hadoop单机版配置
hadoop单机版配置
- 必要前置软件
- 安装HADOOP
- 纯单机版和伪分布式
必要前置软件
首先是jdk,因为hadoop是基于java编写的。
然后是ssh,因为需要使用远程启动hadoop的守护进程——是的,即使是单机版,也会在本机使用ssh远程操作。
安装HADOOP
我使用的是JDK1.8和HADOOP2.6.5
首先当然是解压下载的压缩包。然后在hadoop-2.6.5/etc/hadoop/hadoop-env.sh中修改
export JAVA_HOME=安装的jdk路径
export HADOOP_PREFIX=安装的hadoop路径
到了这一步,其实已经完成了安装,但是还有很多可以优化的地方。
纯单机版和伪分布式
hadoop有三种模式,一种是纯单机版,一种是伪分布式,最后一种就是完全分布式,前面两种都可以在单机版上实现。第一种纯单机版最简单,不需要做任何操作,直接cd hadoop-2.6.5进入根目录,然后就可以使用bin/hadoop命令
 那么这样,就显示安装成功了。
那么这样,就显示安装成功了。
可以使用以下命令:
$bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar wordcount /usr/local/apps/input.txt output
这一行命令是调用了hadoop自带的一个词频统计的实例程序,最后两个参数就是输入和输出,可以根据自身情况修改。
这是我的一个测试文件input.txt:
hello hello hello
wait wait
world
而第二种伪分布式,就是将hadoop以多进程的方式启动。
首先编辑etc/hadoop/core-site.xml
fs.defaultFS
hdfs://localhost:9000
编辑etc/hadoop/hdfs-site.xml
dfs.replication
1
设置好伪分布式后,需要在初次启动hadoop前进行初始化:
$bin/hdfs namenode -format
在启动之前,说一下之前安装的ssh,因为是伪分布式,所以启动每一个进程,例如namenode,都需要进行ssh,这里可以进行免密登陆,减少步骤,否则在启动namenode和datanode的时候都要输入密码
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
然后启动namenode和datanode:
$ sbin/start-dfs.sh
启动完成后,可以在浏览器上查看节点运行情况:http://localhost:50070/
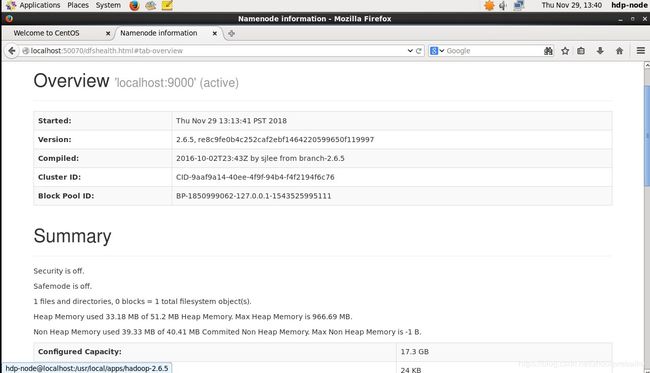 伪分布式同样可以使用hadoop自带的词频统计程序,但是首先要将文件上传到hdfs.需要注意的是,在hdfs上,会自动在/user/user name这个文件夹中寻找目标文件,因此,必须先创建这个文件:
伪分布式同样可以使用hadoop自带的词频统计程序,但是首先要将文件上传到hdfs.需要注意的是,在hdfs上,会自动在/user/user name这个文件夹中寻找目标文件,因此,必须先创建这个文件:
$ bin/hdfs dfs -mkdir /user
$ bin/hdfs dfs -mkdir /user/
创建文件夹当然需要一步步来,然后再上传文件。
$ bin/hdfs dfs -put input.txt /user/
同理,还需要创建一个output文件。
这样就能顺利执行以下命令了吗?
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar wodcount input.txt output
还不够啊,还需要启动yarn,首先需要更改一下设置:
etc/hadoop/mapred-site.xml:
mapreduce.framework.name
yarn
etc/hadoop/yarn-site.xml:
yarn.nodemanager.aux-services
mapreduce_shuffle
之后就可以启动yarn:
$ sbin/start-yarn.sh
同样的,启动后,可以在浏览器查看http://localhost:8088/:
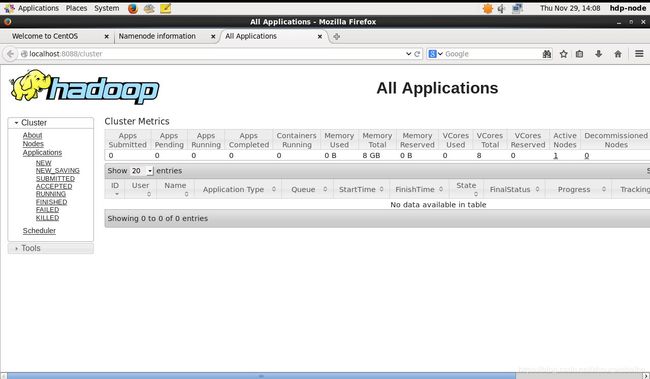 好了,现在就可以执行wordcount的命令了:
好了,现在就可以执行wordcount的命令了:
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar wordcount input.txt output
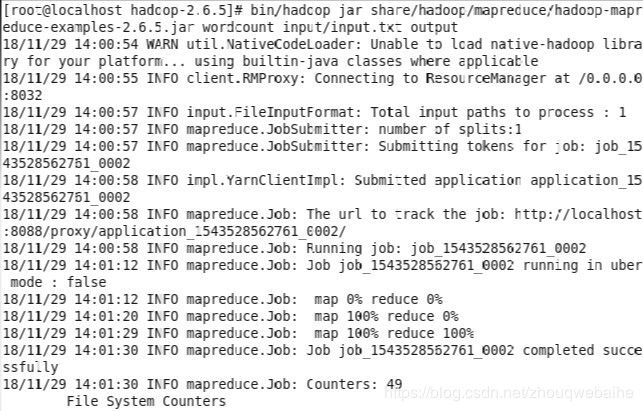 这是执行过程,完毕后可使用:
这是执行过程,完毕后可使用:
$ bin/hdfs dfs -get output output
$ cat output/*
或者
$ bin/hdfs dfs -cat output/*
进行查看
 最后说一下,java有一个比较实用的功能,就是jps,可以查看伪分布式的启动后的进程,当然,必须把jdk写进环境变量里。
最后说一下,java有一个比较实用的功能,就是jps,可以查看伪分布式的启动后的进程,当然,必须把jdk写进环境变量里。
以上内容来自hadoop的官方文档:https://hadoop.apache.org/docs/r2.6.5/hadoop-project-dist/hadoop-common/SingleCluster.html#Fully-Distributed_Operation