Hadoop第一篇:hadoop2.7.5单机版安装
Hadoop第一篇:hadoop2.7.5单机版安装
简介
Hadoop主要完成两件事,分布式存储和分布式计算。
Hadoop主要由两个核心部分组成:
1.HDFS:分布式文件系统,用来存储海量数据。
2.MapReduce:并行处理框架,实现任务分解和调度。
HDFS
是一个分布式文件系统,用来存储和读取数据的。
文件系统都有最小处理单元,而HDFS的处理单元是块。HDFS保存的文件被分成块进行存储,默认的块大小是64MB。
并且在HDFS中有两类节点:
1.NameNode和DataNode。
NameNode:
NameNode是管理节点,存放文件元数据。也就是存放着文件和数据块的映射表,数据块和数据节点的映射表。
也就是说,通过NameNode,我们就可以找到文件存放的地方,找到存放的数据。
DataNode:
DataNode是工作节点,用来存放数据块,也就是文件实际存储的地方。
客户端向NameNode发起读取元数据的消息,NameNode就会查询它的Block Map,找到对应的数据节点。然后客户端就可以去对应的数据节点中找到数据块,拼接成文件就可以了。这就是读写的流程。
作为分布式应用,为了达到软件的可靠性,如图上所示,每个数据块都有三个副本,并且分布在两个机架上。
这样一来,如果某个数据块坏了,能够从别的数据块中读取,而当如果一个机架都坏了,还可以从另一个机架上读取,从而实现高可靠。
我们从上图还可以看到,因为数据块具有多个副本,NameNode要知道那些节点是存活的吧,他们之间的联系是依靠心跳检测来实现的。这也是很多分布式应用使用的方法了。
我们还可以看到,NameNode也有一个Secondary NameNode,万一NameNode出故障了,Secondary就会成替补,保证了软件的可靠性。
HDFS具有什么特点呢?
1.数据冗余,软件容错很高。
2.流失数据访问,也就是HDFS一次写入,多次读写,并且没办法进行修改,只能删除之后重新创建
3.适合存储大文件。如果是小文件,而且是很多小文件,连一个块都装不满,并且还需要很多块,就会极大浪费空间。
HDFS的适用性和局限性:
1.数据批量读写,吞吐量高。
2.不适合交互式应用,延迟较高。
3.适合一次写入多次读取,顺序读取。
4.不支持多用户并发读写文件。
了解完了HDFS,就轮到MapReduce了。
MapReduce是什么:
MapReduce是并行处理框架,实现任务分解和调度。
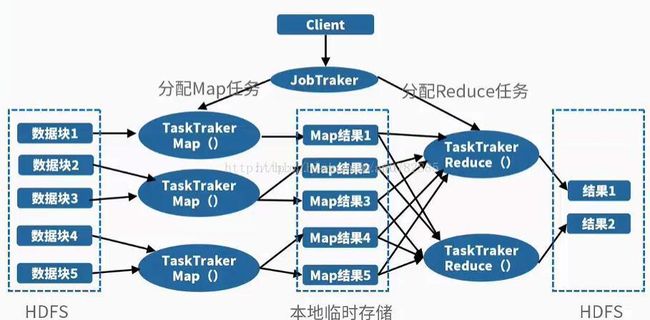
其实原理说通俗一点就是分而治之的思想,将一个大任务分解成多个小任务(map),小任务执行完了之后,合并计算结果(reduce)。
首先我们需要先知道几个小概念:
1.job 2.task 3.jobTracker 4.taskTracker
job:在Hadoop内部,用Job来表示运行的MapReduce程序所需要用到的所有jar文件和类的集合,>这些文件最终都被整合到一个jar文件中,将此jar文件提交给JobTraker,MapReduce程序就会执行。
task:job会分成多个task。分为MapTask和ReduceTask。
jobTracker:管理节点。将job分解为多个map任务和reduce任务。
作用:
1.作业调度
2.分配任务,监控任务执行进度
3.监控TaskTracker状态
taskTracker:任务节点。一般和dataNode为同一个节点,这样计算可以跟着数据走,开销最小化。
作用:
1.执行任务
2.汇报任务状态
在MapReduce中,也有容错机制。
1.重复执行。一个job最多被执行4次。
2.推测执行。因为Map全部算完之后才会执行Reduce,如果其中一个Map很慢,就会多开一个task来完成同样的工作,哪个执行的快用哪个。
参考资料
重新认识Hadoop
基础配置
基础环境:Centos7.0 JDK1.8
关闭防火墙:
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
修改hostname
sudo vim /etc/hosts
master master
JAVA JDK安装目录
/mnt/java-1.8.0-232
安装hadooop
wget http://archive.apache.org/dist/hadoop/common/hadoop-2.7.5/hadoop-2.7.5.tar.gz
tar -zxvf hadoop-2.7.5.tar.gz
mv hadoop-2.7.5 /mnt
配置环境变量
[root@localhost mnt]# vi /etc/profile
[root@localhost mnt]# source /etc/profile
export HADOOP_HOME=/mnt/hadoop-2.7.5
export PATH=$PATH:$HADOOP_HOME/bin
查看版本
[root@localhost mnt]# hadoop version
mkdir /mnt/hadoop
mkdir /mnt/hadoop/tmp
mkdir /mnt/hadoop/var
mkdir /mnt/hadoop/dfs
mkdir /mnt/hadoop/dfs/name
mkdir /mnt/hadoop/dfs/data
修改配置文件
修改配置文件cd /mnt/hadoop2.7.5/etc/hadoop/
core-site.xml
hadoop-env.sh
hdfs-site.xml
mapred-site.xml
core-site.xml
vim core-site.xml 在下添加如下配置文件
hadoop.tmp.dir
/mnt/hadoop/tmp
Abase for other temporary directories.
fs.default.name
hdfs://master:9000
说明: master可以替换为主机的IP(集群中多推荐hostname)
hadoop-env.sh
vim hadoop-env.sh
将${JAVA_HOME} 修改为自己的JDK路径
export JAVA_HOME=/mnt/jdk1.8
hdfs-site.xml
修改 hdfs-site.xml
在添加:
dfs.name.dir
/mnt/hadoop/dfs/name
Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.
dfs.data.dir
/mnt/hadoop/dfs/data
Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.
dfs.replication
2
dfs.permissions
false
need not permissions
mapred-site.xml
修改mapred-site.xml,如果没有此文件,则 mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
修改这个新建的mapred-site.xml文件,在节点内加入配置:
mapred.job.tracker
master:9001
mapred.local.dir
/mnt/hadoop/var
mapreduce.framework.name
yarn
Hadoop启动
第一次启动Hadoop需要初始化
切换到 /mnt/hadoop2.7.5/bin目录下
1.初始格式化
./hadoop namenode -format
初始化成功后,可以在/mnt/hadoop/dfs/name 目录下(该路径在hdfs-site.xml文件中进行了相应配置,并新建了该文件夹)新增了一个current 目录以及一些文件。
2.启动Hadoop
主要是启动HDFS和YARN
切换到/mnt/hadoop2.7.5/sbin目录
启动HDFS
输入:
start-dfs.sh
全程yes,输入密码
3.启动YARN
输入:
start-yarn.sh
可以输入 jps 查看是否成功启动
jps
57793 ResourceManager
57459 DataNode
57642 SecondaryNameNode
57355 NameNode
57885 NodeManager
57917 Jps
在浏览器输入:
http://master:8088/cluster
在浏览器输入:
http://master:50070
Hadoop启动命令汇总
1.第一种方式
启动:分别启动HDFS和MapReduce
命令如下:start-dfs.sh start-mapreted.sh
命令如下:stop-dfs.sh stop-mapreted.sh
2.第二种方式
全部启动或者全部停止
启动:
命令:start-all.sh
启动顺序:NameNode,DateNode,SecondaryNameNode,JobTracker,TaskTracker
停止:
命令:stop-all.sh
关闭顺序性:JobTracker,TaskTracker,NameNode,DateNode,SecondaryNameNode
3.第三种启动方式
每个守护线程逐一启动,启动顺序如下:
NameNode,DateNode,SecondaryNameNode,JobTracker,TaskTracker
命令如下:
启动:
hadoop-daemon.shdaemon(守护进程)
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datenode
hadoop-daemon.sh start secondarynamenode
hadoop-daemon.sh start jobtracker
hadoop-daemon.sh start tasktracker
关闭命令:
hadoop-daemon.sh stop tasktracker
hadoop-daemons.sh 启动多个进程
datanode与tasktracker会分不到多台机器上,从节点启动,就使用
HDFS常用命令
hdfs dfs -ls /
hdfs dfs -put file /
hdfs dfs -mkdir /dirname
hdfs dfs -text /filename
hdfs dfs -rm /filename
入门第一个程序WordCount
为了避免后面的测试出问题,请先修改如下配置
[root@localhost hadoop-2.7.5]# vi etc/hadoop/yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce_shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
修改后重启hadoop
输入源
创建数据
[root@localhost mnt]# mkdir input
[root@localhost mnt]# cd input/
[root@localhost input]# pwd
/mnt/input
[root@localhost input]# echo "hello world">test1.txt
[root@localhost input]# echo "hello hadoop">test2.txt
[root@localhost input]# cd /mnt/hadoop-2.7.5
提交数据源到HDFS
[root@localhost hadoop-2.7.5]# hadoop fs -mkdir -p /mnt/hadoop/input
[root@localhost hadoop-2.7.5]# hadoop fs -ls /mnt/hadoop/input
[root@localhost hadoop-2.7.5]# hadoop fs -put /mnt/input/* /mnt/hadoop/input/
[root@localhost hadoop-2.7.5]# hadoop fs -ls /mnt/hadoop/input
Found 2 items
-rw-r--r-- 2 root supergroup 12 2018-09-14 05:12 /mnt/hadoop/input/test1.txt
-rw-r--r-- 2 root supergroup 13 2018-09-14 05:12 /mnt/hadoop/input/test2.txt
运行程序
[root@localhost hadoop-2.7.5]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar wordcount /mnt/hadoop/input out
运行完成输出结果
[root@localhost hadoop-2.7.5]# hadoop dfs -cat out/*
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
hadoop 1
hello 2
world 1
单机安装参考资料
Hadoop2.8.2单机版安装
https://www.cnblogs.com/xuwujing/p/8017108.html
遇到的问题
auxService:mapreduce_shuffle does not exist
Container launch failed for container_1536843899378_0001_01_000003 : org.apache.hadoop.yarn.exceptions.InvalidAuxServiceException: The auxService:mapreduce_shuffle does not exist
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
处理方式
[root@localhost hadoop-2.7.5]# vi etc/hadoop/yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce_shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
重启hadoop
output already exists
除第一次运行外,每次运行时都会因为上次的运行产生一个输出路径,造成本次运行无法成功,因此需要手工删除该了路径才可以。
org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://master:9000/user/root/out already exists
at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:146)
at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:266)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:139)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1754)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1287)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1308)
at org.apache.hadoop.examples.WordCount.main(WordCount.java:87)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:71)
at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:144)
at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:74)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
处理方式:就是把提示端口号9000后面的那个路径删除既可,注意路径不同
[root@localhost hadoop-2.7.5]# ./bin/hadoop fs -rmr /user/root/out
rmr: DEPRECATED: Please use 'rm -r' instead.
18/09/14 06:09:26 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted /user/root/out
文档资料参考
https://blog.csdn.net/a60782885/article/details/71308256
Hadoop配置文件参数详解
https://blog.csdn.net/kingxuexi/article/details/54909452