用Django全栈开发(进阶篇)——02. 在Django中花样玩转PyMongo(上)
大家好,这是皮爷给大家带来的最新的学习Python能干啥?之Django教程的进阶版。
在之前《用Django全栈开发》系列专辑里面,皮爷详细的阐述了如何编写一个完整的网站,具体效果可以浏览线上网站:Peekpa.com
从进阶篇开始,每一篇文章都是干货满满。这一节,我们来讲述一下,在Django中,如何花式玩转pymongo。pymongo如何模糊查询,排序
Peekpa.com的官方地址:http://peekpa.com
皮爷的每一篇文章,都配置相对应的代码。这篇文章的代码对应的Tag是“Advanced_02”。

前瞻回顾
在上一节《用Django全栈开发(进阶篇)——01. 如何让Django连接MongoDB》,我们主要讲述了如何使用Django连接MongoDB数据库,并从里面读取数据的方法。
整体浏览
本文大概将会讲述以下内容:
- 基本的增删改查;
- 修改器的应用
由于内容很多,所以分开文章来说。接下来,就由我来给大家讲述以下如何玩转PyMongo。其实你只要会玩了PyMongo,MongoDB也就基本会个80%了,因为这俩差不多的。不信,你瞧。
插入
插入,非常的简单,PyMongo提供的插入函数主要有两个:
self.collection.insert()
self.collection.insert_many()
这里,insert()主要是插入单个数据,插入的内容为字典类型的数据即可。
insert_many()则是插入一组数据,一个数组,里面存放的是字典类型的数据。
具体可参考的代码,是我当初创建地震数据库信息的时候。从核心数据库读取的100条数据,然后直接调用insert_many()方法插入到新的数据库中。
查找
我们在上一篇的例子中,将100条地震信息全部显示,通过的是一条:
list_data = self.collection.find()
来找到的。这个显然是返回了全部的数据。可以看到,如果调用count()方法,返回的数据是100:
count = list_data.count()
print(count)
#结果出入的是:100
这里要注意一下,这个.count()是PyMongo里面的方法,这个和MongoDB里面的.count()是一样的,返回的是cursor的结果数目。
接下来,我们来介绍一下关于搜索更加丰富的用法。
指定搜索条件精确查找
在实际开发中,很多情况,我们并不需要将全部数据都返回,可能只需要返回符合条件的特定数据,比如某天的数据,比如某个ID的数据,这种数据精确查找。
我们页面顶部右侧有个搜索输入框,我们就来通过这个给大家展示一下条件搜索怎么做:

这的搜索,我们主要是以地名为关键字的搜索。
首先,我们来到front/template/datacenter/jpearth/manage.html里面,来确认一下这个form是什么形式发送的关键字:
<form action="" method="get" class="form-inline ml-auto">
<div class="form-group mr-4">
<label for="title-input">标题:label>
<input type="text" class="form-control" name="search" id="title-input" placeholder="关键字">
div>
<div class="form-group mr-4">
<button class="btn btn-primary">查询button>
div>
form>
看到这里在form标签里面,是个get请求。判断http://127.0.0.1:8000/jpearth/这个url是正常的显示全部还是说搜索,关键就在于url后面有没有跟search参数。而这个参数就是在上面的这个input标签里面,因为它的name是search。
这下子就简单多了,我们只需要接着修改我们前一节的JpEarthView里面的get函数就可以了。
# 解析url,提取出来url里面的变量
def process_paramter(self, request):
search_key = request.GET.get('search')
handle_type = self.TYPE_ALL if search_key is None else self.TYPE_SEARCH
return handle_type, search_key
# 通过传入的变量,来区分是全部搜索还是精确搜索
def get_data_from_db(self, handle_type, search_key):
if handle_type == self.TYPE_ALL:
result = self.collection.find()
else:
# 通过地址(jp_location)精确查找
result = self.collection.find({"jp_location": search_key})
return list(result)
这个时候我们来实验一下前端是否能够精确的搜索,我们以地名福島県沖为例:
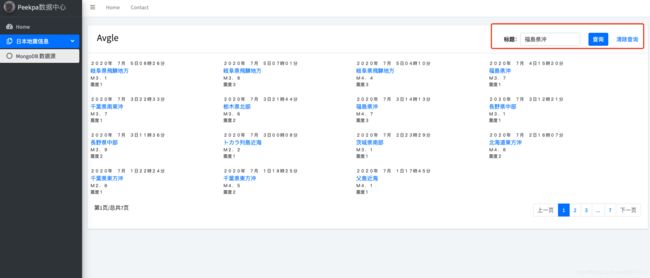
然后点击查询,看到结果如下:
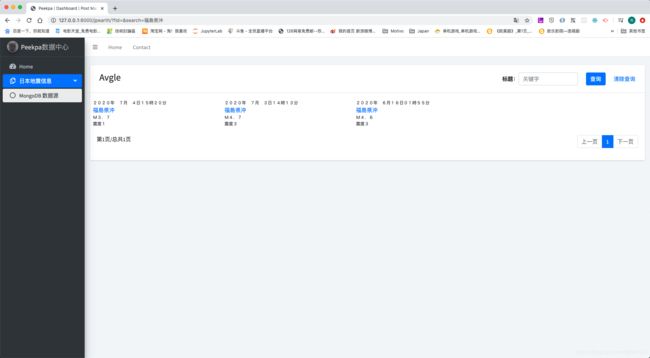
可以看到结果正确,并且注意到上面的URL地址变成了http://127.0.0.1:8000/jpearth/?fid=&search=福島県沖,说明和我们之前预想的完全一致。
但是,这个是精确查找,当我们在关键字地方输入南部的时候,我们希望得到类似福島県沖这样的信息,可是我们得到的确实以下信息:
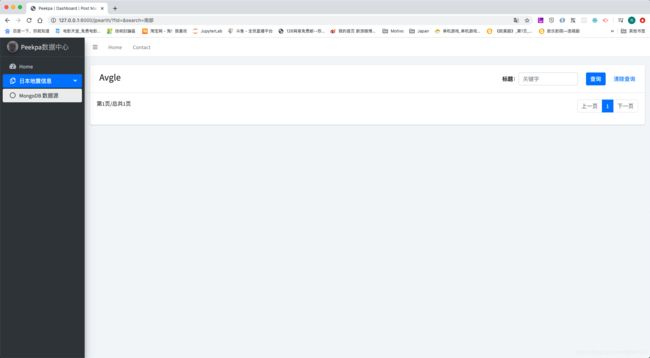
返回结果为0。这个就是精确查找带来的不便之处。接下来我们来做模糊查找。
指定搜索条件模糊查找
如果我们按照地名的模糊查找也非常好办。只需要将之前的get_data_from_db()函数里面的search方法稍作修改就可以:
def get_data_from_db(self, handle_type, search_key):
if handle_type == self.TYPE_ALL:
result = self.collection.find()
else:
# 通过地址(jp_location) 精确查找
#result = self.collection.find({"jp_location": search_key})
# 通过地址(jp_location) 模糊查找
result = self.collection.find({"jp_location": {'$regex': ".*" + search_key + ".*"}})
return list(result)
可以看到,我们这里将原来的search_key替换成了{'$regex': ".*" + search_key + ".*"}。这个是使用正则表达式来做的包含处理,
因为MongoDB的搜索支持正则表达式,所以我们这里使用一个正则表达式的方法来做QuerySet中的contains处理,方便又快捷。
实际测试一下效果,看看这回南部会不会显示出来正确的结果:

完美,南部也显示出来。
接下来就友会有人疑问,如果我想组合查找呢?
就比如线上Peekpa.com中的数据中心:
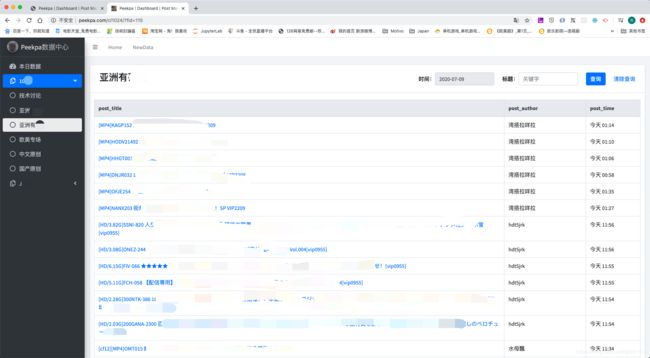
比如番号的搜索,可能有大写,也有小写的,我希望输入一个小写的番号,能够返回来的信息既有大写的番号,也有小写的番号。这该怎么做?
指定搜索条件组合查找
这种组合查找,不难,我们需要修改的还是那个get_data_from_db()函数:
query_set = [{"post_title": {'$regex': ".*" + search_key + ".*"}},
{"post_title": {'$regex': ".*" + search_key.lower() + ".*"}},
{"post_title": {'$regex': ".*" + search_key.upper() + ".*"}}]
result = self.collection.find({"$or": query_set})
可以看到这么几个关键的知识点:
- 创建了一个query_set,里面是一个list。list里面分别放的就是我们之前模糊条件搜索的条件:
{"post_title": {'$regex': ".*" + search_key + ".*"}}
变化的只是'$regex':后面的内容。
- 在
find()方法里,我们使用:{"$or": query_set}让PyMongo条件搜索。这里的关键字是$or,这样就是或的关系。 - 如果想使用
且的关系,直接的列出条件就好,如下:
self.collection.find({"age":{"$gt":22}, "name":{"$regex":"user"}})
这样,我们搜索一个番号,就能出来即使大写的,又是小写的结果:
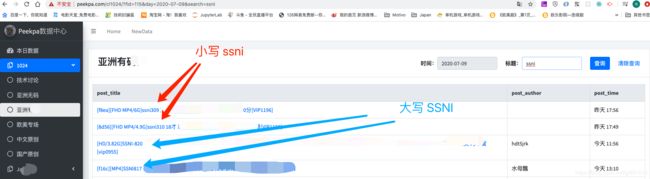
搜索结果排序
接下来,我们就是想要实现搜索结果排序了。我们如果直接只调用find()方法,那么找出来的顺序是按照MongoDB的_id来排序的。如果想要实现结果排序,很简单:在find()后面添加sort(id, order)方法即可,这其中id为要排序的id name,order则是升序还是降序。
比如我们要实现地震信息升序排列,因为我们默认的数据是降序的(数据添加顺序导致),所以我们升序排列的话,就要将原有的方法修改成下面的样子:
def get_data_from_db(self, handle_type, search_key):
if handle_type == self.TYPE_ALL:
# 搜索全部结果
#result = self.collection.find()
# 降序排列
#result = self.collection.find().sort('jp_time_num', pymongo.DESCENDING)
# 升序排列
result = self.collection.find().sort('jp_time_num', pymongo.ASCENDING)
else:
# 通过地址(jp_location) 精确查找
#result = self.collection.find({"jp_location": search_key})
# 通过地址(jp_location) 模糊查找
result = self.collection.find({"jp_location": {'$regex': ".*" + search_key + ".*"}})
return list(result)
看到:
- pymongo.ASCENDING:升序
- pymongo.DESCENDING:降序
我们开看一下,发现我们换成了pymongo.ASCENDING之后,地震结果是升序排列的:
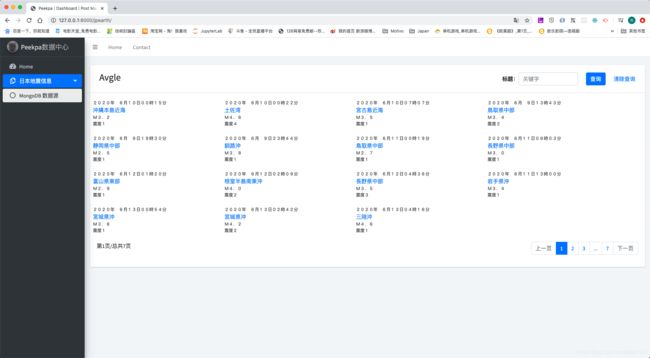
搜索返回指定字段
大部分时候,我们的搜索想返回指定字段,因为如果数据模型太过庞大,每回搜索都返回全部内容,前端的数据量肯定会崩溃的,所以想要做只返回指定字段的类型,这个也很简单,只需要在find()方法里面,再添加需要返回字段的id就可以。
比如我们只需要返回地震地点和地震发生时间的信息,我们需要把find()方法修改成以下样子:
# 只返回 地震地点 还有 地震时间
result = self.collection.find({},{'jp_title', 'jp_location'})
可以看到,这里find()第一个参数为{},我们在第二个参数里面才设置的需要返回的字段,再来看一下后台和前端的结果:
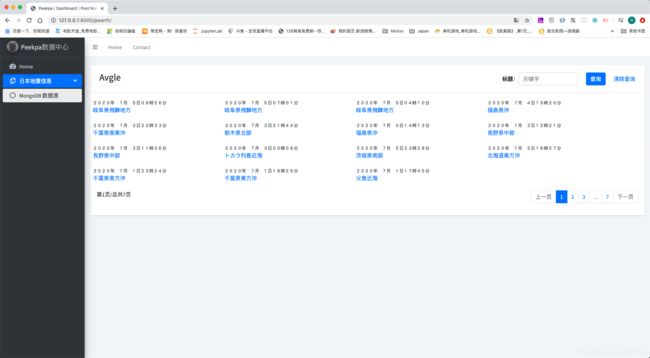
后台看到,返回的只有_id,jp_title和jp_location这三个字段:
但是,这里就有个问题:如果有些字段你不想返回呢?这又该怎么做。比如这里,我们不想返回jp_title和jp_location字段,很简单,find方法这么写:
# 不 返回 地震地点 还有 地震时间
result = self.collection.find({},{'jp_title':False, 'jp_location':False})
只要将第二个参数,变幻成字典形就可以,将不想返回的字段,值设置成False就可以。
我们看一下前端和后台的效果:

后台:

是不是非常的简单易懂?
单一查找
上面讲述的collection.find()方法,返回的是一个Cursor,但是它的查询结果是一个数组。如果要单一查找,我们只需要使用:
collection.find_one()
具体里面的参数,和上面find()方法是一样的。这里就简单的给大家做个演示: 我们查找 jp_location为福島県沖的数据:
result = self.collection.find_one({"jp_location":"福島県沖"})
print(result)
#{'_id': ObjectId('5f002078601bd55f57ca2130'), 'jp_create_time': '2020-7-4-14-23-52', 'jp_url': 'http://www.jma.go.jp/jp/quake/20200704062249395-04152004.html', 'jp_title': '2020年\u30007月\u30004日15時20分', 'jp_id': '2020070406224939504152004', 'jp_time_num': '2020-07-04-15-20-04', 'jp_location_image_url': 'http://www.jma.go.jp/jp/quake/images/japan/20200704062249395-04152004.png', 'jp_location': '福島県沖', 'jp_level': 'M3.7', 'jp_max_level': '震度1', 'jp_time_text': '\u30007月\u30004日15時22分'}
可以看到,这条结果result其实就已经是一个单个的数据了,并不是数组。好了,今天的内容其实很多了,我们来总结一下。
技术总结
最后总结一下,
如何玩转PyMongo:
- 首先好好阅读文章,文章里面有生动的例子,和配套的代码,还有代码运行结果的配图,简直不要太VIP;
- PyMongo的插入有两个方法:
insert()和insert_many(),分别对应的是单个插入和群体插入,怎么这么怪怪的; - PyMongo的查找,也是有两种:
find()和find_one(),分别是结果群体查找和结果单个查找; - 在查找的时候,可以传入精确的变量进行精确查找,也可以把条件组合起来;
- 最后结果还支持排序;
- 进阶篇的**玩转PyMongo(上)**总结完毕。
获取代码的唯一途径:关注『皮爷撸码』,回复『代码』即可获得。
长按下图二维码关注,如文章对你有启发或者能够帮助到你,欢迎点赞,在看,转发三连走一发,这是对我原创内容输出的最大肯定。
