Golang丨Java丨Python爬虫实战—Boss直聘网站数据抓取
我们分别通过Golang、Python、Java三门语言,分别实现对Boss直聘网站的招聘数据进行爬取。
首先打开Boss直聘网站:
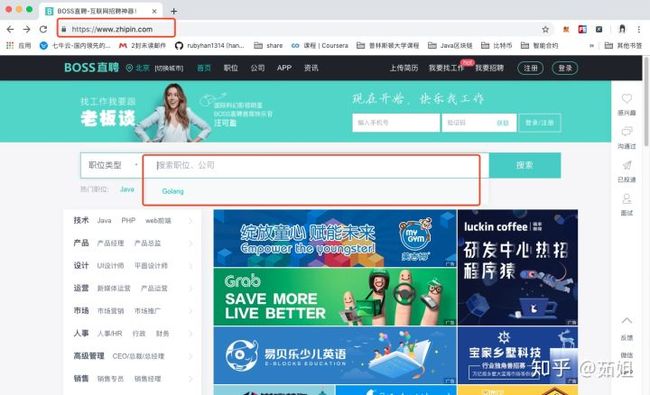
然后我们在职位类型中输入Go或者Golang关键字:

然后我们可以看到一个列表,和Go语言相关的各种招聘职位,还可以不停的下一页。。
那我们现在就来爬取这些数据:我们比较关心这里的职位名称,薪资待遇,工作地点,对于工作经验的要求,学历的要求,公司名称,公司类型,公司发展阶段,公司规模等等。。
一、分析页面
我们通过分析页面的结构发现,页面的职位列表,其实都位于一个ul中的li里,每个页面有30个职位,所以有30个li标签:

打开这个li标签后,里面是div标签嵌套,包括了招聘信息和公司信息:
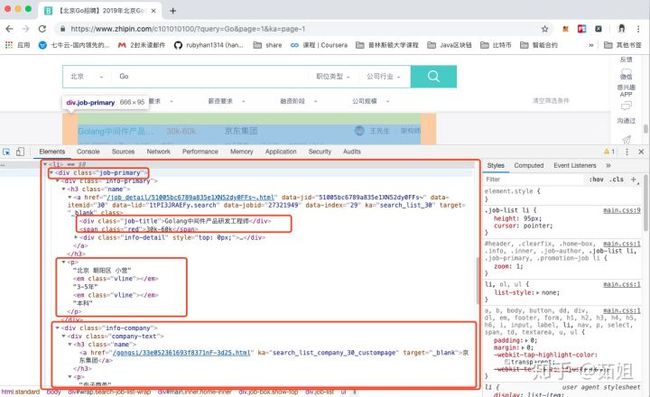
接下来我们就可以通过代码来爬取这些数据了,首先我们要确定要爬取的第一个url:
https://www.zhipin.com/c101010100/?query=Go&page=1
一共有10页数据,分别通过page=1、2、3。。。来实现,
所以接下来要爬取的url:
https://www.zhipin.com/c101010100/?query=Go&page=2
https://www.zhipin.com/c101010100/?query=Go&page=3
。。。
https://www.zhipin.com/c101010100/?query=Go&page=10
爬取到的数据,我们也不需要处理,打印输出即可。。因为我们只是想看一下几门语言爬取数据在实现上有什么不同。。
好了,现在让我们来开开心心的撸代码吧。。
二、Golang语言实现
使用Go语言来爬取这个页面,github里搜了下,发现goquery这个爬虫包用的人还挺多的,7000多个star,而且是BSD开源协议,于是毫不犹豫的拿来用了。

goquery的使用还是比较简单,按照文档说明一步一步来就可以了:
首先:需要安装
localhost:~ ruby$ go get github.com/PuerkitoBio/goquery其次:就是去看看goquery的API,先了解一下常用的方法:
https://godoc.org/github.com/PuerkitoBio/goquery
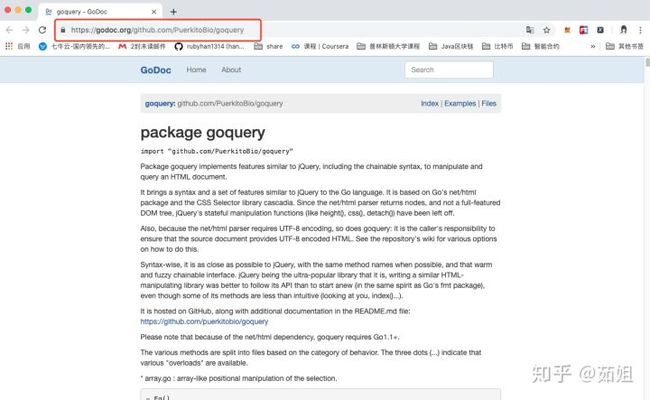

然后就可以开始写代码了:
打开Goland,新建一个go文件:
package main
import (
"github.com/PuerkitoBio/goquery"
"log"
"fmt"
"strconv"
"time"
)
func main() {
url := "https://www.zhipin.com/c101010100/?query=Go&page="
t := time.Now()
fmt.Println("============== 千锋教育Go语言开发教学部 职位信息分析 ================")
for offset := 0; offset < 10; offset++ {
time.Sleep(1 * time.Second)
doc, err := goquery.NewDocument(url + strconv.Itoa(offset))
handleErr(err)
fmt.Printf("第 %d 页的数据:\n", offset)
doc.Find(".job-primary").Each(func(i int, selection *goquery.Selection) {
item := Item{}
fmt.Printf("职位序号:第%d个职位\n", (i + 1))
item.position_name = selection.Find("div .job-title").Text()
fmt.Printf("职位名称:%s\n", item.position_name)
item.position_salary = selection.Find("div .red").Text()
fmt.Printf("职位薪酬:%s\n", item.position_salary)
item.work_address = selection.Find(".info-primary p").Children().Nodes[0].PrevSibling.Data
fmt.Printf("工作地点:%s\n", item.work_address)
item.work_experience = selection.Find(".info-primary p").Children().Nodes[0].NextSibling.Data
fmt.Printf("职位所需工作经历:%s\n", item.work_experience)
item.education = selection.Find(".info-primary p").Children().Nodes[1].NextSibling.Data
fmt.Printf("学历要求:%s\n", item.education)
item.company_name = selection.Find(".company-text .name").Children().First().Text()
fmt.Printf("公司名称:%s\n", item.position_name)
item.company_type = selection.Find(".company-text p").Children().Nodes[0].PrevSibling.Data
fmt.Printf("公司类型:%s\n", item.company_type )
if selection.Find(".company-text p").Children().Size() == 2 {
item.company_development_stage = selection.Find(".company-text p").Children().Nodes[0].NextSibling.Data
fmt.Printf("公司发展阶段:%s\n", item.company_development_stage)
item.company_size = selection.Find(".company-text p").Children().Nodes[1].NextSibling.Data
fmt.Printf("公司规模:%s\n", item.company_size )
} else if selection.Find(".company-text p").Children().Size() == 1 {
item.company_size = selection.Find(".company-text p").Children().Nodes[0].NextSibling.Data
fmt.Printf("公司规模:%s\n", item.company_size)
}
fmt.Println("================================================================\n")
})
}
elapsed := time.Since(t)
fmt.Println("app elapsed:", elapsed)
}
type Item struct {
// 职位名称
position_name string
// 职位薪酬
position_salary string
//工作地点
work_address string
// 职位所需工作经历
work_experience string
// 学历要求
education string
// 公司名称
company_name string
// 公司类型
company_type string
// 公司发展阶段
company_development_stage string
//公司规模
company_size string
}
func handleErr(err error) {
if err != nil {
log.Fatal(err)
}
}一共也就这些代码,加上注释78行。
然后可以运行:(注:由于执行结果过长,为增加可阅读性部分执行结果已经删除处理)
GOROOT=/usr/local/go #gosetup
GOPATH=/Users/ruby/go #gosetup
/usr/local/go/bin/go build -i -o /private/var/folders/kt/nlhsnpgn6lgd_q16f8j83sbh0000gn/T/___go_build_boss_go /Users/ruby/go/src/boss/boss.go #gosetup
/private/var/folders/kt/nlhsnpgn6lgd_q16f8j83sbh0000gn/T/___go_build_boss_go #gosetup
============== 千锋教育Go语言开发教学部 职位信息分析 ================
第 0 页的数据:
职位序号:第1个职位
职位名称:Golang
职位薪酬:25k-50k
工作地点:北京
职位所需工作经历:5-10年
学历要求:本科
公司名称:京东集团
公司类型:电子商务
公司发展阶段:已上市
公司规模:10000人以上
================================================================
职位序号:第2个职位
职位名称:Golang
职位薪酬:20k-35k
工作地点:北京 朝阳区 亮马桥
职位所需工作经历:3-5年
学历要求:本科
公司名称:平安科技
公司类型:互联网
公司发展阶段:不需要融资
公司规模:1000-9999人
================================================================
职位序号:第3个职位
职位名称:Golang
职位薪酬:20k-30k
工作地点:北京 海淀区 知春路
职位所需工作经历:3-5年
学历要求:本科
公司名称:腾讯科技(北京)公司
公司类型:移动互联网
公司发展阶段:已上市
公司规模:10000人以上
================================================================
职位序号:第4个职位
职位名称:Golang
职位薪酬:20k-40k
工作地点:北京 海淀区 中关村
职位所需工作经历:3-5年
学历要求:本科
公司名称:旷视科技
公司类型:移动互联网
公司发展阶段:C轮
公司规模:1000-9999人
================================================================
职位序号:第5个职位
职位名称:Golang
职位薪酬:20k-40k
工作地点:北京 海淀区 上地
职位所需工作经历:3-5年
学历要求:本科
公司名称:Aibee
公司类型:互联网
公司发展阶段:A轮
公司规模:100-499人
================================================================
.
省略
.
注:由于执行结果过长,为增加可阅读性部分执行结果已经删除处理
.
省略
.
================================================================
职位序号:第25个职位
职位名称:Golang
职位薪酬:20k-35k
工作地点:北京 海淀区 上地
职位所需工作经历:3-5年
学历要求:本科
公司名称:滴滴出行
公司类型:移动互联网
公司发展阶段:D轮及以上
公司规模:1000-9999人
================================================================
职位序号:第26个职位
职位名称:高级软件工程师(Golang)
职位薪酬:30k-50k
工作地点:北京 海淀区 五道口
职位所需工作经历:3-5年
学历要求:学历不限
公司名称:魔门塔科技
公司类型:计算机软件
公司发展阶段:B轮
公司规模:500-999人
================================================================
职位序号:第27个职位
职位名称:京东云golang后端开发工程师
职位薪酬:20k-40k
工作地点:北京 朝阳区 小营
职位所需工作经历:5-10年
学历要求:本科
公司名称:京东集团
公司类型:电子商务
公司发展阶段:已上市
公司规模:10000人以上
================================================================
职位序号:第28个职位
职位名称:Golang开发工程师
职位薪酬:15k-25k
工作地点:北京 海淀区 航天桥
职位所需工作经历:1-3年
学历要求:本科
公司名称:央视网
公司类型:互联网
公司发展阶段:不需要融资
公司规模:1000-9999人
================================================================
职位序号:第29个职位
职位名称:Golang开发工程师
职位薪酬:5k-9k
工作地点:北京 海淀区 大钟寺
职位所需工作经历:1年以内
学历要求:本科
公司名称:卿烨科技
公司类型:互联网
公司发展阶段:A轮
公司规模:100-499人
================================================================
职位序号:第30个职位
职位名称:Golang开发工程师
职位薪酬:30k-60k
工作地点:北京 海淀区 万柳
职位所需工作经历:3-5年
学历要求:本科
公司名称:费曼咨询
公司类型:互联网
公司发展阶段:未融资
公司规模:0-20人
================================================================
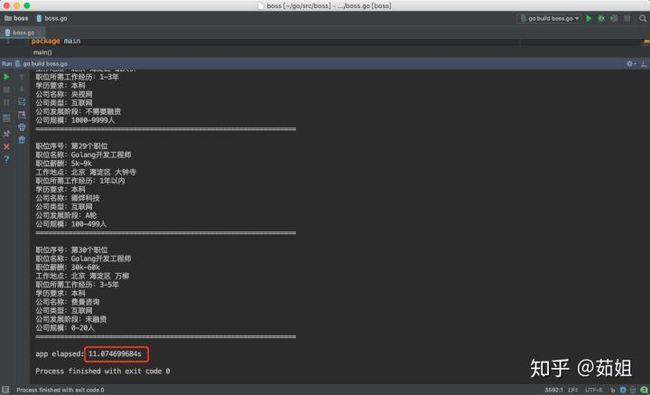
app elapsed: 11.074699684s
Process finished with exit code 0
我们可以看到一共花费了11s的时间,但是我们为了防止boss反爬,在程序中设置了,每隔1s中再爬取下个页面,所以减掉9s,真正的爬数据的时间也就2s:
三、Python语言实现
python在爬虫方面还是比较强大的,我选了一个最时髦的框架:scrapy
这个框架虽然说功能很强大,但是用起来还稍微有点麻烦的,不说别的,创建项目就得用终端的scrapy命令创建,而不是IDE直接创建。
所以打开终端,进入python的workspace,输入以下命令:
localhost:~ ruby$ scrapy startproject bossspider然后通过Pycharm打开这个项目:
先编写items.py文件,就是我们要爬取的数据,需要先在此处定义,然后每一条数据就是一个item:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class BossspiderItem(scrapy.Item):
# 职位名称
position_name = scrapy.Field()
# 职位薪酬
position_salary = scrapy.Field()
# 工作地点
work_address = scrapy.Field()
# 职位所需工作经历
work_experience = scrapy.Field()
# 学历要求
education = scrapy.Field()
# 公司名称
company_name = scrapy.Field()
# 公司类型
company_type = scrapy.Field()
# 公司发展阶段
company_development_stage = scrapy.Field()
# 公司规模
company_size = scrapy.Field()
然后我们打开spiders目录:新建一个py文件:bossspider.py,这里写爬取数据的代码:
# -*- coding: utf-8 -*-
import scrapy
import time
from bossspider.items import BossspiderItem
class BossSpider(scrapy.Spider):
"""
功能:爬取Boss直聘Golang职位
"""
# 爬虫名
name = "bossspider"
# 爬虫作用范围
allowed_domains = ["zhipin.com"]
url = "https://www.zhipin.com/c101010100/?query=Go&page="
offset = 1
# 起始url
start_urls = [url + str(offset)]
def parse(self, response):
# items = []
for each in response.xpath("//div[@class='job-list']/ul//li"):
item = BossspiderItem()
# 职位名称
item['position_name'] = each.xpath(".//div[@class='job-title']/text()").extract()[0]
print("职位名称:", item['position_name'])
# 职位薪酬
item['position_salary'] = each.xpath(".//span[@class='red']/text()").extract()[0]
print("职位薪酬:", item['position_salary'])
# 工作地点
item['work_address'] = each.xpath(".//div[@class='info-primary']/p/text()").extract()[0]
print("工作地点:", item['work_address'])
# 职位所需工作经历
item['work_experience'] = each.xpath(".//div[@class='info-primary']/p/text()").extract()[1]
print("职位所需工作经历:", item['work_experience'])
# 学历要求
item['education'] = each.xpath(".//div[@class='info-primary']/p/text()").extract()[2]
print("学历要求:", item['education'])
# 公司名称
item['company_name'] = each.xpath(".//div[@class='company-text']/h3//text()").extract()[0]
print("公司名称:", item['company_name'])
company_info = each.xpath(".//div[@class='company-text']/p/text()").extract()
# print("====>>长度:", len(company_info))
# 公司类型
item['company_type'] = company_info[0]
if len(company_info) == 3:
# 公司发展阶段
item['company_development_stage'] = company_info[1]
print("公司发展阶段:", item['company_development_stage'])
# 公司
item['company_size'] = company_info[2]
print("公司规模:", item['company_size'])
else:
# 公司规模
item['company_size'] = company_info[1]
print("公司规模:", item['company_size'])
yield item
if self.offset < 10:
self.offset += 1
print("---->", self.url+str(self.offset))
time.sleep(1)
yield scrapy.Request(self.url + str(self.offset), callback=self.parse)
# return items
然后修改setting.py文件,设置请求头等等:
# -*- coding: utf-8 -*-
# Scrapy settings for bossspider project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'bossspider'
SPIDER_MODULES = ['bossspider.spiders']
NEWSPIDER_MODULE = 'bossspider.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# 设置item——pipelines
ITEM_PIPELINES = {
'bossspider.pipelines.BossspiderPipeline': 300,
}
# 设置请求头部,添加url
DEFAULT_REQUEST_HEADERS = {
"User-Agent": "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;",
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'
}
为了能够在爬取数据的时候,统计程序耗时,我们还可以修改scrapy的包文件:corestats.py
def spider_opened(self, spider):
self.start = time.time()
start_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(self.start)) # 转化格式
self.stats.set_value('start_time', start_time, spider=spider)
def spider_closed(self, spider, reason):
self.end = time.time()
finish_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(self.end)) # 转化格式
self.stats.set_value('finish_time', finish_time, spider=spider)
self.stats.set_value('finish_reason', reason, spider=spider)
# 这是计算此时运行耗费多长时间,特意转化为 时:分:秒
Total_time = self.end - self.start
m, s = divmod(Total_time, 60)
h, m = divmod(m, 60)
self.stats.set_value('Total_time', "共耗时===>%d时:%02d分:%02d秒" % (h, m, s), spider=spider)
然后运行一下程序,打开终端,输入以下命令:
hanru-3:bossspider ruby$ scrapy crawl bossspider或者:
hanru-3:bossspider ruby$ scrapy crawl bossspider -o boss.json表示把爬取的数据导出到boss.json文件中。

共耗时12s,同样也是减掉9s的睡眠时间,耗时3s。
四、Java语言实现
Java的爬虫,我们可以通过Jsoup库来辅助我们实现Java语言的编程实现)。
先创建Java工程,然后下载Jsoup.jar源码库并添加到Java工程中的libs中,并添加成为library。
接着创建Item类,因为Java是面向对象的语言,所以我们先创建一个类,用于封装下载后的数据:
package com.javahook.boss;
//爬取数据后构建对象
public class Item {
// 职位名称
private String positionName;
// 职位薪酬
private String positionSalary;
// 工作地点
private String workAddress;
// 职位所需工作经历
private String workExperience;
//学历要求
private String education;
// 公司名称
private String companyName;
// 公司类型
private String companyType;
//公司发展阶段
private String companyDevelopmentStage;
//公司规模
private String companySize;
public String getPositionName() {
return positionName;
}
public void setPositionName(String positionName) {
this.positionName = positionName;
}
public String getPositionSalary() {
return positionSalary;
}
public void setPositionSalary(String positionSalary) {
this.positionSalary = positionSalary;
}
public String getWorkAddress() {
return workAddress;
}
public void setWorkAddress(String workAddress) {
this.workAddress = workAddress;
}
public String getWorkExperience() {
return workExperience;
}
public void setWorkExperience(String workExperience) {
this.workExperience = workExperience;
}
public String getEducation() {
return education;
}
public void setEducation(String education) {
this.education = education;
}
public String getCompanyName() {
return companyName;
}
public void setCompanyName(String companyName) {
this.companyName = companyName;
}
public String getCompanyType() {
return companyType;
}
public void setCompanyType(String companyType) {
this.companyType = companyType;
}
public String getCompanyDevelopmentStage() {
return companyDevelopmentStage;
}
public void setCompanyDevelopmentStage(String companyDevelopmentStage) {
this.companyDevelopmentStage = companyDevelopmentStage;
}
public String getCompanySize() {
return companySize;
}
public void setCompanySize(String companySize) {
this.companySize = companySize;
}
}
然后我们创建一个带main()的java文件,来编写爬虫的代码:
package com.javahook.boss;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
/**
* Boss直聘网站职位信息爬取代码实现
*/
public class HookBoss {
public static void main(String[] args) {
long start = System.currentTimeMillis();
int jobSum = 0;
//总共爬取10页内容
for (int i = 0; i < 10; i++) {
try {
jobSum += hookJobInfo(i);
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
System.out.println(" 职位爬取中断,检查程序是否有错误并重新爬取。");
}
}
System.out.println("职位数量:" + jobSum);
System.out.println();
long end = System.currentTimeMillis();
System.out.println("本次爬取共计耗时:" + ((float) (end - start)) / 1000 + "s");
}
/**
* 爬取页面的方法
*
* @param pageNumber 爬取也页码
* @return
*/
private static int hookJobInfo(int pageNumber) throws IOException {
//Boss直聘职位信息url
String url = "https://www.zhipin.com/c101010100/?query=Go&page=1&ka=page-1";
//使用Jsoup库来对特定的url进行直接请求 抛出异常
Document doc = Jsoup.connect(url).get();
Elements jobElements = doc.getElementsByClass("job-list");
Element jobListElement = jobElements.get(0);
Element ulElement = jobListElement.getElementsByTag("ul").first();
int jobSize = ulElement.childNodeSize() / 2;//因为标签是开标签和闭标签对称的,因此职位的数量应该是1/2;
for (int i = 0; i < jobSize; i++) {
Item item = new Item();
Element jobElement = ulElement.child(i);
System.out.println("============== 千锋教育Go语言开发教学部 职位信息分析 ================");
System.out.println("职位序号:第" + (i + 1) + "个职位");
Element jobTitle = jobElement.getElementsByClass("job-title").first();
item.setPositionName(jobTitle.text());
System.out.println("职位名称:" + item.getPositionName());
Element jobSalary = jobElement.getElementsByClass("red").first();
item.setPositionSalary(jobSalary.text());
System.out.println("职位薪酬:" + item.getPositionSalary());
Element elJob = jobElement.getElementsByTag("p").first();
item.setWorkAddress(elJob.childNode(0).toString());
System.out.println("工作地点:" + item.getWorkAddress());
item.setWorkExperience( elJob.childNode(2).toString());
System.out.println("职位所需工作经历:" +item.getWorkExperience());
item.setEducation( elJob.childNode(4).toString());
System.out.println("学历要求:" +item.getEducation());
//公司信息
Element companyElement = jobElement.getElementsByClass("info-company").first();
Element companyName = companyElement.getElementsByClass("name").first();
System.out.println("公司名称:" + companyName.text());
//公司 类型、发展阶段、规模等相关信息的解析
Element companyEl = companyElement.getElementsByTag("p").first();
int companyInfoLength = companyEl.childNodeSize();
for (int j = 0; j < companyInfoLength; j++) {
String info = companyEl.childNode(j).toString();
if (!"".equals(info)) {
switch (j) {
case 0:
item.setCompanyType(companyEl.childNode(0).toString());
System.out.println("公司类型:" + item.getCompanyType());
break;
case 2:
item.setCompanyDevelopmentStage(companyEl.childNode(2).toString());
System.out.println("公司发展阶段:" + item.getCompanyDevelopmentStage());
break;
case 4:
item.setCompanySize(companyEl.childNode(4).toString());
System.out.println("公司规模:" + item.getCompanySize());
break;
default:
break;
}
}
}
System.out.println("================================================================\n\n");
}
return jobSize;
}
}因为我们对数据没有什么处理,所以边封装就边打印查看了。

这个速度还是有点意思的。。
五、对比
从代码量上可以看得出来Go语言是最少的,尤其的简洁。。
从运行速度上可以看出来Go语言是执行最快的,耗时最短。。
然后每个语言也都有着不同的优缺点,所以也有着各自的发展领域。