider.dao.GoodsInfoDao;
import com.exmaple.spider.entity.GoodsInfo;
import com.google.common.collect.Lists;
@Service
public class SpiderService {
private static Logger logger = LoggerFactory.getLogger(SpiderService.class);
@Autowired
private GoodsInfoDao goodsInfoDao;
private static String HTTPS_PROTOCOL = "https:";
public void spiderData(String url, Map params) {
String html = HttpClientUtils.sendGet(url, null, params);
if(!StringUtils.isBlank(html)) {
List goodsInfos =parseHtml(html);
goodsInfoDao.saveBatch(goodsInfos);
}
}
/**
* 解析html
* @param html
*/
private List parseHtml(String html) {
//商品集合
List goods = Lists.newArrayList();
/**
* 获取dom并解析
*/
Document document = Jsoup.parse(html);
Elements elements = document.
select("ul[class=gl-warp clearfix]").select("li[class=gl-item]");
int index = 0;
for(Element element : elements) {
String goodsId = element.attr("data-sku");
String goodsName = element.select("div[class=p-name p-name-type-2]").select("em").text();
String goodsPrice = element.select("div[class=p-price]").select("strong").select("i").text();
String imgUrl = HTTPS_PROTOCOL + element.select("div[class=p-img]").select("a").select("img").attr("src");
GoodsInfo goodsInfo = new GoodsInfo(goodsId, goodsName, imgUrl, goodsPrice);
goods.add(goodsInfo);
String jsonStr = JSON.toJSONString(goodsInfo);
logger.info("成功爬取【" + goodsName + "】的基本信息 ");
logger.info(jsonStr);
if(index ++ == 9) {
break;
}
}
return goods;
}
} Service层通过使用HttpClientUtils模拟浏览器访问页面,然后再使用Jsoup对页面进行解析,Jsoup的使用和Jquery的DOM结点选取基本相似,可以看作是java版的Jquery,如果写过Jquery的人基本上就可以看出是什么意思。
每抓取一条信息就会打印一次记录,而且使用fastjson将对象转换成json字符串并输出
在写测试代码的时候发现,发现爬取的数据只有前10条是完整的,后面的爬取的有些是不完整的,按道理来说是对于整个页面都是通用的,就是不知道为什么只有前面才是完整的,排查了很久没用发现原因,这里就只选择了前面的10条作为要爬取的数据
我们了解到,我们要爬取数据前要分析我们要爬取的数据有哪些,再分析网友的结构,然后对网页进行解析,选取对应的DOM或者使用正则表达式筛选,思路首先要清晰,有了思路之后剩下的也只是把你的思路翻译成代码而已了。
SpiderHandler 爬虫调度处理器
SpiderHandler.java
package com.exmaple.spider.handler;
import java.util.Date;
import java.util.Map;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import org.apache.commons.lang3.time.FastDateFormat;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import com.exmaple.spider.constant.SysConstant;
import com.exmaple.spider.service.SpiderService;
import com.google.common.collect.Maps;
/**
* 爬虫调度处理器
* @author ZGJ
* @date 2017年7月15日
*/
@Component
public class SpiderHandler {
@Autowired
private SpiderService spiderService;
private static final Logger logger = LoggerFactory.getLogger(SpiderHandler.class);
public void spiderData() {
logger.info("爬虫开始....");
Date startDate = new Date();
// 使用现线程池提交任务
ExecutorService executorService = Executors.newFixedThreadPool(5);
//引入countDownLatch进行线程同步,使主线程等待线程池的所有任务结束,便于计时
CountDownLatch countDownLatch = new CountDownLatch(100);
for(int i = 1; i < 201; i += 2) {
Map params = Maps.newHashMap();
params.put("keyword", "零食");
params.put("enc", "utf-8");
params.put("wc", "零食");
params.put("page", i + "");
executorService.submit(() -> {
spiderService.spiderData(SysConstant.BASE_URL, params);
countDownLatch.countDown();
});
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
executorService.shutdown();
Date endDate = new Date();
FastDateFormat fdf = FastDateFormat.getInstance(SysConstant.DEFAULT_DATE_FORMAT);
logger.info("爬虫结束....");
logger.info("[开始时间:" + fdf.format(startDate) + ",结束时间:" + fdf.format(endDate) + ",耗时:"
+ (endDate.getTime() - startDate.getTime()) + "ms]");
}
} SpiderHandelr作为一个爬虫服务调度处理器,这里采用了ExecutorService线程池创建了5个线程进行多线程爬取,我们通过翻页发现,翻页过后地址URL多了一个page参数,而且这个参数还只能是奇数才有效,也就是page为1,3,5,7……代表第1,2,3,4……页。这里就只爬了100页,每页10条数据,将page作为不同的参数传给不同的任务。
这里我想统计一下整个爬取任务所用的时间,假如不使用同步工具类的话,因为任务是分到线程池中去运行的,而主线程会继续执行下去,主线程和线程池中的线程是独立运行的,主线程会提前结束,所以就无法统计时间。
这里我们使用CountDownLatch同步工具类,它允许一个或多个线程一直等待,直到其他线程的操作执行完后再执行。也就是说可以让主线程等待线程池内的线程执行结束再继续执行,里面维护了一个计数器,开始的时候构造计数器的初始数量,每个线程执行结束的时候调用countdown()方法,计数器就减1,调用await()方法,假如计数器不为0就会阻塞,假如计数器为0了就可以继续往下执行
executorService.submit(() -> {
spiderService.spiderData(SysConstant.BASE_URL, params);
countDownLatch.countDown();
});这里使用了Java8中的lambda表达式替代了匿名内部类,详细的可以自行去了解
这里还可以根据自己的业务需求做一些代码的调整和优化,比如实现定时任务爬取等等
App.java Spring Boot启动类
App.java
package com.exmaple.spider;
import javax.annotation.PostConstruct;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import com.exmaple.spider.handler.SpiderHandler;
@SpringBootApplication
public class App {
@Autowired
private SpiderHandler spiderHandler;
public static void main(String[] args) throws Exception {
SpringApplication.run(App.class, args);
}
@PostConstruct
public void task() {
spiderHandler.spiderData();
}
}使用@PostConstruct注解会在spring容器实例化bean之前执行这个方法
运行结果
我们以Spring Boot App的方式运行App.java文件,得到的结果如下:
我们在看一下数据库内的信息 
发现数据库也有信息了,大功告成
总结
写一个简单的爬虫其实也不难,但是其中也有不少的知识点需要梳理和记忆,发现问题或者是错误,查google,查文档,一点点debug去调试,最终把问题一点点的解决,编程其实需要是解决问题的能力,这种的能力的锻炼需要我们去多写代码,写完了代码之后还要多思考,思考为什么要这样写?还有没有更好的实现方式?为什么会出问题?需要怎么解决?这才是一名优秀的程序员应该养成的习惯,共勉!
个人博客: http://blog.zgj12138.cn
简书: http://www.jianshu.com/u/276f89e5b3b1