PostgreSQL 中文全文检索 (使用zhparser)
前言:
PostgreSQL默认分词是按照空格及各种标点符号来分词,但是对于国内更多的是中文文章,按照默认分词方式不符合中文的分词方式。检索了网上很多文章,发现使用最多的是zhparser,并且是开源的,完成能够满足检索需求。
前置:
centOS7
PostgreSQL11
SCWS(下载地址:http://www.xunsearch.com/scws/down/scws-1.2.2.tar.bz2)
zhparser(GitHub地址:https://github.com/amutu/zhparser)
postgresql-devel
zhparser支持PostgreSQL 9.2及以上版本,请确保你的PG版本符合要求。 对于REDHAT/CentOS Linux系统,
请确保安装了相关的库和头文件,一般它们在postgresql-devel软件包中。
安装:
1、首先需要安装postgresql-devel
yum install postgresql-devel 或者 yum install postgresql11-devel (我这里使用的第一种,没有指定版本号)
![]()
如果不安装此软件包的话,在编译zhparser文件时会报pg_config: Command not found错误
![]()
2、安装SCWS
因为zhparser是基于SCWS(简易中文分词系统)开发的。所以必须首先安装SCWS。
·2.1 创建一个文件夹(这里不详细写创建步骤,这里我统一将SCWS和zhparser放在了/home/pgsql/下面)
·2.2 进入创建的文件夹

·2.3 下载SCWS
wget http://www.xunsearch.com/scws/down/scws-1.2.3.tar.bz2

·2.3 安装
[root@pg1 opt]# tar -jxvf scws-1.2.3.tar.bz2
[root@ecs-f49b-0003 pgsql]# cd scws-1.2.3 ; ./configure ; make install
注意:在FreeBSD release 10及以上版本上运行configure时,需要增加--with-pic选项。
如果是从github上下载的scws源码需要先运行以下命令生成configure文件:
touch README;aclocal;autoconf;autoheader;libtoolize;automake --add-missing
3、安装zhparser
·3.1 这里可以参考GitHub上的步骤,https://github.com/amutu/zhparser ,忽略创建extension步骤,这里需要按照下面步骤检查和创建extension ,与GitHub上写的略有不同(建议编译和安装zhparser时采用指定PG_CONFIG 的方式指定版本编译扩展,避免直接使用make && make install 编译结果与安装的数据库版本不一致)。
ps:因为在安装PostgreSQL时,我是用YUM方式安装的,clang并没有被加入,所以在指定 PG_CONFIG
版本编译扩展时可能会报--新增插件异常(clang: Command not found),或者直接编译不通过。
这里可以参考(https://yq.aliyun.com/articles/698119 ),关闭PostgreSQL新增插件的bc编译项来解决:
vim /usr/pgsql-11/lib/pgxs/src/makefiles/pgxs.mk
注释所有的with_llvm相关

下面是我编译后的结果,编译的文件没有直接放到pgsql中,下面图片中标注中的是最后编辑后文件的放置路径。(如果未出现相同的问题,那么就可以跳过文件整理步骤直接去创建extension。)

因为编译后的文件不在应该在的文件夹中,这里就需要手动去将文件移动至指定目录:
/usr/lib64/pgsql/zhparser.so → /usr/pgsql-11/lib (/usr/pgsql-11/是PostgreSQL安装后路径,如果PostgreSQL是使用的YUM安装方式,路径应该是一样)

/usr/share/pgsql/extension/ → /usr/pgsql-11/share/extension
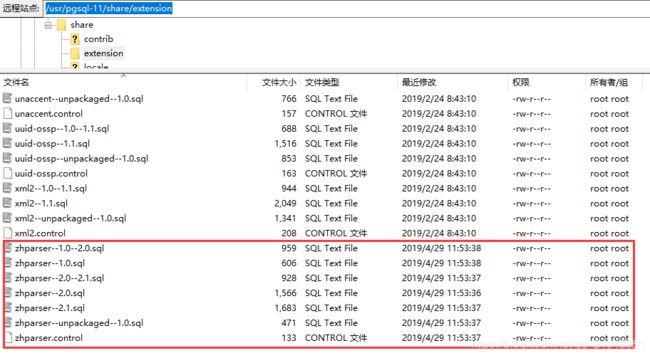
/usr/share/pgsql/tsearch_data/ → /usr/pgsql-11/share/tsearch_data
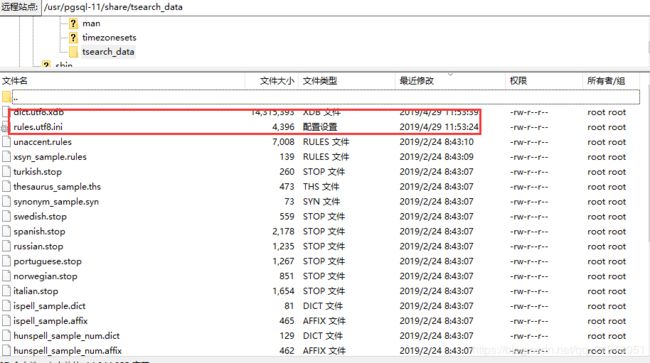
·3.2 创建extension
整理好这些文件后,就可以继续创建extension了。
·3.2.1 切换到postgres账户
su - postgres

·3.2.2 安装扩展(每新建一个数据库都需要执行这一步;这里我直接使用的已有的一个测试数据库)
#查询已有的解析器
knowledge=# \dFp

这里可以看到就只有一个默认的解析器。下面开始创建扩展:
knowledge=# create extension zhparser;

这里再来看一次已有的解析器:

这样解析器就添加到当前数据库了。但是此时还是不能用,还需要创建使用zhparser作为解析器的全文搜索的配置,也就是需要给zhparser解析器取一个在sql里面可以使用的名字。这里测试取的是(‘zh’)。

再继续向全文搜索配置中增加token映射:
knowledge=# ALTER TEXT SEARCH CONFIGURATION zh ADD MAPPING FOR n,v,a,i,e,l,j WITH simple;
![]()
这样就算是安装配置完成了。下面来测试一下效果:

追加问题解决
最近使用中遇到一个查询时的问题:
例如一篇文章中有“…合江县…”,分词分出来的就是合江县,如果查询的时候输入的是合江,那么是匹配不到的,所以这里需要在继续设置一下全文检索的复合等级;在命令行中使用上一节中介绍的 scws 命令测试分词配置,如我认为复合等级为 7 时分词结果最好,则我在 postgresql.conf添加配置:
zhparser.multi_short = true #短词复合: 1
zhparser.multi_duality = true #散字二元复合: 2
zhparser.multi_zmain = true #重要单字复合: 4
zhparser.multi_zall = false #全部单字复合: 8

然后重启数据库,将之前的分词重新全部生成一遍,在来查询,问题解决。
OK!!!这样就可以满足当前需求了,完工!!!