Hadoop高可用搭建部署测试
同步时间
date -s "2019-8-22 09:36:15"
实现从机到主机之间互相通信
ssh免密钥(本机生成)
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
分发密钥到主机(并重命名区分 避免覆盖)
scp id_dsa.pub bigdata01:`pwd`/bigdata02.pub
主机把从机发送的bigdata02的公钥追加到认证文件里:
cat ~/.ssh/bigdata02.pub >> ~/.ssh/authorized_keys
修改hdfs.xml,删除原先的SecondNamenode配置,增加以下
修改core-site.xml配置
增加
分发hdfs-site.xml和core-site.xml给其他节点
scp core-site.xml hdfs-site.xml bigdata02:`pwd`
在2\3\4datanode中添加zookeeper包
tar -zxvf zookeeper-3.4.6.tar.gz -C /opt/modules/
进入zookeeper修改conf配置文件
mv zoo_sample.cfg zoo.cfg
修改
dataDir=/opt/modules/zookeeper
增加
server.1=bigdata02:2888:3888
server.2=bigdata03:2888:3888
server.3=bigdata04:2888:3888
分发zookeeper给其他节点
scp -r zookeeper-3.4.6/ bigdata03:`pwd`
给三台节点新建文件夹
mkdir -p /opt/modules/zookeeper
添加可识别myid,每台机字数字不一样 代表编号
echo 1 > /opt/modules/zookeeper/myid
配置环境变量
vi /etc/profile
export ZOOKEEPER_HOME=/opt/modules/zookeeper-3.4.6
PATH=$PATH:$ZOOKEEPER_HOME/bin
分发/etc/profile给其他节点
scp /etc/profile bigdata03:/etc/
source /etc/profile
启动zookeeper
zkServer.sh start
开启的机子中,编号大的为leader,其余为follower
1\2\3台机启动journalnode(同步数据)
hadoop-daemon.sh start journalnode
主namenode节点格式化:
hdfs namenode -format
启动格式化后的主节点:
hadoop-daemon.sh start namenode
把主节点的信息拷贝到当前节点的信息(journalnode要启动):
hdfs namenode -bootstrapStandby
同步成功,会发现同步另一个nn节点的clusterID 不是秘钥分发,而是同步过来的
格式化zkfc,在zookeeper中可见目录创建 :
hdfs zkfc -formatZK
进入zookeeper客户端:
zkCli.sh
启动hdfs集群:
start-dfs.sh
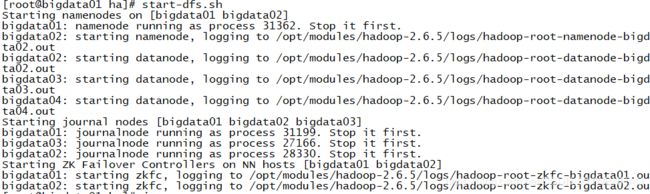
手动把nn1设置为active
$ bin/hdfs haadmin -transitionToActive nn1
上传文件到nn1,然后将nn1切换为Standby
将nn2切换为Active,然后查看HDFS文件
手动切换回standby:
$ bin/hdfs haadmin -transitionToStandby nn1
注意:但是在DFSZKFailoverController的监控下,无法执行,需要停止之后才可以执行
爬坑经历:DFSZKFailoverController好多次都没有起来,在配置的时候注意要顶格写,最好在linux下直接编写,不要通过notepad进行。tab不可以用s多个空格替代。
集群启动顺序:zkServer.sh start ---> start-dfs.sh