本文大致介绍通过flume与kafka的结合,将mysql数据抽取到hive中.
1.那么什么是flume呢?
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力
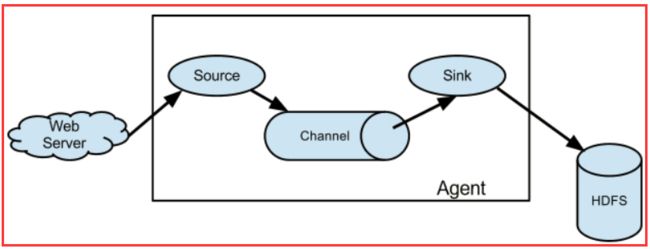
flume的数据流由事件(Event)贯穿始终.事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中.你可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件.Sink负责持久化日志或者把事件推向另一个Source
flume的一些核心概念
Client:Client生产数据,运行在一个独立的线程
Event: 一个数据单元,消息头和消息体组成。(Events可以是日志记录、 avro 对象等。)
Flow: Event从源点到达目的点的迁移的抽象。
Agent: 一个独立的Flume进程,包含组件Source、 Channel、 Sink。(Agent使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含
多个sources和sinks。)
Source: 数据收集组件。(source从Client收集数据,传递给Channel)
Channel: 中转Event的一个临时存储,保存由Source组件传递过来的Event。(Channel连接 sources 和 sinks ,这个有点像一个队列。)
Sink: 从Channel中读取并移除Event, 将Event传递到FlowPipeline中的下一个Agent(如果有的话)(Sink从Channel收集数据,运行在一个独立线程。)
至此简单介绍flume,详细请自行查阅相关信息
参考连接:Flume(一)Flume原理解析 - 苦水润喉 - 博客园
2.接下来介绍mysql数据抽取到kafka中
(默认mysql,kafka,flume都已安装号)
在flume安装目录的conf目录下增加一个配置文件:
mysql-flume.conf

添加以下驱动到flume的lib目录下
mysql-java:
$ wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.35.tar.gz
flume-mysql:
flume-ng-sql-source-1.4.1.jar
下载连接http://repo1.maven.org/maven2/org/keedio/flume/flume-ng-sources/flume-ng-sql-source
开启zookeeper与kafka服务
创建topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test3
启动flume(注意配置文件名称与agent名称)
bin/flume-ng agent -n a1 -c conf -f conf/mysql-flume.conf -Dflume.root.logger=INFO,console
我们可以通过打开kafka消费者窗口查看数据的收集情况
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test3 --from-beginning
3.将kafka中的数据收集并存放进hive中
在用flume将kafka数据抽取到hive过程中需注意几点
1只支持ORCFile
2建表时必须将表设置为事务性表,事务默认关闭,需要自己开启
2表必须分桶
3必须修改一些配置
修改配置如下:
hive.support.concurrency
true
#此为分桶开关,分桶时必须打开
hive.enforce.bucketing
true
hive.exec.dynamic.partition.mode
nonstrict
hive.txn.manager
org.apache.hadoop.hive.ql.lockmgr.DbTxnManager
hive.compactor.initiator.on
true
hive.compactor.worker.threads
1 注意一定不要加以下的配置
hive.in.test
true
建表语句如下:
CREATE TABLE test (
id int
,name string
,add_time string
)
clustered by (id) into 3 buckets #分桶
stored as orc TBLPROPERTIES ('transactional'='true'); #设置orcfile并设置事务
(此处建表时注意,在通过flume将mysql数据抽取到kafka时,int型的id变成了string型,原因不知,所以在将kafka中的数据导入到hive中时,int型的id变成了null,这是由于数据类型不一致导致的,所以hive建表时,将id的类型改为string类型)
flume的配置,kafka-hive.conf
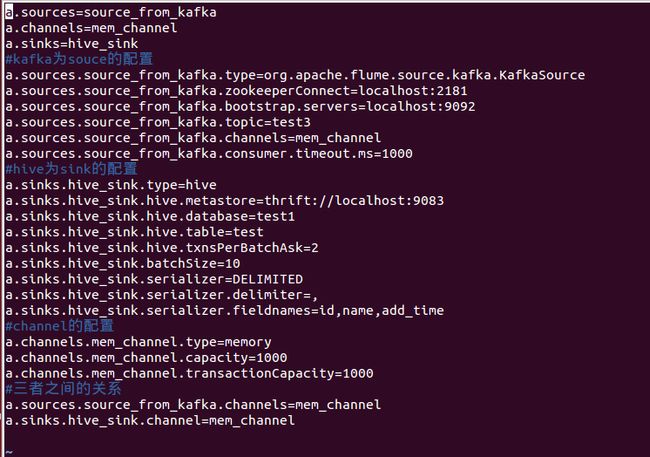
接下来我们就可以开启服务了
首先开启hive metastore服务
$ hive --service metastore
然后开启flume的kafka-hive.conf服务
$ bin/flume-ng agent -n a -c conf -f conf/kafka-hive.conf -Dflume.root.logger=INFO,console
至此,我们在往mysql数据库中添加数据后,hive将会实时同步数据
4.在部署以上环境过程中遇到的几个问题及解决
1.
Failed to start agent because dependencies were not found in classpath. Error follows.java.lang.NoClassDefFoundError: org/apache/hive/hcatalog/streaming/RecordWriter
将hive中相关的jar复制到FLUME安装目录/lib下
hive安装目录/hcatalog/share/hcatalog/*.jar
2.
Failed to start agent because dependencies were not found in classpath. Error follows. java.lang.NoClassDefFoundError org/apache/hadoop/io/SequenceFile$CompressionType
hadoop安装目录share/hadoop/common/hadoop-common-2.4.0.jar复制到FLUME安装目录/lib下
以上两个问题属于flume/lib下缺少jar包出现的,一般缺少的是hive和hadoop中的jar包,注意复制下就好
3.
Caused by: org.apache.flume.sink.hive.HiveWriter$ConnectException: Failed connecting to EndPoint {metaStoreUri='thrift://localhost:9083', database='test1', table='test'
这个问题有说是文件夹权限问题的,但是我一直找不到那个文件夹所在,当我在仔细去看网络文章时,发现我的hive表没有开启事务且没有orc,所以我重新建了一张开启了事务并且格式为orc的表,之后这个问题就解决了
4.另外就是出现了长时间没有数据更新的情况下,Hive Sink 停止工作了,但是重启后会继续运行
hive sink停止工作
参考链接:
flume简单测试hdfssink && hivesink - DoveYoung欢迎大家指正! - CSDN博客
Hive Transaction 事务性 小试 - 王建奎Jerrick的个人页面 - 开源中国
kafka与hive对接 - qq_38690917的博客 - CSDN博客
Flume 1.7.0安装与实例 - strongyoung的专栏 - CSDN博客
记flume部署过程中遇到的问题以及解决方法(持续更新) - 小麒麟的成长之路 - CSDN博客