RDS 5.7三节点企业版时代的数据一致性解决方案
上篇我们看到了在MySQL主备模式下,我们在数据一致性上做了不少事情,但解决方案都有一定的局限性,适合部分场景或者解决不彻底的问题。随着以Google Spanner以及Amazon Aruora 为代表的NewSQL的快速发展,为数据库的数据一致性给出了与以往不同的思路: 基于分布式一致性协议!我们也实现了一个独立的分布式协议库X-Paxos,并将这个特性继承到了RDS 5.7三节点企业版中。(RDS 5.7三节点在7月15日即将开始公测,敬请关注!)
一.分布式一致性协议
说到一致性协议,我们通常就会讲到复制状态机。一般情况下,我们会用复制状态机加上一致性协议算法来解决分布式系统中的高可用和容错。许多分布式系统,都是采用复制状都是采用复制状态机来进行副本之间的数据同步,比如HDFS,Chubby和Zookeeper等。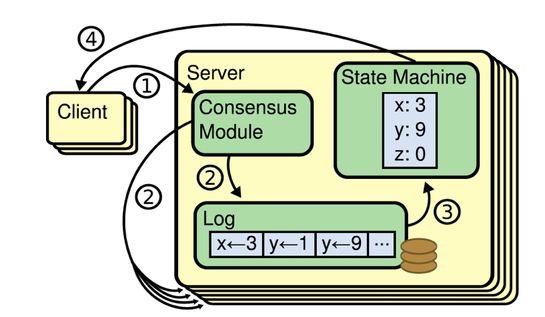
所谓复制状态机,就是在分布式系统的每一个实例副本中,都维持一个持久化的日志,然后用一定的一致性协议算法,保证每个实例的这个log都保持完全一致,实例内部的状态机按照日志的顺序回放日志中的每一条命令,这样客户端来读取数据时时,在每个副本上都能读到一样的数据。复制状态机的核心就是图中的Consensus模块,也就是我们要讨论的Paxos,Raft等一致性协议算法(准确的说,Paxos并不指代一个协议,而是一类协议的统称,比较常见的paxos类协议有Basic-Paxos 和Multi-Paxos)
1.Basic-Paxos
Basic-Paxos是Lamport最先提出的分布式一致性算法。要理解Paxos,只要记住一点就好了,Paxos只能为一个值形成共识,一旦Propose被确定,之后值永远不会变,也就是说整个Paxos Group只会接受一个提案(或者说接受多个提案,但这些提案的值都一样)。
Paxos协议中有三个角色,Proposer和Acceptor和Learner角色(Leaner只是学习Proposer的结果,暂时不讨论该角色)。Paxos允许多个Proposer同时提案。Proposer要提出一个值让所有Acceptor达成一个共识,达成一个共识分为2个阶段:Prepare阶段和Accept阶段。
Prepare阶段
Proposer会给出一个ProposeID N(注意,此阶段Proposer不会把值传给Acceptor)给每个Acceptor,如果某个Acceptor发现自己从来没有接收过大于等于N的Propose,则会回复Proposer,同时承诺不再接收ProposeID小于等于N的提议的Prepare。如果这个Acceptor已经承诺过比N更大的propose,则不会回复Proposer。(如果Acceptor之前已经Accept了(完成了第二个阶段)一个小于N的Propose,则会把这个Propose的值返回给Proposer,否则会返回一个null值。当Proposer收到大于半数的Acceptor的回复后,就可以开始第二阶段。)
Accept阶段
这个阶段Propose能够提出的值是受限的,只有它收到的回复中不含有之前Propose的值,他才能提出一个新的value,否则只能用回复中Propose最大的值作为提议的值。Proposer用这个值和ProposeID N对每个Acceptor发起Accept请求。也就是说就算Proposer之前已经得到过acceptor的承诺,但是在accept发起之前,Acceptor可能给了proposeID更高的Propose承诺,导致accept失败。也就是说由于有多个Proposer的存在,虽然第一阶段成功,第二阶段仍然可能会被拒绝掉。
2.Multi-Paxos
前面讲的Paxos还过于理论,无法直接用到复制状态机中,总的来说,有以下几个原因
1).Paxos只能确定一个值,无法用做Log的连续复制
2).由于有多个Proposer,可能会出现活锁
3).提案的最终结果可能只有部分Acceptor知晓,无法达到复制状态机每个instance 的log完全一致。Multi-Paxos,就是为了解决上述三个问题,使Paxos协议能够实际使用在状态机中。解决第一个问题其实很简单:为Log Entry每个index的值都用一个独立的Paxos instance。解决第二个问题也很简单,让一个Paxos group中不要有多个Proposer,在写入时先用Paxos协议选出一个leader(如我上面的例子),之后只由这个leader写入,就可以避免活锁问题。并且,有了单一的leader之后,我们还可以省略掉大部分的prepare过程。只需要在leader当选后做一次prepare,所有Acceptor都没有接受过其他Leader的prepare请求,那每次写入,都可以直接进行Accept,除非有Acceptor拒绝,这说明有新的leader在写入。为了解决第三个问题,Multi-Paxos给每个Server引入了一个firstUnchosenIndex,让leader能够向每个Acceptor同步被选中的值。解决这些问题之后Paxos就可以用于实际工程了。
Paxos到目前已经有了很多的补充和变种,实际上,ZAB也好,Raft也好,都可以看做是对Paxos的修改和变种。关于Paxos,还有一句流传甚广的话,“世上只有一种一致性算法,那就是Paxos”。
3.Raft
Raft是斯坦福大学在2014年提出的一种新的一致性协议,协议的内容,网上材料太多,不做过多阐述,这里仅和Paxos做一下比较:
1).Raft则将Multi-Paxos的功能做了模块划分,并对每个模块做了详细的阐述和理论证明:Leader Election、Log Replication、Commit Index Advance、Crash Recovery、Membership Change 等。
2).Multi-Paxos和Raft,最本质的区别在于,是否允许日志空洞。Raft必须连续,不允许空洞。Multi-Paxos允许日志空洞存在二.X-Paxos
X-Paxos是一个从阿里业务场景出发、基于分布式一致性协议的实现(严格意义来说,X-Paxos的实现同时参考了经典的multi-Paxos和Raft协议),服务于RDS 5.7三节点企业版。同时X-Paxos是一个公共库,可以应用在更多的系统。下面详细讲一下X-Paxos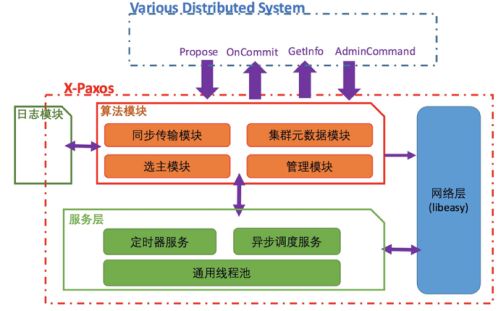
X-Paxos的整体架构如上图所示,主要可分为网络层、服务层、算法模块、日志模块4个部分。
1.网络层
网络层基于阿里内部非常成熟的网络库libeasy实现。libeasy的异步框架和线程池非常契合我们的整体异步化设计,同时我们对libeasy的重连等逻辑进行了修改,以适应分布式协议的需求。
2.服务层
服务层是驱动整个Paxos运行的基础,为Paxos提供了事件驱动,定时回调等核心的运行功能,每一个Paxos实现都有一个与之紧密相关的驱动层,驱动层的架构与性能和稳定性密切相关。X-Paxos的服务层是一个基于C++11特性实现的多线程异步框架。常见的状态机/回调模型存在开发效率较低,可读性差等问题,一直被开发者所诟病;而协程又因其单线程的瓶颈,而使其应用场景受到限制。C++11以后的新版本提供了完美转发(argument forwarding)、可变模板参数(variadic templates)等特性,借助C++11的这个特性,我们实现了一种全新的异步调用模型。
3.算法模块
X-Paxos当前的算法基于强leadership的multi-paxos[3]实现,大量理论和实践已经证明了强leadership的multi-paxos,性能好于multi-paxos/basic paxos,当前成熟的基于Paxos的系统,都采用了这种方式。
算法模块的基础功能部分本文不再重复,感兴趣的同学可以参考相关论文。在基础算法的基础上,结合阿里业务的场景以及高性能和生态的需求,X-Paxos做了很多的创新性的功能和性能的优化,使其相对于基础的multi-paxos,功能变的更加丰富,性能也有明显的提升。下一章中,将对这些优化进行详细的介
4.日志模块
日志模块本是算法模块的一部分,但是出于对极致性能要求的考虑,我们把日志模块独立出来,并实现了一个默认的高性能的日志模块;有极致性能以及成本需求的用户,可以结合已有的日志系统,对接日志模块接口,以获取更高的性能和更低的成本。这也是X-Paxos作为高性能独立库特有的优势,后面也会对这块进行详细介绍。
三. RDS 5.7三节点企业版的数据一致性解决方案
RDS 5.7三节点企业版是第一个接入X-Paxos生态的重要产品,它是一个自封闭、高可靠、强一致、高性能的数据库系统,可以凭借内核本身彻底解决数据质量的问题,无需外部介入。同时RDS 5.7三节点企业版也是基于MySQL生态,兼容最新版本的MySQL 5.7,对于MySQL的用户来说,可以无缝迁移到RDS 5.7三节点企业版。
1.整体架构
先来看一下RDS 5.7三节点企业版的基本架构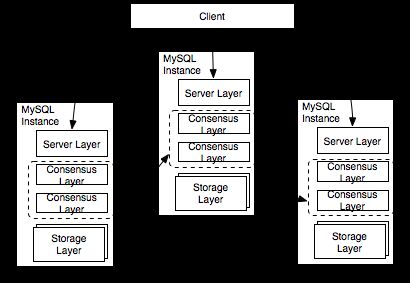
上图展示的是一个部署三个实例的RDS 5.7三节点企业版集群。RDS 5.7三节点企业版是一个单点写入,多点可读的集群系统。在同一时刻,整个集群中至多会有一个Leader节点来承担数据写入的任务。相比多点写入,单点写入不需要处理数据集冲突的问题,可以达到更好的性能与吞吐率。
RDS 5.7三节点企业版的每个实例都是一个单进程的系统,X-Paxos被深度整合到了数据库内核之中,替换了原有的复制模块。集群节点之间的增量数据同步完全是通过X-Paxos来自驱动,不再需要外部手动指定复制位点。 RDS 5.7三节点企业版为了追求最高的性能,选择了自己实现Consensus日志这种接入X-Paxos的方式,在MySQL Binlog的基础上实现了一系列X-Paxos日志接口,赋予X-Paxos操纵Binlog的能力。
用户在访问RDS 5.7三节点企业版时可以直接使用MySQL原生的客户端进行访问,完美兼容MySQL生态的周边系统,包括中间件、备份恢复、DTS等等。
2.复制流程

RDS 5.7三节点企业版的复制流程是基于X-Paxos驱动Consensus日志进行复制,Leader节点在事务prepare阶段会将事务产生的日志收集起来,传递给X-Paxos协议层后进入等待。X-Paxos协议层会将Consensus日志高效地转发给集群内其他节点,相比原生MySQL,日志发送采用了Batch,Pipeline等优化手段,特别是在长传链路的场景中,效率提升明显。当日志在超过集群半数实例上落盘后 X-Paxos会通知事务可以进入提交步骤,否则通知事务回滚。
Follower节点收到Leader传递过来的日志以后将日志内容Append到Consensus Log末尾,由协调者负责读取并解析日志后传递给各个回放工作线程进行数据更新。由于Consensus日志是基于Binlog开发,回放可以利用MySQL-5.7的Logic clock并行复制特性。 相比MySQL-5.6中回放并行度受到表数目限制,MySQL-5.7可以做到依赖主库Group Commit的事务数进行并发回放,进一步提升回放的速度。
3.Failover
RDS 5.7三节点企业版只要半数以上的节点存活就能保证集群正常对外服务。 当Leader节点故障时会触发重新选主的流程。 选主流程由X-Paxos驱动,在Paxos协议的基础上,结合优先级进行新主的选举。
如上图所示,左上的Case是原Leader A节点宕机,此时在选举超时后,B节点开始尝试选自己为Leader, 并且C节点同意, 那么B成为新的主节点,集群正常运行。
左下的Case 是原Leader A节点发生网络分区,此时在选举超时后,BC两个节点的行为和之间的Case类似。 A节点由于无法将心跳和日志发送给BC两个节点在超时后会降级,然后不断尝试选自己为Leader,但是因为没有其他节点的同意,达不成多数派,一直都不会成功。
再看日志数据,RDS 5.7三节点企业版 承诺在failover的情况下不会丢失提交的数据。Paxos协议保证了不管集群发生什么样的变故,在恢复后一定能保证日志的一致性。那么只要数据是按照日志进行回放,就能保证所有节点的数据一致。如右上所示,假设A节点宕机或者分区前已经把3号日志复制到了B节点,那么在重新选举后,B节点会尝试将3号日志再复制到C节点。
4.性能对比
Group Replication是MySQL 官方出品的集群方案。它借鉴了Galera的思想,同样支持多主多点写入。Group Replication实现了一个X-COM的通信层,其新版本中已经使用了Paxos算法。目前一个GR集群中最多可以有9个节点,响应延时相对稳定,在节点同步日志层面, GR使用binlog,相比Galera更加的通用。
Group Replication 为了保证能够多点写入,会传递WriteSet的信息,其他节点收到WriteSet后需要进行合法性验证,确保正确处理冲突事务。在测试中,我们发现为了支持多点写入而做合法性验证是一个非常明显的性能瓶颈点,除此之外,Group Replication还是着重解决局域网或者是同城下一致性问题,长传链路下基本没有做任何优化。我们在跨城场景下,使用官方5.7.17与RDS 5.7三节点企业版做了对比测试,GR的性能劣势非常明显,纯写入的性能只有RDS 5.7三节点企业版的五分之一,OLTP的性能也不足RDS 5.7三节点企业版的40%。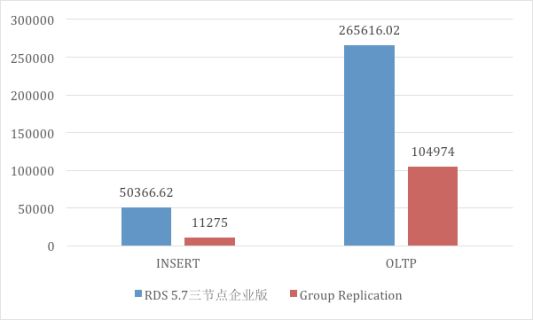
RDS 5.7三节点企业版是对阿里业务场景非常有效的数据库解决方案。RDS 5.7三节点企业版不仅能够享受到开源社区带来的红利,关键的技术也能够做到完全的自主、可控,能够针对业务的需求进行灵活的变更。未来 RDS 5.7三节点企业版会在此基础上做更多的优化、例如支持多分片的Paxos, Follower提供强一致读等功能。关于RDS 5.7三节点企业版在阿里集团内的应用,我们会在下一篇文章中详细展开。
本文作者:jixiang_zy
原文链接
本文为云栖社区原创内容,未经允许不得转载。