python 爬虫
Python 爬虫教程(更新中)
目录
1. 简介
2. 注意
3. xpath+selenium
4. xpath+scarpy(更新中)
1. 简介
爬虫主要有2种方式:API(报文)-静态、点击形式-动态;
Xpath + Scrapy(API 静态 爬取-直接post get) or Xpath + selenium(点击 动态 爬取-模拟)
Xpath风格可以获取所有的内容,所有的网站都是按照 tree 的形式,那么xpath可以逐层(有条理)分析,再结合各个框架进行分析爬取数据;xpath也可以用re beautifulsoup解析,但xpath更好,xpath教程(百度一下很多);
selenium只是点击形式,因此对应很多header参数可不需要,对于不懂互联网底层原理的人也是比较容易上手的,当然前提是你掌握一点html知识即可!而scrapy则需要很多参数进行设置,进行post get分析(具体我也不是很懂)
xpath一般在浏览器中使用:F12,点击左上角小箭头,查看对应的html标签,然后在console中输入$x('')查看
在scrapy中,可在cmd中输入scrapy shell "http:/***",采用response.xpath(‘//div’)进行查看\
进一步,对于异步加载ajax,通过network点击你想要操作的,然后可以看到相应的信息(百度一下F12对应的信息介绍)
2. 注意
(1)断点续爬;(2)代理(淘宝);(3)sleep一段时间继续;。。。
3. xpath+selenium
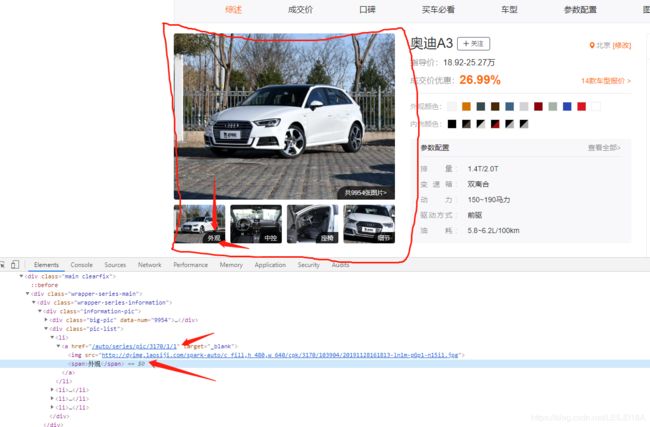
(1) 以老司机车辆爬取为例:(先下载对应的浏览器驱动-百度一搜很多,放入浏览器安装目录,并添加到环境变量Path中)
实现如下功能:1)点开新标签页,关闭新标签页;2)下拉鼠标滑轮,全部加载图片;3)下载保存图片
未实现:当窗口小时,二维码和图片重叠显示,点击容易报错,暂时放大窗口解决!
from selenium import webdriver #浏览器驱动
from selenium.webdriver.common.action_chains import ActionChains # 鼠标实例化
import urllib # 根据具体的url下载图片
import time
import uuid
import os
laosij_link = 'https://www.laosiji.com/'
driver = webdriver.Chrome()
driver.get('https://www.laosiji.com/auto/index')
all_makes = driver.find_element_by_xpath('//div[@id="auto-homepage-nav-brand"]')
# print(all_makes.text)
makes = all_makes.find_elements_by_xpath('./ul/child::li') #当前节点的所有子节点(未打开新的窗口)
make_num = len(makes)
model_num = 0
save_path = r'E:\Python_work\temp'
for make in makes: # 当打开新的窗口时,需要切换到原始窗口,这里才能继续for循环。
print(make.text)
make.click() # 点击后 无返回值
time.sleep(1)
models = make.find_elements_by_xpath('./div/dl/dd/a')
model_num += len(models)
'''获取链接'''
# for model in models:
# abs_href = model.get_attribute('href')
# print(abs_href)
# break
# break
'''关闭新打开的窗口'''
# for model in models:
# model.click()
# handle = driver.current_window_handle #原始的标签页
# windows = driver.window_handles # 所有的标签页
# print(handle)
# print('#################')
# print(windows)
# time.sleep(5)
# driver.switch_to.window(windows[-1]) #最后1个就是新打开的标签页
# driver.close() #关闭当前页
#
# # 还需要切换到之前的标签页
# # driver.switch_to.window(windows[0])
# driver.switch_to.window(handle)
'''直接打开的下载'''
for model in models:
print(model.text)
model.click()
time.sleep(1)
# 需要切换到新建的window
windows = driver.window_handles
driver.switch_to.window(windows[1]) # 切换到model界面
# driver.close()
time.sleep(1)
try:
# 这里是错误的,切换了窗口,那么就需要driver重新find_element
img_ = model.find_element_by_xpath('//div//a[span="外观"]')
img_.click()
except:
'''因为已经换了新的标签页,那么需要重新建立driver'''
img_ = driver.find_element_by_xpath('//div//a[span="外观"]')
img_.click()
time.sleep(1)
windows = driver.window_handles
driver.switch_to.window(windows[2]) # 切换到外观界面
# 这里在外观界面模拟鼠标下拉,使得全部加载
'''自定义 不断下拉'''
start_num = 0
# 第一次下拉
img_links = driver.find_elements_by_xpath('//div[@class="img-box"]//a')
end_num = len(img_links) # 不会动态变化
while start_num != end_num:
# start = driver.find_element_by_xpath('//div[@class="img-box"]')
start_num = end_num
start = img_links[-1]
target = driver.find_element_by_xpath('//div[@class="footer-text fl"]') # 最下方
ActionChains(driver).drag_and_drop(start, target).perform()
img_links = driver.find_elements_by_xpath('//div[@class="img-box"]//a')
end_num = len(img_links)
time.sleep(0.1)
# 加载全部图片
img_links = driver.find_elements_by_xpath('//div[@class="img-box"]//a')
print(len(img_links))
for img_link in img_links:
# print(make.text) # 应该在前面变量保存
print(img_link.get_attribute('title')) # 这里再使用make就不对了
time.sleep(0.5)
img_link.click()
windows = driver.window_handles
driver.switch_to.window(windows[-1]) # 切换到图像界面
img_link_ = driver.find_element_by_xpath('//div[@class="picinfo-main"]//img')
src_link = img_link_.get_attribute('src')
# 保存图片,使用urlib
img_name = uuid.uuid4()
urllib.request.urlretrieve(src_link, os.path.join(save_path, str(img_name)+'.jpg'))
# 关闭图像界面,并切换到外观界面
time.sleep(1)
driver.close()
windows = driver.window_handles
driver.switch_to.window(windows[2])
driver.close() # 关闭 外观界面
print(windows)
driver.switch_to.window(windows[1]) # 切换到model界面
break
# 再切换到主界面
driver.switch_to.window(windows[0]) #windows[0]是第1个打开的标签页,不动它
break############################selenium 老司机具体流程图##########################################


_____________________________________________________________________
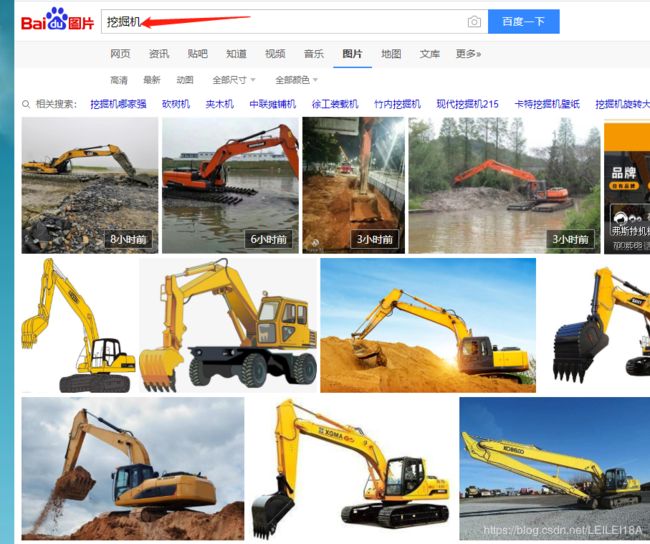
(2) 以百度图片为例,爬取挖掘机图片
'''
注释:
1. 将要搜索的文本表示成list
2. 打开百度图片官网,输入文本,搜索
3. 逐条下载对应的图片
注:
此代码未写断点续爬,许多功能未添加
'''
import os
import uuid
import time
import random
import urllib
import numpy as np
from selenium import webdriver
from selenium.webdriver.common.keys import Keys # 键盘类
def send_param_to_baidu(name, browser):
'''
:param name: str
:param browser: webdriver.Chrome 实际应该是全局变量的
:return: 将要输入的 关键字 输入百度图片
'''
# 采用id进行xpath选择,id一般唯一
inputs = browser.find_element_by_xpath('//input[@id="kw"]')
inputs.clear()
inputs.send_keys(name)
time.sleep(1)
inputs.send_keys(Keys.ENTER)
time.sleep(1)
return
def download_baidu_images(save_path, img_num, browser):
''' 此函数应在
:param save_path: 下载路径
:param img_num: 下载图片数量
:param browser: webdriver.Chrome
:return:
'''
if not os.path.exists(save_path):
os.makedirs(save_path)
img_link = browser.find_element_by_xpath('//li/div[@class="imgbox"]/a/img[@class="main_img img-hover"]')
img_link.click()
# 切换窗口
windows = browser.window_handles
browser.switch_to.window(windows[-1]) # 切换到图像界面
for i in range(img_num):
img_link_ = browser.find_element_by_xpath('//div/img[@class="currentImg"]')
src_link = img_link_.get_attribute('src')
print(src_link)
# 保存图片,使用urlib
img_name = uuid.uuid4()
urllib.request.urlretrieve(src_link, os.path.join(save_path, str(img_name) + '.jpg'))
# 关闭图像界面,并切换到外观界面
time.sleep(0.35*random.random())
# 点击下一张图片
browser.find_element_by_xpath('//span[@class="img-next"]').click()
# 关闭当前窗口,并选择之前的窗口
browser.close()
browser.switch_to.window(windows[0])
return
def main(names, save_root, img_num=1000):
'''
:param names: list str
:param save_root: str
:param img_num: int
:return:
'''
browser = webdriver.Chrome()
browser.get(r'https://image.baidu.com/')
browser.maximize_window()
for name in names:
save_path = os.path.join(save_root, str(names.index(name))) # 以索引作为文件夹名称
send_param_to_baidu(name, browser)
download_baidu_images(save_path=save_path, img_num=img_num, browser=browser)
# 全部关闭
browser.quit()
return
if __name__=="__main__":
main(names=['油罐车', '吊车'], save_root=r'F:\Temp', img_num=10)

######################################################################
4. xpath+scarpy(更新中)
scrapy有比较严格的格式要求,按照要求来做,即可。
中文最新教程1.7版本:https://www.osgeo.cn/scrapy/index.html
英文最新版本:2.1版本;(尽量去看英文教程,但1.7的相差不是很大-基本应用)