xgboost,sklearn:特征选择
1.利用xgboost画出对各个特征的重要性估计
博客还是采用最基本的鸢尾花数据集
xgboost中plot_importance可以画出对各个特征重要性的估计,这个估计的依据是在建立树的时候哪些特征经常被作为划分节点的依据.
xgboost在选择特征的时候会使用函数get_score(),但是这个函数仅仅适用于树集合学习,对于线性学习不适合。get_score()的形式是这样的get_score(fmap=’’, importance_type=‘weight’),它的评价方式通过函数形式我们知道的它的默认评价方式为weight,它还有几种评价方式如下
1.‘weight’: the number of times a feature is used to split the data across all trees.
3.‘gain’: the average gain across all splits the feature is used in.
4.‘cover’: the average coverage across all splits the feature is used in.
5.‘total_gain’: the total gain across all splits the feature is used in.
6.‘total_cover’: the total coverage across all splits the feature is used in.
weight:是以特征用到的次数来评价
gain:当利用特征做划分的时候的评价基尼指数
cover:利用一个覆盖样本的指标二阶导数(具体原理不清楚有待探究)平均值来划分。
total_gain:总基尼指数
total_cover:总覆盖
//////////////////////////
Gain:在xgboost中每次分裂节点会计算一个gain,这里的评价gain就是以此特征为分裂标准的时候的评价gain,gain见我的前一篇博客
/////////////////////////
cover在这篇博客中找到了答案,这是一个二阶导数的评均值,在分裂的时候回计算左右节点的二阶导数和。
////////////////////////
举个例子
from sklearn.metrics import accuracy_score
import pandas as pd
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from xgboost import plot_importance
def estimate(model,data):
#sns.barplot(data.columns,model.feature_importances_)
ax1=plot_importance(model,importance_type="gain")
ax1.set_title('gain')
ax2=plot_importance(model, importance_type="weight")
ax2.set_title('weight')
ax3 = plot_importance(model, importance_type="cover")
ax3.set_title('cover')
plt.show()
def classes(data,label,test):
model=XGBClassifier(objective='multi:softmax',max_depth=5, learning_rate=0.1, n_estimators=160)
model.fit(data,label)
ans=model.predict(test)
estimate(model, data)
return ans
if __name__ == '__main__':
data=pd.read_csv('iris.csv')
lable=data['Species']
origin_data=data
data=data.drop(['id','Species'],axis=1)
train_data,test_data,train_label,test_label=\
train_test_split(data,lable,random_state=8,stratify=lable,test_size=1/3,shuffle=True)
ans=classes(train_data,train_label,test_data)
pre=accuracy_score(test_label, ans)
print('acc=',accuracy_score(test_label,ans))
图像如下

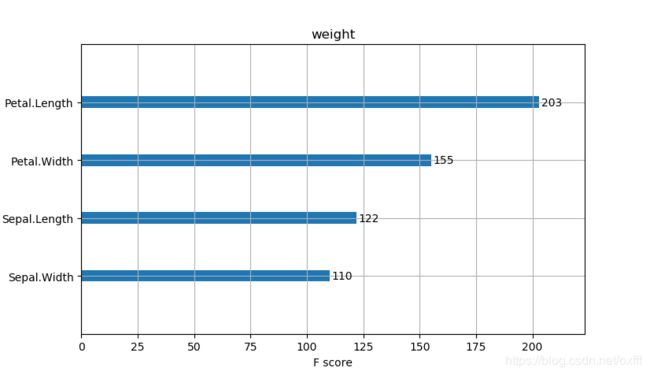
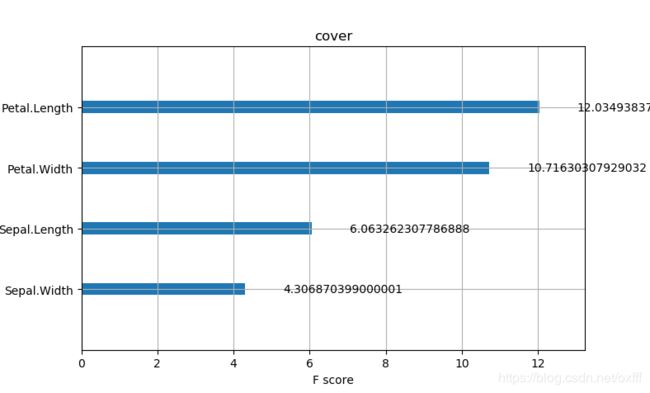
可以看到三种评价方式有时候对于特征的排序是不同的。
2.利用xgboost进行特征选择
参考博客
先来了解一下SelectFromModel()这个函数,参考官网函数形式如下
sklearn.feature_selection.SelectFromModel(estimator, threshold=None, prefit=False, norm_order=1, max_features=None)
estimator:object
这个参数就是我们的评价器,用来评价,这个评价器是已经用数据填充的或者没有填充的都可以,但这个评价器必须具有属性feature_importances_ 或者coef_ --------对象。基本分类器。只有不对分类器进行预训练时该属性才有值
threshold:string, float, optional default None
这个是阈值,用来进行特征的选择,当大于或者等于阈值的时候特征就会被保留,当小于阈值的时候特征将会被舍弃。如果被设置为’median’那么此值就代表着评价标准(cover 或者 gain…博客一开始写的)的平均值,也可以加入缩放因子例如设置为“1.25*mean”,如果为None且估计器即上面的estimator有L1正则项明确或者没有明确这个阈值将会被设置为1e-5,其他的情况默认是’mean’。
prefit:bool, default False
预填充模型是否直接传入构建器,如果为True,则transform这个函数必须被立刻调用同时SelectFromModel这个函数不能与函数cross_val_score, GridSearchCV和其他克隆估计器的函数一起使用,如果为False,模型会利用fit函数和transform函数去选择特征-------默认值为False。是否对传入的基本分类器事先进行训练。如果设置该值为True,则需要对传入的基本分类器进行训练,如果设置该值为False,则只需要传入分类器实例即可
norm_order:non-zero int, inf, -inf, default 1
非零的整数。该值设置为类别数-1
max_features:int or None, optional
在大于阈值的基础上如果设置此值就会在阈值选择基础上对多选择max_features个特征,如果只想用此值而不用阈值可以将threshold设置为threshold=-np.inf
此函数的属性有
estimator_:与上面的是一样的
threshold_float:同上
方法:
fit(X[, y]):对基本分类器进行训练
fit_transform(X[, y]):对基本分类器进行训练并执行特征选择
get_support([indices]):获取选出的特征的索引序列或mask
partial_fit(X[, y]):对基本分类器的训练只进行一次
特征的选取并不一定代表着性能的提升,这一点在所有的特征选择中是一致的
feature_importances_代表着特征的重要程度不同于上面的plot_importance需要指定评判标准,这个的默认标准通过分析源代码知道是gain![]()
上图是源码图片
但是我们通过比较与plot_importance所画出的图形发现坐标轴不太一样利用sns.barplot(data.columns,model.feature_importances_)画出的图像如图sns是seanborn库其用法在我的前面博客
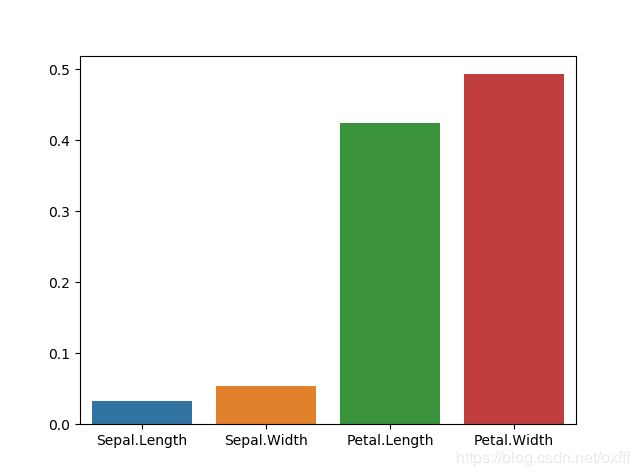
我们再看feature_importances_的源码
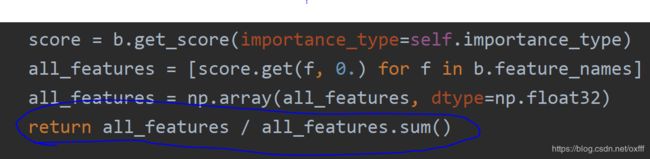
发现它进行了归一化处理也就是将柱子的值相加为1
参考:
https://zhuanlan.zhihu.com/p/72092241
https://blog.csdn.net/fontthrone/article/details/79064930
https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.SelectFromModel.html#sklearn.feature_selection.SelectFromModel.transform
http://www.mamicode.com/info-detail-2296076.html
https://sklearn.apachecn.org/
https://www.cnblogs.com/stevenlk/p/6543628.html
https://www.cnblogs.com/geo-will/p/9626734.html
https://www.zhihu.com/question/29316149/answer/110159647
https://www.cnblogs.com/jasonfreak/p/5448385.html