Python程序分析
http://blog.csdn.net/pipisorry/article/details/39998317
python性能分析 - 定位程序性能瓶颈
程序分析
对代码优化的前提是需要了解性能瓶颈在什么地方,程序运行的主要时间是消耗在哪里,对于比较复杂的代码可以借助一些工具来定位,python 内置了丰富的性能分析工具,如 profile,cProfile 与 hotshot 等。其中 Profiler 是 python 自带的一组程序,能够描述程序运行时候的性能,并提供各种统计帮助用户定位程序的性能瓶颈。
Python 标准模块提供三种 profilers:cProfile,profile 以及 hotshot。profile模块和cProfile模块可以用来分析程序,它们的工作原理都一样,唯一的区别是,cProfile模块是以C扩展的方式实现的,如此一来运行的速度也快了很多,也显得比较流行。这两个模块都可以用来收集覆盖信息(比如,有多少函数被执行了),也能够收集性能数据。对一个程序进行分析的最简单的方法就是运行这个命令:
% python -m cProfile someprogram.py此外,也可以使用profile模块中的run函数:
run(command [, filename])该函数会使用exec语句执行command中的内容。filename是可选的文件保存名,如果没有filename的话,该命令的输出会直接发送到标准输出上。
下面是分析器执行完成时的输出报告:
126 function calls (6 primitive calls) in 5.130 CPU seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.030 0.030 5.0705.070:1(?)
121/15.0200.0415.0205.020 book.py:11(process)
1 0.020 0.020 5.0405.040book.py:5(?)
2 0.000 0.000 0.0000.000exceptions.py:101(_ _init_ _)
1 0.060 0.060 5.1305.130profile:0(execfile('book.py'))
0 0.000 0.000 profile:0(profiler) 当输出中的第一列包含了两个数字时(比如,121/1),后者是元调用(primitive call)的次数,前者是实际调用的次数(译者注:只有在递归情况下,实际调用的次数才会大于元调用的次数,其他情况下两者都相等)。
对于绝大部分的应用程序来讲使用该模块所产生的的分析报告就已经足够了,比如,你只是想简单地看一下你的程序花费了多少时间。然后,如果你还想将这些数据保存下来,并在将来对其进行分析,你可以使用pstats模块。
profile模块中最基础的东西就是run()函数了。该函数会把一个语句字符串作为参数,然后在执行语句时生成所花费的时间报告。
import profile
def fib(n):
# from literateprograms.org
# http://bit.ly/hlOQ5m
ifn==0:
return0
elifn==1:
return1
else:
returnfib(n-1)+fib(n-2)
def fib_seq(n):
seq=[]
ifn >0:
seq.extend(fib_seq(n-1))
seq.append(fib(n))
returnseq
profile.run('print(fib_seq(20)); print')皮皮Blog
使用 profile 进行性能分析
import profile
def profileTest():
Total =1;
for i in range(10):
Total=Total*(i+1)
print Total
return Total
if __name__ == "__main__":
profile.run("profileTest()")程序的运行结果如下:
图 1. 性能分析结果
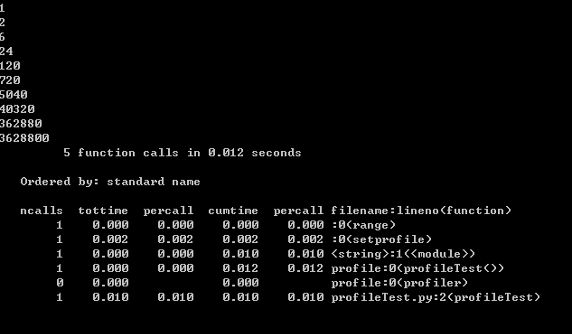
输出每列的具体解释:
- ncalls:表示函数调用的次数;
- tottime:表示指定函数的总的运行时间,除掉函数中调用子函数的运行时间;
- percall:(第一个 percall)等于 tottime/ncalls;
- cumtime:表示该函数及其所有子函数的调用运行的时间,即函数开始调用到返回的时间;
- percall:(第二个 percall)即函数运行一次的平均时间,等于 cumtime/ncalls;
- filename:lineno(function):每个函数调用的具体信息;
将输出以日志的形式保存:只需要在调用的时候加入另外一个参数。如 profile.run("profileTest()","testprof")。
对于 profile 的剖析数据
如果以二进制文件的时候保存结果的时候,可以通过 pstats 模块进行文本报表分析,它支持多种形式的报表输出,是文本界面下一个较为实用的工具。使用非常简单:
import pstats
p = pstats.Stats('testprof')
p.sort_stats("name").print_stats()其中 sort_stats() 方法能够对剖分数据进行排序, 可以接受多个排序字段,如 sort_stats('name', 'file') 将首先按照函数名称进行排序,然后再按照文件名进行排序。常见的排序字段有 calls( 被调用的次数 ),time(函数内部运行时间),cumulative(运行的总时间)等。此外 pstats 也提供了命令行交互工具,执行 python – m pstats 后可以通过 help 了解更多使用方式。
对于大型应用程序,如果能够将性能分析的结果以图形的方式呈现,将会非常实用和直观,常见的可视化工具有 Gprof2Dot,visualpytune,KCacheGrind 等。
pycharm中使用profile程序分析
[简单扯扯PyCharm4.5中新加的Python Profiler功能]
皮皮Blog
测试程序究竟在哪里花费了多少时间
整个程序计时
如果你只是想简单地给你的整个程序计时的话,使用Unix中的time命令就已经完全能够应付了。例如:
|
1
2
3
4
5
|
bash
%
time python3 someprogram.py
real
0m13
.
937s
user
0m12
.
162s
sys
0m0
.
098s
bash
%
|
特定函数的分析
通常来讲,分析代码的程度会介于这两个极端之间。比如,你可能已经知道你的代码会在一些特定的函数中花的时间特别多。针对这类特定函数的分析,我们可以使用修饰器decorator,例如:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
import
time
from
functools
import
wraps
def
timethis(func):
@wraps
(func)
def
wrapper(
*
args,
*
*
kwargs):
start
=
time.perf_counter()
r
=
func(
*
args,
*
*
kwargs)
end
=
time.perf_counter()
print
(
'{}.{} : {}'
.
format
(func.__module__, func.__name__, end
-
start))
return
r
return
wrapper
|
使用decorator的方式很简单,你只需要把它放在你想要分析的函数的定义前面就可以了。例如:
|
1
2
3
4
5
6
7
8
|
>>> @timethis
...
def
countdown(n):
...
while
n >
0
:
... n
-
=
1
...
>>> countdown(
10000000
)
__main__.countdown :
0.803001880645752
>>>
|
分析一个语句块
可以定义一个上下文管理器(context manager)。例如:
|
1
2
3
4
5
6
7
8
9
10
11
|
import
time
from
contextlib
import
contextmanager
@contextmanager
def
timeblock(label):
start
=
time.perf_counter()
try
:
yield
finally
:
end
=
time.perf_counter()
print
(
'{} : {}'
.
format
(label, end
-
start))
|
接下来是如何使用上下文管理器的例子:
|
1
2
3
4
5
6
7
|
>>> with timeblock(
'counting'
):
... n
=
10000000
...
while
n >
0
:
... n
-
=
1
...
counting :
1.5551159381866455
>>>
|
研究一小段代码的性能
如果想研究一小段代码的性能的话,timeit模块会非常有用。
|
1
2
3
4
5
6
|
>>>
from
timeit
import
timeit
>>> timeit(
'math.sqrt(2)'
,
'import math'
)
0.1432319980012835
>>> timeit(
'sqrt(2)'
,
'from math import sqrt'
)
0.10836604500218527
>>>
|
timeit的工作原理是,将第一个参数中的语句执行100万次,然后计算所花费的时间。第二个参数指定了一些测试之前需要做的环境准备工作。如果你需要改变迭代的次数,可以附加一个number参数,就像这样:
|
1
2
3
4
5
|
>>> timeit(
'math.sqrt(2)'
,
'import math'
, number
=
10000000
)
1.434852126003534
>>> timeit(
'sqrt(2)'
,
'from math import sqrt'
, number
=
10000000
)
1.0270336690009572
>>>
|
处理时间
当进行性能评估的时候,要牢记任何得出的结果只是一个估算值。函数time.perf_counter()能够在任一平台提供最高精度的计时器。然而,它也只是记录了自然时间,记录自然时间会被很多其他因素影响,比如,计算机的负载。
如果你对处理时间而非自然时间感兴趣的话,你可以使用time.process_time():
|
1
2
3
4
5
6
7
8
9
10
11
12
|
import
time
from
functools
import
wraps
def
timethis(func):
@wraps
(func)
def
wrapper(
*
args,
*
*
kwargs):
start
=
time.process_time()
r
=
func(
*
args,
*
*
kwargs)
end
=
time.process_time()
print
(
'{}.{} : {}'
.
format
(func.__module__, func.__name__, end
-
start))
return
r
return
wrapper
|
Note:最后也是相当重要的就是,如果你想做一个详细的性能评估的话,你最好查阅time,timeit以及其他相关模块的文档,这样你才能够对平台相关的不同之处有所了解。
[A guide to analyzing Python performance]
[一行一行分析代码拓展包line_profiler]
[操作系统服务:time时间模块+datetime模块]
皮皮Blog
测量 Python 脚本和控制内存以及 CPU 使用率
line_profiler 模块
line_profiler 给出了在你代码每一行花费的 CPU 时间。
memory_profiler 模块
memory_profiler 模块被用于在逐行的基础上,测量你代码的内存使用率。尽管如此,它可能使得你的代码运行的更慢。
也建议安装 psutil 包,使得 memory_profile 模块运行的更快。
guppy 包
最后,使用这个包,你可以跟踪每个类型在你代码中每个阶段(字符, 元组, 字典 等等)有多少对象被创建了。
[7 个测量 Python 脚本和控制内存以及 CPU 使用率的技巧]
from:http://blog.csdn.net/pipisorry/article/details/39998317
ref:http://www.ibm.com/developerworks/cn/linux/l-cn-python-optim/index.html