聊聊量子计算机那些事
-
-
- 文章新地址
- 郑重声明
- 缘由
- 关于量子计算机的一些问题
- 科普视频
- 为什么要研究量子计算机?
- 算法复杂度
- 概率算法的一些思考
- 经典计算机VS量子计算机
- 量子计算机的基本知识
- 量子门操作
- 量子叠加态和传统叠加态
- 量子测量得出的概率和经典概率的区别与联系
- 经典概率性能 VS 量子叠加性能 VS 2的n次方个机器真并行
- 经典算法 VS 量子算法
- 量子编程
- 以grover 算法为例来show 量子计算机的性能
- 参考资料
-
文章新地址
csdn 对数学公式支持不好,影响阅读体验,请前往 bahutou.cn 。谢谢。
郑重声明
本文章中涉及到的数学知识和解释,均是结合量子计算机来的,并不代表数学本身的严谨表达。使用数学建立起的一套模型或者理论,其本身就有很多的应用场景,实例化(描述量子计算机)只是作为理解其理论的一个方面,研究数学本身需要屏蔽掉具体实现细节,研究其严谨性、完备性等。亦即研究数学本身的时候要从各种物理实体中抽象出本质和共性进行研究,你不能依赖于任何物理实体去研究数学理论,也不能完全脱离物理实体。理论和实践是相辅相成的,希望大家理解这层窗户纸。避免无意义的口水仗。
缘由
自己本身是计算机科学与技术专业毕业的学生,本身对“自动计算”这种可爱的装置就很有兴趣,看计算机发展史也能了解到除了现有的PC和Server(你懂我的意思,哈)这种计算机之外,还有一些基于机械原理的计算装置,可见各路大神对制造“自动计算”装置可谓情有独钟。一路看下来计算机发展史,也发自内心地对各位计算机大牛产生敬畏,是他们的努力工作才使我们现在的生活如此便捷(从大量重复的计算中解脱出来去做更有意义的事情)。现在看各大科技新闻网站上都报道一种新的计算装置—–量子计算机,说是运算速度超快,可以替代经典计算机,好像还弄出一个词叫量子霸权(请大家原谅一些新闻稿的小编们一心想弄个大新闻的心情)。作为一名专业的业余爱好者的我当然要看看是什么东东了。
tag:想了解计算机发展史的童鞋们,可以参考 Structured Computer Organization(Andrew S.Tanenba)计算机组成—结构化方法
第一章节的内容 和计算机硬件发展史
Structured Computer Organization(Andrew S.Tanenba)
计算机硬件发展史
关于量子计算机的一些问题
下面是我针对量子计算机的来龙去脉(why、what、how)提的一些问题,本文致力于说清楚这些问题,感觉有用请接着往下阅读,感觉没兴趣的请做自己感兴趣的事情。
- 研究量子计算机的原始动力是什么?有啥现实意义(指数性质的问题、P/NP/NPC/BQP[bounded error quantum polynomial time])
- 在你心目中,计算机是一个什么概念?(数据表示、抽象编码、层次结构)
- 使用通用经典计算机解决现实问题的一般步骤是怎样的?(析现实问题–进行建模–转换成计算机高级语言–编译、调试–用计算机运行–得出结果–转换成实际问题的解决方案)举例说明:1,使用经典计算机计算世界上第一个实数( 2–√ 2 )。2,使用概率算法计算数学上另一个和圆有关系的数字π。
算法好坏的评估依据是什么?(时间复杂度、空间复杂度)
tag:计算装置+优秀的算法才能解决问题。大家已经看到了太多的关于量子计算机比经典计算机牛逼的多的多,这种报道了。这种标题才能吸引眼球,提高各类小编的点击量。作为一名计算机科学爱好者的我看了各种报道后的第一个疑问是:量子计算机如何表示信息,处理信息?表示、处理信息上有啥新玩意?如果有新特性,那利用这些特性需要新的Idea吗?是在经典计算机思维上添加还是得另谋出路?
- 量子计算机如何表示信息?(qbit qbits、measurement)
- 和经典计算机表示信息的方式相比,多了那些特性?(superposition、entanglement)理解这些特性需要一些简单的线性代数思想(number–vector–space)。
- 如何描述多个qbits组成的系统?(circuit model、区分superposition和entanglement)
- 量子门是什么?具有什么作用?
- 为什么n个qbits可以表示2的n次方个信息,而且是同时表示的?如何利用这些信息?(测量、概率)
- 叠加特性+测量概率这种模型和经典概率系统组成的系统有何本质区别?举例:3个硬币随机抛,得出的信息系统 VS 3个qbits表示的信息系统。
- 量子叠加态 VS 普通叠加态?举例:多个声音混合 VS 多个qbit混合。将3个处于叠加态的量子系统,一个一个测量后放到一起组成的系统和原叠加态一样吗?
- 经典概率性能 VS 量子叠加性能 VS 2的n次方个机器真并行。以搜索为例子进行说明。
- 经典计算机架构 VS 量子计算机架构。
- 量子算法和经典算法有啥区别?可以说量子算法也是一种算法,完全由人类由人类可认知的语言描述出来的。只不过有些具有一定特性的部分可以利用叠加态来 进行加速。
- 我们知道了量子算法的套路和量子计算机之后,那接下来就是如何使用量子计算机能听懂的语言进行编程?量子编程环境?举例:IBM:Python–QASM–量子计算机。描述方法就是基于基态+++各种操作Gate,让其向正确答案方向偏转,最后测量结果。
- 好了,这个时候讲讲grover算法喽,先将基本思路,然后聊聊用量子编程语言实现并run一下。show下效果。
科普视频
看了上面的一系列问题,是不是有点紧张,别怕,先来看一段科普视频,以缓解一下紧张的小情绪。
看youtube要哦,什么?你不会!好吧,吓死宝宝了。
为什么要研究量子计算机?
计算机可以实现高速的计算,那是否意味着一切可计算的问题都能被计算机解决呐?我看未必,因为解决问题是人类的事情,人类需要把问题抽象—提出解决的方法—转换成具体的计算步骤—–得出结果—-还原成现实世界的具体操作。计算机仅仅是一个计算工具罢了,你让它咋计算它就咋计算☺☺☺。所以关键问题是人怎么提出有意义的问题,然后再提出解决步骤解决之。解决问题的步骤在计算机科学领域有一个专有行话—算法。针对某些问题,我们找到了比较好的算法,还有一些问题虽然有算法,但是算法不够好。那位同学举手了,是不是想问:“算法好不好我咋知道?” 。这个问题其实也好回答,能解决你的问题就是好算法。但是更通用的评判一个算法是好算法的方法是:随着待解决问题的规模逐渐变大时,你所需要的资源(运算次数、存储空间)成对数、线性、多项式增长。就是说,这个算法对解决统一类型的小问题、大问题都有效。我们大家对各类常见的增长模式有无思考?我从慢到快排个序:对数(log)、线性、多项式( n2、n3 n 2 、 n 3 etc )、指数( ex e x )、 n! n ! 。为表示诚意,还是来张图吧。
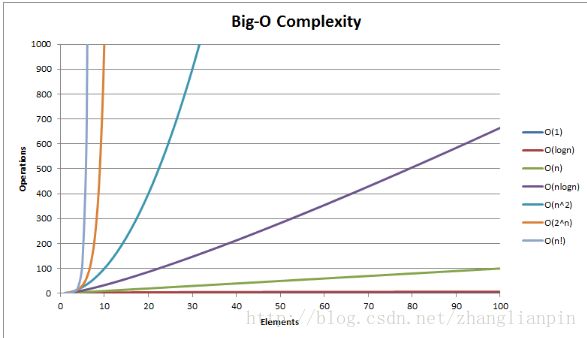
大家可以看看,随着问题规模的线性增长,算法运算次数的增长模型里最猛烈的是 n! n ! ,简直不可理喻,这货增长的实在是太快了,可以自己实际计算试试。 3!=6 3 ! = 6 ,但是 20!=2432902008176640000 20 ! = 2432902008176640000 。
大家注意看,和它突飞猛进的势头差不多的是 2n 2 n , 22=4 2 2 = 4 ,但是 220=1048576 2 20 = 1048576
关于指数增长模型,有一个很著名的故事:国际象棋和米粒的故事。故事就不讲了,上张图看看吧。

怎么样,还是挺震惊吧。
计算机专业的人分析算法好坏的方法叫算法复杂度分析,且用O(x)的形式表达算法复杂度,你可以理解为增长部分的关键部分。比如说算法的复杂度是 n2+n3 n 2 + n 3 ,表示成O(x)的形式当然是:O( n3 n 3 )了,因为随着n不断变大, n3 n 3 的增长量明显占主要地位, n2 n 2 虽然也有贡献,但和 n3 n 3 比起来就可以忽略了。算法分析你可以认为是微积分里, n→∞ n → ∞ 时的情况,是一种分析行为。
真是人比人得死,货比货得扔。
“等会,你问的问题是为什么研究量子计算,你却给我讲解算法复杂度,骗子。”哎,那位同学你先把枪放下,咱有话好好说。啰里啰嗦说了这么多,其实就是想引出算法复杂度的分类问题。直接上张图吧。
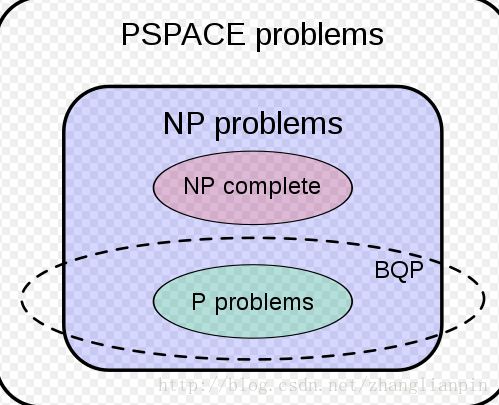
人类社会需要解决的问题千千万万,但是仔细分分类,也没几种。P、NP、NPC。P(polynomial)问题是复杂度是多项式一类的问题,比如 O(n2) O ( n 2 ) 、 O(n3) O ( n 3 ) 等等。NP(non polynomial)问题,这一类问题具有的特点就是:给一个答案,很容易就能验证正确与否,但是要找到正确答案却需要非多项式的时间复杂度(指数复杂度)。这一类问题大部分都为找最优解的问题,比如:走迷宫找最短路径、吃饭的时候如何安排座位等等问题。一旦一个问题目前能找到的算法的复杂度是指数级的,那就意味着问题规模稍微大一点,你的运算量就是巨大的,有可能全世界的计算机都凑到一块,几百年也计算不完。那基本上就认为这个问题不可解。关于N problem 、NP problem 问题请参考N问题、NP问题 。
了解了上述情况,我们知道了,有些问题不是你想解,想解就能解的。目前有好多问题是不可解的(指数级的复杂度),那要想解决这些“不可解”问题,有以下几种方法:
- 发明新的算法,把NP转化为P。
研制更快的计算装置。
在这样的背景下,研制像量子计算机这样的计算机就有了实际意义。传统的计算机新算法的发明速度到了瓶颈,传统的计算机计算速度提升也到了一定的瓶颈(量子隧穿效应)。
还是有图有真相,上张图。

而新研制的量子计算机再配上量子算法,在几个具体的问题领域表现出了较高的效率和活力。例子:shor算法可以将素因子分解问题从NP问题变成P问题。grover搜索算法把复杂度从N变成了 N−−√ N 。
以上,是针对“为什么要研究量子计算机?”这个问题的一些思索。
算法复杂度
算法复杂度问题前面也提到了,就是评价一个算法性能的一种方法。在业内评估一个算法的算法复杂度一般考量时间复杂度和空间复杂度这两个方面的内容。关于算法复杂度超出了本文要讨论的主题,请参考计算机数据结构和算法相关书籍。我推荐一本入门的数据结构与算法分析—C语言描述 Mark Allen Weiss。
概率算法的一些思考
算法是解决一些问题的思路,计算机算法是适合用计算机作为运算载体的一般算法。经典的计算机算法有好多,每一个都是凝聚了大量人的思想精华。我们这里举三个例子。
- 求 1+2 1 + 2
- 利用微积分思想 求 2–√ 2 的值
- 利用概率思想 求 π π 的值
上述算法的概述,大家一下就能看出来,第一个例子简单的连小学生都会做,后面两个例子都是求实数的例子。我们学过计算机的人都知道,经典计算机是离散思想的产物,要表示整数(自然数、浮点数)仅需要编码这个简单的思想就能搞定。其中自然数的编码使用的是补码的形式,浮点数的编码使用的是IEEE 754标准。实数呐,怎么表示实数?我们大家都知道实数是一个连续统的数域,要想表达和计算实数就要借助微积分思想或者类似的迭代思想。我们这里的求 1+2 1 + 2 使用了最朴素的自然数和编码思想。求 2–√ 2 使用微积分思想,求 π π 使用概率思想。主要说明两个问题,有了计算机并不能解决实际问题,还需要一些人的 Idea;也用来说明经典确定算法、基于微积分的逼近算法、和基于概率论的概率算法之间的区别和联系。
1+2 1 + 2 的例子我就不多说了。
下面直接说 2–√ 2 的例子。还是说说这个数的来历吧,大家应该都知道古希腊毕达哥拉斯(Pythagoras)学派吧,他们的价值观是数能统治一切,数是万能的。不过他们说的数主要是指有理数(自然数+分数)。其中一个弟子希帕索斯(Hippasus)发现了一个惊人的事实,一个正方形的对角线与其一边的长度是不可公度的(若正方形边长是1,则对角线的长不是一个有理数)这一不可公度性与毕氏学派“万物皆为数”(指有理数)的哲理大相径庭。这一发现使该学派领导人惶恐、恼怒,认为这将动摇他们在学术界的统治地位。希帕索斯因此被囚禁,受到百般折磨,最后竟遭到沉舟身亡的惩处。这也产生了数学上的第一次数学危机。解决这个危机,人类花了很长的时间,从而也说明了人类思维中确定的、离散的 占据核心的地位,你像连续的、曲的 这种概念着实不好理解和应用。好在,我们现在是站在巨人的肩膀上进步的,实数论—微积分可以解决上述危机。
咦,又扯远喽。求平方根的方法很多,比较知名的有newton method(牛顿迭代法)、二分法等等。这里具体就不做详细的分析和代码实现。有兴趣的可以自行实现,并分析不同算法的算法复杂度。
重点介绍概率算法实现求 π π 。先插一句,概率算法的基本特征和基于微积分思想的算法一样,都是无限逼近原理。都有一个共性:无穷性。下面就来看看咋用概率思想算 π π 。
先来张图:

一张图道出了所有的机密了吧,下面简要说明下基本步骤和思想。
- 在正方形中嵌入一个同心同径的圆。(如上图)
- 在正方形范围内产生随机数并记录总数(当然是用经典计算机模拟产生伪随机数喽)。
- 记录落在圆里的点数
- 令r =落在圆内的点数/落在正方形内的点数
- 则 π≈4r π ≈ 4 r
- 产生的随机数据量越大, π π 越精确。
下面是伪代码:
npoints = 10000
circle_count = 0
do j=1,npoints
generate 2 randomnumbers between 0 and 1
xcoordinate = random1
ycoordinate = random2
if(xcoordinate,ycoordinate) inside circle
then circle_count=circle_count+1
enddo
PI=4.0*circle_count/npoints通过上面的描述,我们可以看到影响计算 π π 精度的主要由两个方面:
- 产生的随机数总量
- 产生随机数的质量(是否是真正的随机数,越随机越好)。
经典计算机VS量子计算机
经典计算机发展了这么长的时间,已经发展出来了一套很完整的生态圈。我的意思是说有了很稳定的体系结构,有了自我扩展,解决实际问题的环境。用计算机解决实际问题一般分为分析现实问题——进行建模—–转换成计算机高级语言—-编译、调试——用计算机运行——得出结果——转换成实际问题的解决方案。这一套流程本身就可以使用经典计算机来完成,像高级语言编码、编译调试、运行等环节都是在经典计算机上运行的。这就是经典计算机生态圈的含义,一种半自动化的机器,前人的伟大发明,着实让人为之惊叹,为之着迷。
目前,量子计算机属于初期发展阶段。要想理解量子计算机的一些概念,最好的方法是和经典计算机做类比,以便更好地了解量子计算机。
来张经典计算机的层次结构图。

大家熟悉的冯诺依曼机:
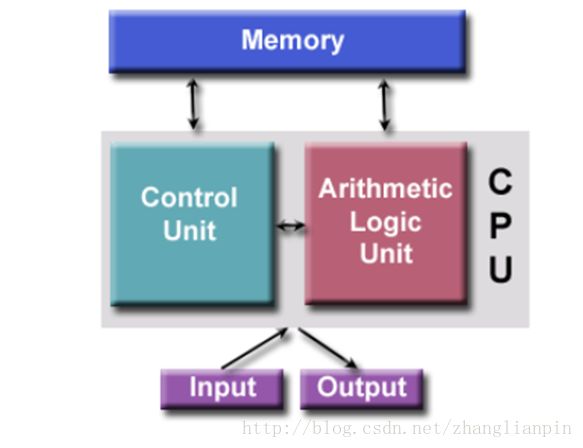
大家很明显可以看到,经典计算机体系结构是分层次设计开发的,越往上走越面向用户、也越简单,但同时牺牲了效率,用更容易利用牺牲了效率性。越往下走越面向电磁学理论、也越复杂,但同时掌握下层的知识可以更有效地利用硬件资源,但是这样不利于计算机工程化、推广化,也不利于用户使用计算机全身心解决现实世界的问题。
经典计算机里,我们现在解决实际问题的编程语言都很高级,类似于自然语言,这就需要一个翻译,将高级语言表达的含义变换为计算机能够理解的指令,然后计算机去执行指令。不过这一整套计算机体系理论基础是布尔代数,工程化是图灵机和冯诺依曼等各位大神的思想。因此,这套体系发展到现在是一脉相承的。举例来说,他的理论基础和数学模型以及后来的工程化实现都在我们基础教育的范畴内。计算没有接受过系统的计算机知识培训的人在第一次接受这些概念时也会觉着比较自然。而且经典计算机的高级语言,确实屏蔽了很多计算机物理实现细节,我们使用的计算机实际上是经过抽象的虚拟机。你像高级语言里面的加法、乘法、循环等等概念和我们解决实际问题的思路和数学表达方法基本一致。
说了这么多,我想大家也知道我想表达什么了,现在的计算机这么好用,是经过了几代人努力的结果,我们是站在巨人的肩膀上工作的。我们使用高级语言编写的一个简单的hello world程序要是放到ENIAC时代还是很复杂的工程的。
目前量子计算机处于刚刚发展的阶段,也是有一些在经典计算机世界看起来很简单的事情,放到量子计算机世界里就需要很多新的idea和灵感来实现。比如:怎么让普通程序员使用量子计算机解决实际问题?量子计算机怎么存储数据?量子计算机整个体系结构是怎样的?等等还有很多很多问题。
那有人问了,量子计算机是和经典计算机一样,是一种完全独立的生态圈吗?是和像经典计算机一样有一套完美的生态圈吗?答案是否定的。原因有两个:1,目前最具有可实现性的超导是需要超低温运行环境的(0.0145297 K)。2,qbits的扩展的工程并不容易。通俗地说,量子计算芯片需要绝对0度的运行环境,不能像经典计算机一样在正常的办公室就能使用,这一点对通用的量子计算机的推广有着制约。当然实现量子效应的物理载体有很多[超导、半导体、离子阱],我们是以超导为例子,目前像IBM、INTEL的量子IC都是基于超导的。像经典计算机一样,最小的信息载体是bit,经典叫bit,量子世界叫qbit。经典计算机世界里几亿个bit的集成现在都不是问题,但是在量子计算机世界里,50qbits的制作都有困难。也就是说qbits的扩展还没有找到很好的工程化方法。基于以上两点原因,真正通用的量子计算机离我们还有一定的距离。现在发展的方向是在经典计算机的基础上加上一个专用的量子IC。对,也就是说目前我们见到的IBM的量子计算机从板级到编程等等各个方面都是异构[经典计算机控制+量子IC]的。

一种量子计算机的详细框图。
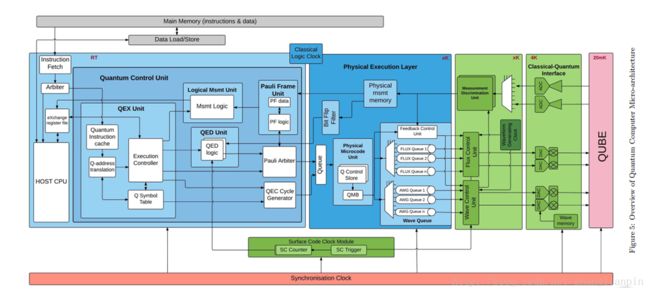
好了,说这么多就是想引出,现在所说的量子计算机并不是传统意义上和经典计算机一样是个通用计算机,而是在经典计算机基础上怎加了个量子计算专用IC,为了管理这个QPU,还需要一系列的测试控制设备,我们编程控制的最底层也就是控制这个测控设备喽,因此我们讨论量子计算机、量子编程的时候应该时时刻刻记着异构这个词语。
量子计算机的基本知识
这里先说下这里的基调,只是从一个抽象层面理解量子计算机原理及使用方法,制作qbit、量子计算机的内容不涉及。
Get ready to think outside a box you didn’t know existed.
—Charlie Bennett
介绍的关键点有 :如何描述单个qibt—-如何描述多个qbits—-什么是superposition(叠加态)—–什么是entanglement (纠缠态)—–测量—–如何利用上述特性存储信息并加速运算。
先说qbit,是一个量子物理学和信息科学融合的一个抽象概念。和bit进行对比着来比较好理解。表示信息一般都需要个载体,经典bit的载体是半导体开关电路。只能用来表示0或者1,这两个状态。而与之对应的qbit可以表示0或者1,也可以表示0和1的任意叠加态。嗯?不好理解,没事。我们在实际中也是用过“叠加”这样的思想解决过一些问题。比如物理分析中力的合成与分解、描述二维空间里的一个向量。这些都蕴含着叠加的思想。我们以描述二维空间中的一个向量为例,说明一些叠加的基本思想。
来张图:
我们描述一个苹果,一个橘子这种概念,自然数 1 1 就够用了,再复杂点一个蛋糕分一半可以用有理数 1/2 1 / 2 表示,再复杂点单位正方形的对角线怎么表示,用一个无理数 2–√ 2 就可以了,只不过需要点微积分的思想而已。那问题来了,一个空间里的向量怎么表示呐?你注意到了吗,前面的自然数、有理数、无理数都是只有大小属性的数,向量是一个量,具有大小和方向的量。自然地,使用复数来描述既有大小又有方向的量是比较可行的方法。复数有很多种表示方法,我最喜欢的是 aeiθ a e i θ 这种表示方法。大小就是a,角度就是 θ θ ,比较自然。
二维空间中的向量是可以使用复数来进行表达,但是三维空间的向量呐?这里是时候引入一些新的idea了,如何使用一种通用的方法描述不同维度空间里的向量?
下面看个三维空间中的向量。
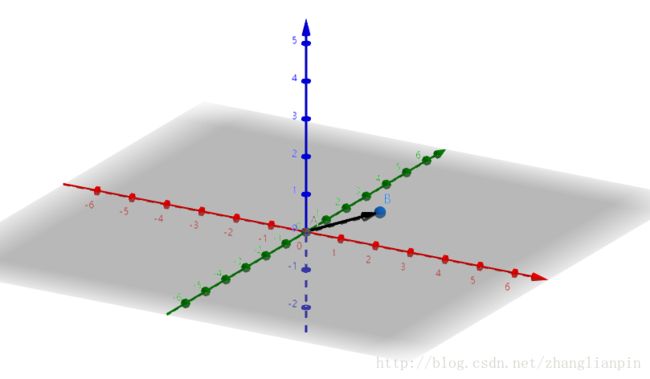
我们可以构造一种新的数来描述这种空间中的量,显然这种方式不是最好的,这里蕴含着一些通用的idea,我们定义一种新的数学实体,这个实体由多个数组成。什么意思呐?显然地,我们描述空间中一个量需要有一个好的参考系,比如我们常用的x-y-z正交坐标系。有了参考系,我们就容易描述在这个空间里面的量。直觉告诉我们每一个在这个空间里的量都有3个分量,我们可以认为这个量有3个简单的量叠加态。对了,那位同学你说对了,这就是向量的一种表达方式。
我们本身不好理解3维空间里的一个任意量,但是如果我们把这个量分解成3个更简单的量,这样就容易分析,容易计算了。上面的向量其实是这样的。
⎡⎣⎢100010001⎤⎦⎥⎡⎣⎢1 1 2 ⎤⎦⎥=⎡⎣⎢1 1 2 ⎤⎦⎥ [ 1 0 0 0 1 0 0 0 1 ] [ 1 1 2 ] = [ 1 1 2 ]
我们在一个很好的坐标系(正交的、单位的)下来度量一个量。
我们上面提到过好几次的空间、向量、坐标系等等概念,要明确这些概念并没有想象中的那么容易。就像我们每天生活在连续的世界里一样,要我们使用精确的语言描述 连续 好像不容易。好在这个问题早就被一些牛人解决了(微积分)。要描述空间这个概念,我们确实需要一些key idea,我们前面说了要描述空间,最好用空间的特性来描述它,要是有个好用的参考系。参考系有什么组成呐?由不同的向量(有3个分量)组成,组成参考系的向量数量有要求吗?针对组成参考系的各个向量有什么要求吗?什么向量都行吗?先说数量吧,3维空间需要且仅需要3个基础向量,少了无法完整描述空间中所有向量,多于3个基础向量的话,多出来的向量也很多余。也就是说针对3维空间来说,3个基础向量刚刚好。那这三个向量之间有什么限制吗?什么样的向量都可以吗?有,唯一的限制就是向量之间没有任何依懒性。他们之间要完全独立,每一个向量对组成空间都应该有贡献。啥意思呐,举个例子:
⎡⎣⎢1 2 3 ⎤⎦⎥⎡⎣⎢2 4 6 ⎤⎦⎥⎡⎣⎢3 1 7 ⎤⎦⎥ [ 1 2 3 ] [ 2 4 6 ] [ 3 1 7 ]
这3个向量能够作为一组基础向量,用于表征整个空间的其他向量吗?显然不能,为什么?因为第二个向量可以由第一个向量*2得到。前两个向量具有相关性。这样3个向量中其实只有两个向量对生成空间有作用,无法完整表述整个3维空间。
“能不能用官方语言说话?”还是刚才那位同学。对,对,言归正传,描述空间的一门通用语言叫矩阵,且可基本认为是通用的科学语言。数学中针对空间的定义是这样的,定义了一个集合,集合中有能够运算的对象(向量),满足一种运算(线性叠加),且运算后仍然属于这个空间。为了更方面地描述这个空间,我们使用 空间的维数、 基 、 线性叠加 等这些概念。这样来说,为了描述 R3 R 3 的空间,我们需要选择一组合适的基,啥叫合适?就是组成这组基的向量之间不相关。那这样的一组基通过线性叠加就可以生成整个 R3 R 3 空间。
我们思维上的变化:number—>vector—->space。很多现实问题从space这个角度考虑就很好解释,也更容易理解。比如说解 Ax=b A x = b 这样的方程组,如果以space角度考虑就简单的多。举个例子吧:
变换成矩阵形式就是:
⎡⎣⎢121381041⎤⎦⎥⎡⎣⎢xyz⎤⎦⎥=⎡⎣⎢2122⎤⎦⎥ [ 1 2 1 3 8 1 0 4 1 ] [ x y z ] = [ 2 12 2 ]
使用space思维可以很容易判断出有无解?有几个解?有没有解的问题可以转化为,使用左边的基能不能表示整个3维空间,若能则方程组肯定有解。若组成这个基的各个向量没有相关性,则有解且只有一个解。也就是说这个矩阵可逆,这个矩阵的零空间只有0,没有其他向量,它的解空间只有一个向量
⎡⎣⎢21−2⎤⎦⎥ [ 2 1 − 2 ]
这里我很忍不住想提一下4个基本子空间:列空间&左零空间、行空间&零空间。另外,顺便提一句,线性叠加,顾名思义这里研究的都是线性的(都是一次的,没有 x2 x 2 x3 x 3 这样的对象,那是微积分研究的主要对象)对象,通过线性叠加可以表达比较复杂的空间里的对象。
有了上述基本的线性代数的思想,就可以很容易地去理解qbit了。本节的最一开始说过,qbit能表示0态、1态这样的基态,还能表示基态的任意线性叠加。那就需要点线性代数的思想来表达qbit对应的数学抽象模型,上面介绍的线性代数的key idea就用上了。
上面我们举例子的空间是我们比较熟悉的3维空间,那一个qbit对应的是什么空间呐?答案是一个 C2 C 2 空间,一个复数空间。这样的空间选择一组基的话,需要几个向量?两个。很自然对吧。我帮你选择一组基。
[10][01] [ 1 0 ] [ 0 1 ]
我给出一个 C2 C 2 空间中的向量,
这个可以写成基向量线性叠加的形式:
2√2[10]+2√2[01] 2 2 [ 1 0 ] + 2 2 [ 0 1 ]
量子力学里一般使用Dirac’s bra-ket notation(狄拉克符号),这种方式表达简单,好用。
|0>+|1>2√ | 0 > + | 1 > 2
一个qbit可以使用 C2 C 2 空间来描述 |ψ⟩=α|0⟩+β|1⟩ | ψ ⟩ = α | 0 ⟩ + β | 1 ⟩ ,但是有个规约: |α|2+|β|2=1 | α | 2 + | β | 2 = 1 。
这里的 α α β β 可以是正数,负数,复数。
很显然当 α α β β 是复数时,整个表达式中有4个实数, |ψ⟩=(a+bi)|0⟩+(c+di)|1⟩ | ψ ⟩ = ( a + b i ) | 0 ⟩ + ( c + d i ) | 1 ⟩ 。好像很难在我们熟悉的3维空间中进行形象化,不是好像,就是很难。因为我们熟悉的最复杂的空间也就是 R3 R 3 空间。针对 C2 C 2 空间确实很难实例形象化,是时候发挥点自己的想象力了。不过,由于物理载体的限制,有一个维度的信息是无法被利用的,去掉一维信息后的 qbit 可以使用Bloch球面进行形象化。
一个量子比特具有4个任意常数(αreal、αimag、βreal、βimag),也就是说,有4个自由度。但实际上,一个量子比特只有2个自由度。其原因是因为在这4个任意常数之间,规定了如下2个约束:一是α、β需要满足几率归一化的条件:( |α|2+|β|2=1 | α | 2 + | β | 2 = 1 。二是两个复数α、β中,只有它们相对的相位差才有物理意义,量子叠加态的绝对相位是不可观测的,没有物理意义。因此,我们就干脆将α简化表示成一个实数,即 cos(θ/2) c o s ( θ / 2 ) 的形式,而α、β之间的相位差记为 ϕ ϕ 。
来张Bloch球的图片:
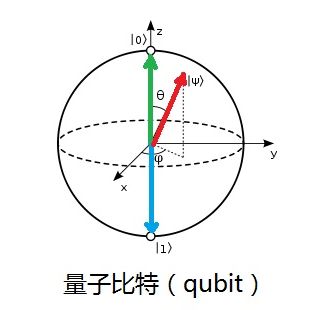
Bloch球虽然是形象化工具,可以帮助理解qbit,我个人认为还是使用线性代数的space思维进行数学运算和表达,这样比较具有通用性。
现在我们已经掌握和明白了如何使用线性代数方法描述一个抽象的Qbit,也很容易明白一个Qbit能够表示的信息量是无穷大的,那如何使用Qbit表示信息呐?怎么把Qbit表示的信息取出来呐?表示信息还是挺简单的,如:表示0,可以使用 1|0⟩+0|1⟩ 1 | 0 ⟩ + 0 | 1 ⟩ 表达;表示1,可以使用 0|0⟩+1|1⟩ 0 | 0 ⟩ + 1 | 1 ⟩ ;表示0和1的叠加态,可以使用 2√2|0⟩+2√2|1⟩ 2 2 | 0 ⟩ + 2 2 | 1 ⟩ 。注意上述表示方法中,都满足 |α|2+|β|2=1 | α | 2 + | β | 2 = 1 的规约。那表示的信息我可以读取到吗?很遗憾,量子力学的大牛们目前发现的规律是,你一旦读取了Qbit,Qbit的叠加态就会塌陷到组成这种叠加态的基态上,且各个基态成概率分布,概率值等于|α|^2和|β|^2,概率加和等于1,符合概率思想。还是以我们上面的例子来说明,表示0的 1|0⟩+0|1⟩ 1 | 0 ⟩ + 0 | 1 ⟩ ,经过测量会得到概率为1的 |0⟩ | 0 ⟩ 基态和概率为0的 |1⟩ | 1 ⟩ 。表示1的 0|0⟩+1|1⟩ 0 | 0 ⟩ + 1 | 1 ⟩ ,经过测量会得到概率为0的 |0⟩ | 0 ⟩ 基态和概率为1的 |1⟩ | 1 ⟩ 。这和经典bit一样,没什么稀奇的。有意思的是 2√2|0⟩+2√2|1⟩ 2 2 | 0 ⟩ + 2 2 | 1 ⟩ 这种叠加态,经过测量我们会得到概率为 12 1 2 的 |0⟩ | 0 ⟩ 基态和概率为 12 1 2 的 |1⟩ | 1 ⟩ 基态。 12|0⟩+3√2|1⟩ 1 2 | 0 ⟩ + 3 2 | 1 ⟩ ,这种叠加态,测量就会得到概率为 14 1 4 的 |0⟩ | 0 ⟩ 基态和概率为 34 3 4 的 |1⟩ | 1 ⟩ 基态。
这就是Qbit表示信息和提取信息的基本原理。这样看来,想利用Qbit表示信息,加速运算还是需要一些特殊的trick 的。
我们已经掌握了单个Qbit的控制大法,那多个Qbits要怎样描述呐?先从两个Qbit开始吧,理解了两个Qbit,再去理解三个Qbit,然后你就可以理解任意数量的Qbits了。
所谓一生二,二生三,三生万物。
行了,别扯这么多了。直接来干货,两个Qbits代表的空间是一个 C4 C 4 空间。“那个举手的同学又有啥问题?” “你咋知道是 C4 C 4 空间的???” 说实话,我也不知道,你有机会问问搞微观物理的吧。 但是事实上,满足归一化条件( |α1|2+|β1|2+|α2|2+|β2|2=1 | α 1 | 2 + | β 1 | 2 + | α 2 | 2 + | β 2 | 2 = 1 )的 C4 C 4 空间确实可以描述两个Qbits所有的量子效应。那很自然地,我给出描述 C4 C 4 这个空间的一组基:
⎡⎣⎢⎢⎢1000⎤⎦⎥⎥⎥⎡⎣⎢⎢⎢0100⎤⎦⎥⎥⎥⎡⎣⎢⎢⎢0010⎤⎦⎥⎥⎥⎡⎣⎢⎢⎢0001⎤⎦⎥⎥⎥ [ 1 0 0 0 ] [ 0 1 0 0 ] [ 0 0 1 0 ] [ 0 0 0 1 ]
我想描述两个Qbit组成的世界,我得用4个 C4 C 4 的向量组成的一组基来进行描述。这样书写太麻烦, 不符合狄拉克他老人家的本意,另外我们还需要引入 张量积 运算的概念。定义这样一种运算:
[10]⨂[10]=⎡⎣⎢⎢⎢1000⎤⎦⎥⎥⎥ [ 1 0 ] ⨂ [ 1 0 ] = [ 1 0 0 0 ]
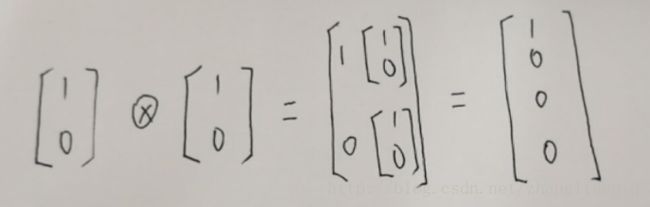
实在不知道怎么用LateX公式表达张量积的运算过程,看下这个手写的这款吧,一不小心让你们看到了我的笔记,看啥呐,赶紧收藏啊,坐等升值☺。
定义这个张量积干啥?我的理解是要表示两个状态的同时存在的情况,像第一个qbit处于0态,并且第二个qbit同时也处于0态,怎么描述这样的一种情况呐?注意,这里关注的是真正的同时,这种状态可以用一个向量表示,也可以认为是两个向量的向量积。换句话说,若一个系统的整体状态能分解成两个向量的向量积,也说明这样的系统具有一定程度的离散性,测量这样的整体系统的其中一个Qbit时,并不影响另一个Qbit的状态。从空间角度来分析,一个Qbit张成的空间是一个 C2 C 2 空间,那要想表达具有两个Qbit 张成的空间,是一个 C4 C 4 空间。一个 C4 C 4 空间里的一个向量若能表达成两个 C2 C 2 空间里的向量的张量积的话,我们可以理解成第一个Qbit处于一个基态,同时另一个Qbit处于一个基态。这样可以简化系统的表示。
用狄拉克符号表示:
|00⟩=⎡⎣⎢⎢⎢1000⎤⎦⎥⎥⎥ | 00 ⟩ = [ 1 0 0 0 ]
|0⟩=[10] | 0 ⟩ = [ 1 0 ]
|1⟩=[01] | 1 ⟩ = [ 0 1 ]
|00⟩ | 00 ⟩ 就代表 |0⟩⨂|1⟩ | 0 ⟩ ⨂ | 1 ⟩ 的张量积。
那 C4 C 4 空间里的4个基向量可以表达为 |00⟩、|01⟩、|10⟩、|11⟩ | 00 ⟩ 、 | 01 ⟩ 、 | 10 ⟩ 、 | 11 ⟩ 。
明白了多个Qbit描述的方法,我们可以现在来聊聊叠加态和纠缠态了。
叠加态来个两个Qbit的例子:
先说向量:
⎡⎣⎢⎢⎢⎢⎢12121212⎤⎦⎥⎥⎥⎥⎥ [ 1 2 1 2 1 2 1 2 ]
上面的向量可以代表两个Qbits组成的一个叠加态。上面的系统状态使用狄拉克符号表示:
|00⟩+|01⟩+|10⟩+|11⟩2 | 00 ⟩ + | 01 ⟩ + | 10 ⟩ + | 11 ⟩ 2
上面的系统可以分解为两个向量的张量积。
|0⟩+|1⟩2√⨂|0⟩+|1⟩2√ | 0 ⟩ + | 1 ⟩ 2 ⨂ | 0 ⟩ + | 1 ⟩ 2
不知道大家懂了没有?这种 C4 C 4 空间的叠加态可以分解为独立的两个 C2 C 2 空间的叠加态的张量积。
再来看看这种状态的测量后的概率分布: 14 1 4 的 |00⟩ | 00 ⟩ , 14 1 4 的 |01⟩ | 01 ⟩ , 14 1 4 的 |10⟩ | 10 ⟩ , 14 1 4 的 |11⟩ | 11 ⟩ 。概率是成等概论分布的,你有没有发现,2 Qbits 确实可以表示出4个状态,也就说说可以表示4种信息。这是使用经典bit 无法实现的。畅想一下,3个Qbits张成的空间是几维的?8维,对吧。需要8个基向量。这个空间里的一个向量可以同时表示8种基态的叠加,表示的信息量是成指数增加的,AMAZING。 因为前面看过的国际象棋和米粒 故事的图片。 这是好消息,但是坏消息是测量只能得到各个基态的概率值。利用叠加特性来表示信息量确实有得天独厚的优势,但是利用叠加态来进行加速运算确实需要一些 new idea。因为你表示这些信息后,得利用各种旋转门对这些叠加态的信息进行处理,以向你想要的结果趋近。最后通过测量得出结果。从这一点上来看,能利用这个特性解决问题的想法还真不多,发现新的能利用这个特性的算法还是很有挑战性的。目前,已知的也就是 grover算法和shor算法。
和这种特性对应的是纠缠态。
还是先说向量:
⎡⎣⎢⎢⎢⎢⎢2√2002√2⎤⎦⎥⎥⎥⎥⎥ [ 2 2 0 0 2 2 ]
狄拉克表示法:
|00⟩+|11⟩2√ | 00 ⟩ + | 11 ⟩ 2
这种结构的态不能分解成两个态的张量积。就是说这个系统状态就是一个整体,没有任何办法将他们分开来分析。这也许就是 纠缠态 的含义吧,处于纠缠态的Qbits 有着千丝万缕的关联。来看测量时的概率, 12 1 2 的 |00⟩ | 00 ⟩ , 12 1 2 的 |11⟩ | 11 ⟩ 。看出这个东西也很 AMAZING 了吧,这两个qbit 要不都处于0态,要不都处于1态,是有关联的,不会出现一个是0态,另一个是1态的情况。这就有意思了,你可以提前制备好两个qbits处于纠缠态,然后把他们物理上分离(扯开一定的距离)开来,通过测量其中一个Qbit的状态,我就可以知道另一个的状态。点到为之吧,国内的 潘教授团队 做的量子通讯就是这种情况的应用。
3个Qbits的情况这里就不展开阐述了,只是 C8 C 8 空间,且满足那个归一化规约而已。留个作业,感兴趣的自己琢磨琢磨,或者拿出纸笔画画。
量子门操作
描述量子计算机的模型,一般主流有3种:quantum circuit model , one way quantum computation model , adiabatic quantum computation model。IBM描述量子计算机的模型使用的是quantum circuit model(量子线路模型)。啥意思,就是在基态上添加各种门操作,然后通过测量得到结果。看图说话:
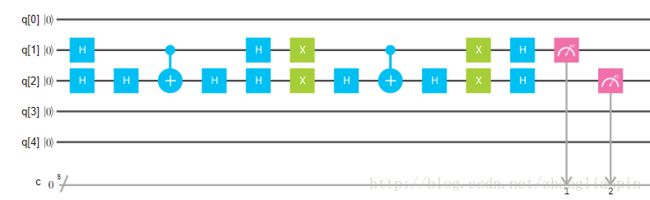
所以说,了解量子线路模型首先要先了解各种量子操作门。我们还是按照之前线性代数里space的思维模式进行各种门的解释。其实各种门就是针对空间里的向量的一种变换操作,也就是基的各种线性叠加。在量子计算机中的门的变换其实是各种旋转变换,即大小长度不变,只是在各种space里进行各种角度的旋转变换。用行话表达就是,量子计算机的门都是酉变换。
U†U=1 U † U = 1 ( A† A † represents the complex conjugation and transpose of any matrix A A )。
在说量子门之前,先说说空间里的变换怎么表达?答案是使用矩阵。举个例子你就很明白了,
[1001][1 0 ]=[1 0 ] [ 1 0 0 1 ] [ 1 0 ] = [ 1 0 ]
这个向量表示成 [1 0 ]T [ 1 0 ] T 是建立在选取了这个space里面的一组标准正交基。
[1001] [ 1 0 0 1 ]
为什么叫标准正交基呐?标准的含义是组成这个基的各个向量的模是1,且各个向量之间两两正交。这样的基不错,每个方向上的前进单位是1,且各个方向完全无相关。使用这样的基作为参考那真是太好了,方便表达和运算。那我想操作 [1 0 ]T [ 1 0 ] T 这个向量,对这个向量进行变化,比如说我想要的结果是
[0 1 ] [ 0 1 ]
体现在几何意义上就是逆时针旋转了90°,我们怎么表达这个变换呐?像下面这样:
[0110][1 0 ]=[0 1 ] [ 0 1 1 0 ] [ 1 0 ] = [ 0 1 ]
看上面这个矩阵,和最初的矩阵相比,矩阵的行互换了,这种矩阵其实是行置换矩阵。怎么理解这个矩阵后面跟了个向量这个事实呐?其实,按照上面的说法,明显地在新的参考系下,向量值并没有变,还是
[1 0 ] [ 1 0 ]
只不过参考系变了,两个基向量互换了,这种情况下的向量要是在单位阵的参考系下,向量怎么表示呐?各个分量也互换呗。这就是矩阵乘以向量的实际意义,就是要得知在单位矩阵下向量的各个分量值。矩阵*向量这个整体你可以有两种看待方法:
1,矩阵代表对向量的一种变换操作。
2,变换了参考系后,基于新的参考系的向量表达方法。
矩阵乘以向量得出的结果还是个向量,不过这个向量是用单位阵作为参考系的。大家都同意标准,好交流嘛,毕竟针对同一个space你可以选出无穷多组基。使用不同的基表达的含义是等价的,只不过不同的问题使用合适的基可以简化问题的计算和解决。
量子门有好多,我们从三类常用门里分别选择一个具有较强代表性的进行讲解。翻转门派—-Pauli Operators(泡利门),旋转派—-Hadamard gate(阿达马门),多 Qbits控制门—-CNOT门。
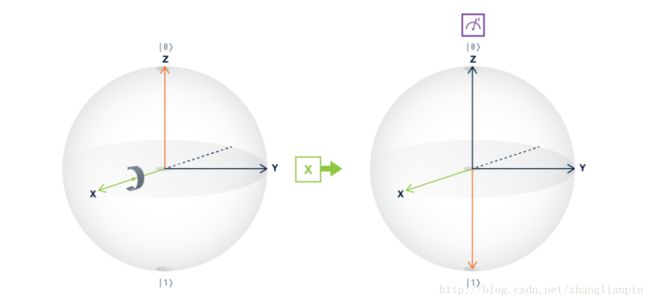
泡利门这一派主要包括X Y Z 3种门。

我们选择X门进行讲解,是不是很简单,和我们上面举例子的门长的一模一样。只不过,向量是由复数组成的,直接实例化对应到旋转有一定难度,不过有了bloch球的实例化辅助也好理解:以X轴作为转轴,旋转了 π π 。
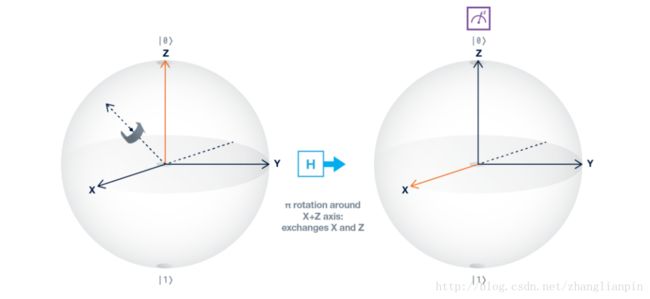
另一个有意思的量子操作门是Hadamard gate(阿达马门),这一系列是旋转阵。其实,翻转阵也是特殊的旋转阵。这种矩阵都是正交单位阵,组成这些阵的每个向量都是单位的,和其他向量都是正交的。Hadamard gate之所以叫这个名字,是因为是Hadamard 这哥们发现的构造这种标准正交阵的方法。怎么构造呐?矩阵的元素只有1或者-1,且向量是单位的。各位看官且看:
12√[111−1] 1 2 [ 1 1 1 − 1 ]
满足上面说的单位和正交吧。
12√[111−1][10]=⎡⎣2√22√2⎤⎦ 1 2 [ 1 1 1 − 1 ] [ 1 0 ] = [ 2 2 2 2 ]
这个态也是经常见到的叠加态,测量时得到两个基态的概率都为 12 1 2 。也就是常说的 |+⟩ | + ⟩ 。还有一个态是 |−⟩ | − ⟩ 。
12√[111−1][01]=⎡⎣2√2−2√2⎤⎦ 1 2 [ 1 1 1 − 1 ] [ 0 1 ] = [ 2 2 − 2 2 ]
这种H门在bloch球的实例化是什么样的呐?
还有一个量子门是CNOT门。这个很简单,是一个双Qbit门。
⎡⎣⎢⎢⎢1000010000010010⎤⎦⎥⎥⎥ [ 1 0 0 0 0 1 0 0 0 0 0 1 0 0 1 0 ]
很简单的,第一个Qbit状态不变,第二个Qbit取反。聪明的你看出来了吗?
|00⟩ | 00 ⟩ 经过CNOT门后状态不变。
|01⟩ | 01 ⟩ 经过CNOT门后状态不变。
|10⟩ | 10 ⟩ 经过CNOT门后变为 |11⟩ | 11 ⟩
|11⟩ | 11 ⟩ 经过CNOT门后变为 |10⟩ | 10 ⟩
换成基态就比较好理解了。前两个分量不变,后两个调换。
⎡⎣⎢⎢⎢1000⎤⎦⎥⎥⎥⎡⎣⎢⎢⎢0100⎤⎦⎥⎥⎥⎡⎣⎢⎢⎢0010⎤⎦⎥⎥⎥⎡⎣⎢⎢⎢0001⎤⎦⎥⎥⎥ [ 1 0 0 0 ] [ 0 1 0 0 ] [ 0 0 1 0 ] [ 0 0 0 1 ]
一目了然吧!!!
tag:qbit的 |01⟩ | 01 ⟩ 的第一个qibt 是左边的这个,和经典的bits序列正好相反。01的第一位是右边的这个。
所有的量子门都是可逆的,也好理解,旋转嘛,当然可以再旋转回来
量子叠加态和传统叠加态
我们很多人看了量子叠加态之后提出一个疑问,这个量子叠加态和传统的叠加有什么本质上的区别?这个是个好问题,生活中叠加的例子其实也着实不少,比如3个不同音调的声音混合成一个声音,这个叠加的声音可以一下子传到人的耳朵,就可以产生美妙的声音效果。其实不同音调的声音具有不同的频率。由3个不同频率的声音叠加成的声音,最多只能恢复出3个不同频率的声音。而量子叠加态和这个有着本质的区别,通过上面的介绍我们得知,由3个Qbits组成的叠加态可以表示 23 2 3 个状态,表示的状态数量比传统叠加态多。
量子测量得出的概率和经典概率的区别与联系
我们看到,量子测量得出的是各个基态的概率值,那概率我们也很熟悉啊。经典世界中也有很多概率的物理载体。想象这样一个系统,这个系统由3枚质地均匀的硬币组成,每次有规律地摇动这个系统,然后停止摇动,重复多次实验之后也可以得出8种情况的概率值。如果用 H表示正面,T表示背面。有8种可能:HHH、HHL、HLH、HLL、LHH、LHL、LLH、LLL 。通过大量的实验,可以得出符合概率分布,每种情况的概率是 18 1 8 。但是这个概率系统和Qbits 组成的概率系统还是存在本质的区别的。
- 产生随机的原理不一样。
- 控制概率产生的能力不一样。
下面分别进行说明:
有人在这里可能要问:经典力学中也有随机性,掷硬币不就是一半概率朝上,一半概率朝下吗?回答是:同样是概率,背后的原因不一样,可改进的余地也不一样。
掷硬币的结果难以预测,是因为相关的外界因素太多:硬币出手时的方位、速度、空中的气流状况等等。也就是说,经典力学中的概率反映的是信息的缺乏 。你可以通过减少这些因素的干扰来增强预测能力,例如在真空中掷,消灭气流,用机器掷,固定方向和力度。最终,你可以确定地掷出某一面,或者至少使掷出某一面的机会显著超过另一面。(赌神是怎样炼成的!)但在量子力学中,测量结果的概率是由体系本身的状态决定的,不是由于外界的干扰,不是由于缺少任何信息,因此完全无法“改进”。所以这种随机性是内在的,是量子力学的一种本质特征!
对这种概率的控制力度也存在很大的差异,抛硬币很难控制让其每次都是正面朝上或者每次都是反面朝上。或者让其 14 1 4 的概率朝上, 34 3 4 的概率朝下。但Qbits就可以通过各种门的操作实现精准的控制。
也就是我们拥有了一个更好的概率载体,这个载体还能控制概率分布,AMAZING。
经典概率性能 VS 量子叠加性能 VS 2的n次方个机器真并行
既然量子计算机具有指数级加速功能,又在一定程度上使用概率思想。那很自然的一个问题就是,经典概率算法、量子叠加态、和 2n 2 n 个机器真并行相比,那个蕴含的能力大?或者说那个性能更高?关于这个问题 经典概率<量子叠加< 2n 2 n 个机器真并行。经典概率性能小于量子叠加上一下小节已经说过了。那量子叠加态和 2n 2 n 个机器真并行之间谁性能高呐?当然是 2n 2 n 个机器真并行性能要高些。举个例子:从n个items中搜索指定的item,如果使用量子叠加特性,目前grover算法的算法复杂度是O( n−−√ n )。若使用 2n 2 n 个机器并行搜索,算法复杂度是O(1)。显然 2n 2 n 个机器并行完胜。但是问题是随着问题规模的增大,没有那么多的计算机可以让你使用。其实, 2100 2 100 的数量级可以表示世界上所有的一切了。所以使用 2n 2 n 个机器并行进行搜索也只能是一种很美好的愿望罢了。
经典算法 VS 量子算法
经典计算机算法解决问题的一般步骤是:
- 抽象问题,编码要表示的问题对象数据。
- 进行+ - */ 基本运算。
- 得出结果,转化为实际问题的解决步骤。
使用量子算法解决问题的一般步骤:
- 制备叠加态,使其能表示 2n 2 n 个状态。
- 将实际问题通过量子门操作编码到叠加态。
- 使用一些新方法操作处于叠加态的qbits,让答案处于高概率事件,并通过测量得出答案。
我们都清楚经典计算机的基本编程思想,数据结构+算法。数据结构即怎么表示信息的过程,算法即表示处理信息方法。常见的数据结构例如线性结构,常见的算法思想如递归、分而治之、循环等。但是量子计算机主要利用量子的叠加、纠缠等特性进行一些特定问题(尤其是一些NP问题)的加速。因现实问题中能利用量子叠加态和纠缠态特性的并不多,目前常见的有分解大质数的shor算法和用于搜索的Grover’s Algorithm。因此可以看出来,用量子计算机解决问题的基本思维模式和用经典计算机解决问题时用的基本思维模式不太一样。
使用量子计算机解决问题可能需要的基本思维有:概率算法思想、利用量子叠加态加速等等。
量子编程
前面说了,目前阶段的量子计算机都为经典计算机+量子芯片的异构结构。为了管理这个量子芯片,还需要一系列的测试控制设备,我们编程控制的最底层也就是控制这个测控设备喽,因此我们讨论编程架构的时候应该时时刻刻记着异构 这个词语。
量子计算机的编程架构框图:

其实,量子计算机编程框架的研究是一个很活跃的领域,有很多个人和机构都在推出各种编程架构和语言框架。我们以IBM的编程框架为例:
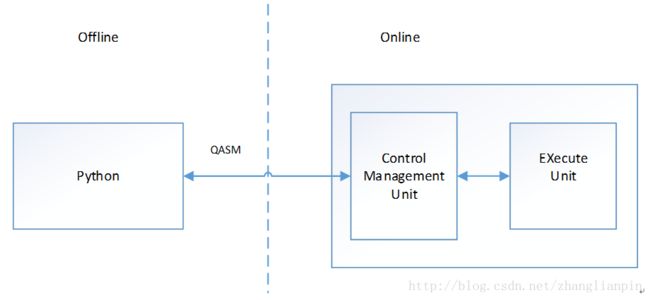
详细点的图:
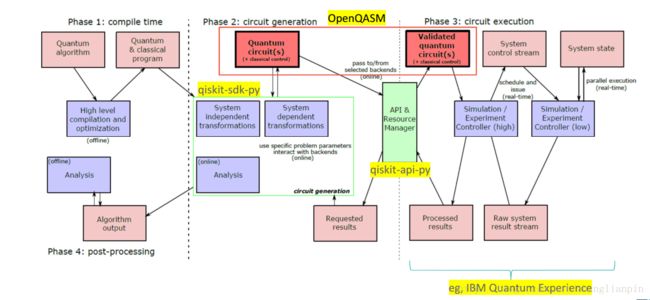
关于这个的资料请参考:QISKit
这里需要注意的是,虽然我们使用的量子编程语言是Python、Q#这样的高级语言,但因为量子算法并不使用经典算法的思想,而是一套新的思维方法,故量子编程实际上还是利用量子操作门来操作Qbits。在解决问题上,本质上的思维还处于Qasm这一级别。但目前确实也看到一些通用量子库的研究,比如量子算法里快速傅里叶变换是一个很基本的操作,因此有些编程框架内将这些作为通用的编程库来使用。再比如,有一些特定领域有可能产生完全屏蔽掉qbits的编程模型,但也仅仅限制在很小的领域内。
总之,目前的情况,量子计算机并没有向通用计算机的方向发展,而是向着辅助经典计算机的辅助单元去发展的。而且现在看来经典计算机在解决人机交互,低速运算领域已经能很好地完成工作,并不会完全被量子计算机替代。当然,随着量子计算机技术的发展,量子计算机有可能成为通用计算机并普及,到那时候的量子计算机编程也许就会想现在的经典计算机一样,只关心问题就好了,怎么转化为计算机能听懂的话完全是自动的。
以grover 算法为例来show 量子计算机的性能
参考资料
- Structured Computer Organization(Andrew S.Tanenba)
- 量子计算机解释 - 人类技术的壁垒
- 书籍:Quantum Computation and Quantum Information(量子计算与量子信息)
- 书籍:Quantum Computing for Computer Scientists
- 书籍:Introduction to Linear Algebra, 4th edition Gilbert Strang
- 网易公开课(mit 公开课):线性代数 Gilbert Strang
- IBM 量子计算机体验平台:IBM Q - Quantum Experience
- 计算机硬件发展史