NLP 作业:机器阅读理解(MRC)综述
最近自己会把自己个人博客中的文章陆陆续续的复制到CSDN上来,欢迎大家关注我的 个人博客,以及我的github。
本文主要是我的 NLP 作业——机器阅读理解的综述,内容很少涉及到模型的具体架构和相关理论的证明,而是注重于机器阅读理解发展历程,大体上有哪几类模型,并且讲解几个经典模型的特点以及它改进了之前模型的什么缺点。
目录
一、机器阅读理解概述
-
- 机器阅读理解的常见任务
-
- 经典的机器阅读理解基本框架
-
- 机器阅读理解的发展历程
二、 经典机器阅读理解模型
-
- Match-LSTM
-
- BiDAF
-
- QA-Net
-
- BERT
-
- ALBERT
三、机器阅读理解的研究趋势
-
- 基于外部知识的机器阅读理解
-
- 带有不能回答的问题的机器阅读理解
-
- 多条文档机器阅读理解
-
- 对话式阅读理解
参考文献
一、机器阅读理解概述
所谓的机器阅读理解(Machine Reading Comprehension, MRC)就是给定一篇文章,以及基于文章的一个问题,让机器在阅读文章后对问题进行作答。
1. 机器阅读理解的常见任务
MRC 的常见任务主要有四个:完形填空、多想选择、片段抽取和自由作答(Danqi Chen. Neural Reading Comprehension and Beyond. PhD thesis, StanfordUniversity, 2018.)
(1)完形填空
任务定义:将文章中的某些单词隐去,让模型根据上下文判断被隐去的单词最可能是哪个。
(2)多项选择
任务定义:给定一篇文章和一个问题,让模型从多个备选答案中选择一个最有可能是正确答案的选项。
(3)片段抽取
任务定义:给定一篇文章和一个问题,让模型从文章中抽取连续的单词序列,并使得该序列尽可能的作为该问题的答案。
(4)自由作答
任务定义:给定一篇文章和一个问题,让模型生成一个单词序列,并使得该序列尽可能的作为该问题的答案。与片段抽取任务不同的是,该序列不再限制于是文章中的句子。

这四个任务构建的难易程度越来越难,对自然语言理解的要求越来越高,答案的灵活程度越来越高,实际的应用场景也越来越广泛。
2. 经典机器阅读理解的基本框架
主要包括嵌入编码(Embedding)、特征抽取(Feature Extraction、Encode)、文章-问题交互(Context-Question Interaction)和答案预测(Answer Prediction)四个模块。
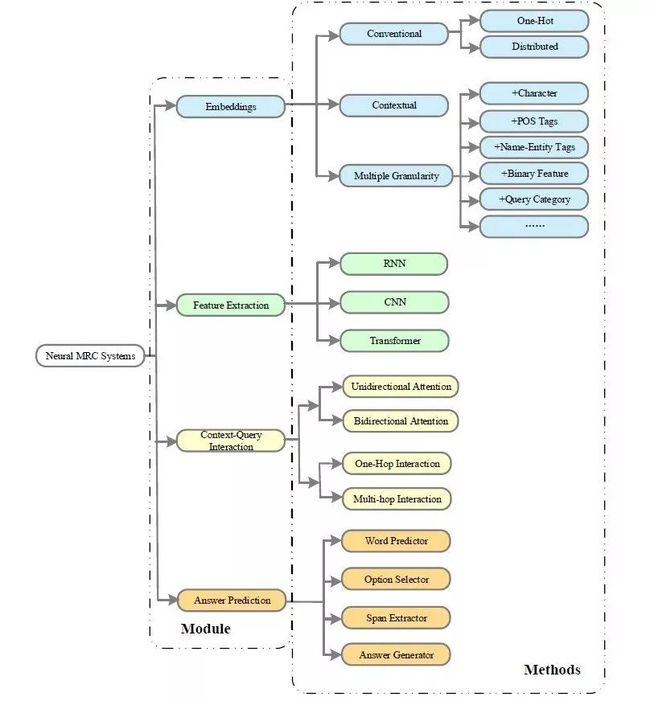
(1)嵌入编码
将自然语言形式的文章和问题转化为固定维度的向量,以便让机器进行处理。常见的编码方式有 one-hot 表示、分布式词向量以及最近的 ELMo、GPT 和 Bert等。
(2)特征提取
提取上下文信息,这一模块中常用的神经网络模型有:RNN、CNN和基于多头自注意力机制的Transformer结构。
(3)文章-问题交互
利用文章和问题之间的交互信息来推测出文章中那些部分对于回答问题更为重要。该模块通常采用单向或双向的注意力机制来强调原文中与问题更为相关的部分。同时为了更深层次的挖掘文章和问题之间的关系,两者之间的交互可能会重复多次。
(4)答案预测
该模块基于上述三个模块累积得到的信息进行最终的答案预测。该模块是高度任务相关的。对于完形填空任务,答案输出是原文中的一个词或实体,一种做法是将文中相同词的注意力权重得分进行累加,最终选择得分最高的词作为答案 [23];对于多项选择任务,是从多个候选答案中挑选出正确答案,一般是对备选答案进行打分,选择得分最高的候选者作为答案;对于片段抽取任务,从原文中抽取一个连续的子片段作为答案,常用方法是 (Wang S, Jiang J. Machine comprehension using match-lstm and answer pointer[J].arXiv preprint arXiv:1608.07905, 2016.) 提出的预测答案开始和结束位置的概率的边界模型;对于自由作答任务,答案灵活度最高,不再限制于原文中,可能需要进行推理归纳,现有的方法常用抽取和生成相结合的模式。
3. 机器阅读理解的发展历程
2016年以前主要是统计学习的方法,2016年在 SQuAD 数据集发布之后,出现了一些基于注意力机制的匹配模型,如 match-LSTM 和 BiDAF 等。2018年之后浮现了各种预训练语言模型,如 BERT 和 ALBERT 等。
机器阅读理解数据集的发展极大的促进了机器阅读理解能力的发展,其中 SQuAD 是斯坦福大学推出的一个关于机器阅读理解的数据集,在2018年,斯坦福大学 NLP 团队又更新了该数据集的 2.0 版本,在新版本的数据集中加入了部分没有答案的问题。
下图中蓝色的是比较重要的几个模型,当然这只是一部分,不全。

二、经典的机器阅读理解模型
前面提到过,机器阅读理解模型主要可以分为基于机器学习的、基于注意力机制的,以及基于预训练的。由于基于机器学习的模型效果都比较差,出现的时间也是较早之前了,所以下面只介绍基于注意力机制的几个经典模型—— match-LSTM、BiDAF 和 QA-Net,以及基于预训练的经典模型—— BERT 和 ALBERT。
1. match-LSTM
该模型整合了 match-LSTM 和 Pointer-Net 两个模块,前者也是该作者提出的,但是用于文本蕴含任务。后者可以让预测答案中的单词来源于原文,而不是一个固定长度的词汇表。
在经典的 match-LSTM 中输入有两个,一个是前提(premise),另一个是假说(hypothesis)。其目的是判断根据前提是否能推断出假说。这里可以将问题看作是前提,把文章看作是假说,这样做相当于带着问题去文章中寻找答案。这解决了原文和问题的匹配问题。
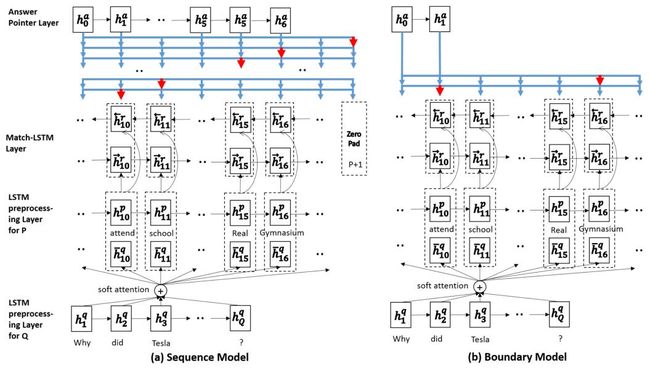
Pointer-Net 用于从原文中选取答案,这里又提出了两种预测答案的模式:
- 序列模型(Sequence Model):不做连续性假设,预测答案存在与原文的每一个位置;
- 边界模型(Boundary Model):直接预测答案在原文中起始和结束位置。相比于序列模型加快了速度,并且效果更好。因此后来的模型普遍使用边界模型来进行答案范围的预测。
以上两个模块都运用了注意力机制,match-LSTM 模块使用注意力机制来计算文章中第 i 个 token 和问题中第 j 个 token 的匹配程度。Pointer-Net 模块使用注意力机制来预测位置。
2. BiDAF
BiDAF 是 Bi-Directional Attention Flow(双向注意力流)的缩写。在该模型之前的注意力机制大致有三个特点:
- 如前面提到的 match-LSTM 模型,它们通常都是单向的从问题到文本的注意力权重;
- 注意力权重通常通过将上下文概括为固定长度的向量,进而从上下文中提取强相关信息用来回答问题;
- 在文本域中,注意力权重通常在时间上是临时动态的,其中当前时间步的注意权重是前一时间步参与向量的函数。
而 BiDAF 的贡献主要有:(1) 采用了双向的注意力机制 (2) 采用了多粒度结合的编码方式

BiDAF 的注意力机制特点如下:
-
计算了 query-to-context ( Q2C ) 和 context-to-query ( C2Q ) 两个方向的注意力信息,认为 C2Q 和 Q2C 实际上能够相互补充。
-
BiDAF 并不是将文本总结为一个固定长度的向量,而是将向量流动起来,以便减少早期信息加权和的损失;
-
Memory-less,在每一个时刻,仅仅对问题和当前时刻的上下文进行计算,并不直接依赖上一时刻的注意力,这使得后面的注意力计算不会受到之前错误的注意力信息的影响;
多粒度结合的编码方式:网络的前三层分别对字符(character)、单词(word)和上下文(context)进行嵌入编码,也就是具有多层级不同粒度的表征编码器。
3. QA-Net
在 QA-Net 之前的网络的关键技术主要有 RNN 模型和注意力机制。但是由于 RNN 的存在,所以模型的训练和推断速度都比较慢。QA-Net 就使用了卷积来代替传统的 RNN 结构,并采用了多种技巧(trick),较大的提高了模型的训练和推断速度,并保证了模型的精度。该模型中卷积用来捕获文本的局部信息,注意力用来学习每对单词之间的全局交互。

该模型还提出了新型的数据增强(data augment)技术 ,这种技术类似于CV中的数据增强技术。即先将原始句子从英语转化为其他语言,然后再将其转化回英语。这样的优点是可以增加可以使用的数据量。

该模型还使用了较多的技巧来减少参数、提升模型的速度,主要有:深度可分离卷积、层正则化、自注意力机制等。
深度可分离卷积
如果卷积核大小是 3 × 3 3\times 3 3×3,输入图像的通道数是5,输出图像的通道为10,则普通的卷积会在每个通道上设置一个 3 × 3 3\times 3 3×3 卷积核,与对应的通道做完卷积后相加得到输出图像中的一个通道。用 10 组 4通道 × ( 3 × 3 ) \times(3\times3) ×(3×3) 卷积核重复以上过程,就得到了要求的 10 通道的图像。

如上图所示,而深度可分离卷积将以上过程拆分为了两个子过程,先用 4通道 × ( 3 × 3 ) \times(3\times3) ×(3×3) 卷积核在每个通道上做卷积,得到 4 通道的图像,然后用 10 组大小为 1 × 1 1\times 1 1×1,通道为 4 的卷积核与 4 通道的图像做卷积,得到最终 10 通道的输出图像。
这种卷积方式的优点是大大的降低了参数的数量,从而加快了模型的速度。
层正则化
类似于 batch normalization,因为数据在网络中每经过一层,其分布会发生变化,这会导致模型训练的收敛比较慢。layer norm 可以通过调整输出数据的均值和方差,让输出值符合一定的分布,从而减少训练时间。
自注意力机制
使用了 Multi-Head Attention(《Attention is all you need》),也就是 Attention 做多次然后拼接,类似于先用不同大小的卷积核分别做卷积,然后拼接。
4. BERT
BERT 是 Bidirectional Encoder Representations from Transformers 的缩写,即来自 Transformer 的双向编码器表示,其中 Transformer 是另一种模型结构,BERT 就是在这种模型的基础上提出的。BERT 的最大特点是用遮蔽语言模型来利用上下文信息并使用自监督数据进行训练,并使用“next sentence prediction”任务来捕获句子之间的关系,此外用预训练(pre-train)加微调(fine-tune)的方式增强模型的泛化能力。
预训练+微调

预训练+微调就是先对模型的上层结构进行参数的预训练,然后根据任务的不同改变网络的下层结构,并对上层参数进行微调,这样可以使得模型的泛化能力更强,并且训练所需要的时间也得到了缩减。
在将预训练好的语言表达应用到下流任务有两种策略:(1) 基于特征的方法,即在处理不同的任务时,将预训练得到的表达作为附加特征 (2) 微调的方法,只引入少量需要从头开始训练的参数,其他参数只需要在预训练模型的基础上简单微调。
遮蔽语言模型
对于字符(token)级的任务来说,以上两种方式都限制了模型充分的结合上下文信息。同时 BERT 的参数非常多,所以需要大量的训练数据,为了解决该问题,BERT 使用了遮蔽语言模型(masked language model, MLM)。这种模型收到了完形填空的启发,它会随机的遮蔽输入中的某些 token,并让模型根据上下文去预测被遮蔽的 token 是什么。这使得表达能够混合上下文信息并且可以充分地利用无监督(自监督)的数据来进行训练。
但是 MLM 又带来了两个问题,一是造成了预训练和微调过程的不匹配,因为 [mask] 标志在微调过程中并不存在(预训练过程使用的是mask过的无监督数据,而微调过程使用的是有监督的真实数据),为了解决该问题,并不总是真的用 [mask] 标记来替换被选择的单词,而是在一定概率下不替换或者换成其他随机选取的单词。第二个问题是因为只有部分数据(而不是全部的数据)被标记为 [mask] 并需要预测,所以需要更多的训练时间(需要更多的batch来训练),但是这与所带来的效果相比是值得的。
预测下一个句子
另外某些任务是基于对两个句子之间关系的理解的,但是这并不能由语言模型直接捕获。这可以用“预测下一个句子(NSP)”的任务来解决,输入的两个句子 A 和 B,B 有一半的几率是 A 的下一句,另一半的几率是随机的句子。用模型来预测 B 是不是 A 的下一句话,从而让模型能够捕获句子之间的关系。
BERT 模型提出后,在11种文本挖掘任务中取得了当时最好的结果,并且对之前的最好的模型有很大的提升,被广泛认为是一个具有里程碑意义的模型。
5. ALBERT
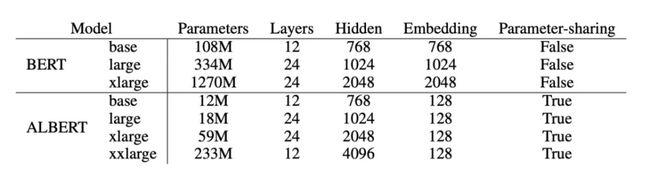
ALBERT 是 A Lite BERT 的缩写,是一个轻量级的 BERT 模型,到目前为止(2019.11.8),它在 SQuAD2.0 数据集上达到了最好的效果。其最大的特点是参数少、速度快。

ALBERT 结合了两种参数约简(parameter reduction)技术:
- 第一个技术是对嵌入参数进行因式分解(factorized embedding parameterization)。通过将大的词汇表嵌入矩阵分解为两个小的矩阵,将隐藏层的大小与词汇表嵌入的大小分离开来。这种分离使得在不显著增加词汇表嵌入的参数大小的情况下,更容易增加隐藏层大小。
- 第二种技术是跨层参数共享(cross-layer parameter sharing)。这种技术可以防止参数随着网络深度的增加而增加。
下图是 BERT 和 ALBERT 模型参数的对比:
由于 BERT 中基于 NSP 任务的损失效果并不好,所以 ALBERT 还引入了基于预测句子顺序(sentence-order prediction, SOP)的预训练损失,SOP 主要聚焦在句子的句内连贯性。
三、机器阅读理解的研究趋势
1. 基于外部知识的机器阅读理解
在人类阅读理解过程中,当有些问题不能根据给定文本进行回答时,人们会利用常识或积累的背景知识进行作答,而在机器阅读理解任务中却没有很好的利用外部知识。
其挑战有:(1) 相关外部知识的检索 (2) 外部知识的融合
2. 带有不能回答的问题的机器阅读理解
机器阅读理解任务有一个潜在的假设,即在给定文章中一定存在正确答案,但这与实际应用不符,有些问题机器可能无法进行准确的回答。这就要求机器判断问题仅根据给定文章能否进行作答,如若不能,将其标记为不能回答,并停止作答;反之,则给出答案。
其挑战有:(1) 不能回答的问题的判别 (2) 干扰答案的识别
3. 多条文档机器阅读理解
在机器阅读理解任务中,题目都是根据相应的文章进行设计的。而人们在进行问答时,通常先提出一个问题,再利用相关的可用资源获取回答问题所需的线索。不再仅仅给定一篇文章,而是要求机器根据多篇文章对问题进行作答。
其挑战有:(1) 相关文档的检索 (2) 噪声文档的干扰 (3) 检索得到的文档中没有答案 (4) 可能存在多个答案 (5) 需要对多条线索进行聚合
4. 对话式阅读理解
当给定一篇文章时,提问者先提出一个问题,回答者给出答案,之后提问者再在回答的基础上提出另一个相关的问题,多轮问答对话可以看作是上述过程迭代进行多次。
其挑战有:(1) 对话历史信息的利用 (2) 指代消解
参考文献
[1] Shanshan Liu et al. Neural Machine Reading Comprehension: Methods and Trends. Applied Sciences 2019
[2] Tian Tian et al. Teaching Machines to Read and Comprehend. NIPS 2015
[3] Shuohang Wang et al. Machine Comprehension Using Match-LSTM and Answer Pointer. ICLR 2016
[4] Minjoon Seo et al. Bidirectional Attention Flow for Machine Comprehension. ICLR 2017
[5] Adams Wei Yu et al. QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension. ICLR 2018
[6] Ashish Vaswani et al. Attention Is All You Need. NIPS 2017
[7] Jacob Devlin et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL. 2019
[8] Zhenzhogn Lan et al. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. arXiv 2019
[9] Danqi Chen. Neural Reading Comprehension and Beyond. StanfordUniversity. 2018