YoloV1、YoloV2和YoloV3实现细节和区别
YoloV1:对比R-CNN
出处:
《You Only Look Once: Unified, Real-Time Object Detection》
背景:
RCNN存在region proposal 过程,Selective Search每张图花费1~2秒,不能做到real-time
Proposals太多会出现很多假阳例
思想:
提出一个简单的卷积神经网络同时预测边框和预测类别
使用整个图的特征来预测来减少误差
不需要预处理和后处理
结构:
24层卷积+2层FC,3*3卷积下采样,1*1卷积减少特征空间

Our system divides the input image into a 7* 7 grid. If the center of an object falls into a grid cell, that grid cell is responsible for detecting that object. Each grid cell predicts a bounding box and class probabilities associated with that bounding box
输入是448*448*3,输出是7*7*30, 7*7对应每个grid,而20代表20个类的概率和10代表两个box的x y w h 和置信度

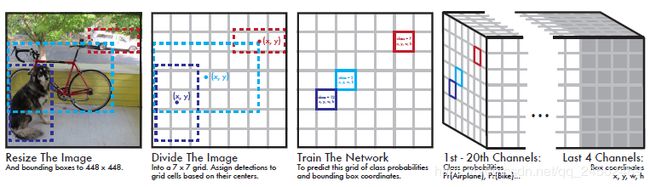
激活函数使用LeakyReLU,dropout
损失函数使用平方和误差
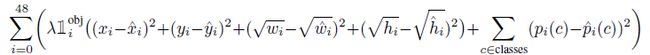
如果图中目标很少则预测值大多为0,因此

测试
每个grid cell预测的class信息和bounding box预测的confidence相乘,得到每个bounding box的class-specific confidence score:
缺点
测试尺度必须和训练尺度一致
每个grid只能预测一个物体
YoloV2:Faster R-CNN和SSD
出处:
《YOLO9000: Better, Faster, Stronger》
相对于V1,速度更快,准确率更高,识别类别更多,达到9000多种
Better:
Yolo会产生明显的定位错误,且召回率低
BN:
在Yolo的卷积层后添加BN,取得了2%的提升,帮助正则化模型,去除dropout
High Resolution Classifier:
相对于Yolo使用224*224来训练分类器,然后直接切换448*448来训练检测器,YOLO2在采用 224*224 图像进行分类模型预训练后,再采用 448*448 的高分辨率样本对分类模型进行微调(10个epoch),使网络特征逐渐适应 448*448 的分辨率。然后再使用 448*448 的检测样本进行训练,缓解了分辨率突然切换造成的影响,取得了3.7%提升
Convolutional With Anchor Boxes:
Yolo用全连接层直接预测框的坐标,Faster R-CNN使用RPN来预测偏移和置信度
Yolo在每个grid预设一组不同尺度比例的anchor,这些先验框作为预定义的候选区在神经网络中将检测其中是否存在对象,以及微调边框的位置。
同时去除池化层来提高输出的分辨率
调整输入的分辨率到416*416,下采样后是13*13,每个grid9个anchor,所以共有13*13*9=1521个anchor
Dimension Clusters
对训练集中标注的边框进行聚类分析,以寻找尽可能匹配样本的边框尺寸。对于常用的欧式距离,大边框会产生更大的误差,但我们关心的是边框的IOU。
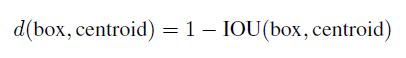
使用K-means,K=5。K个centroid边框,计算样本中标注的边框与各centroid的Avg IOU
Direct location prediction
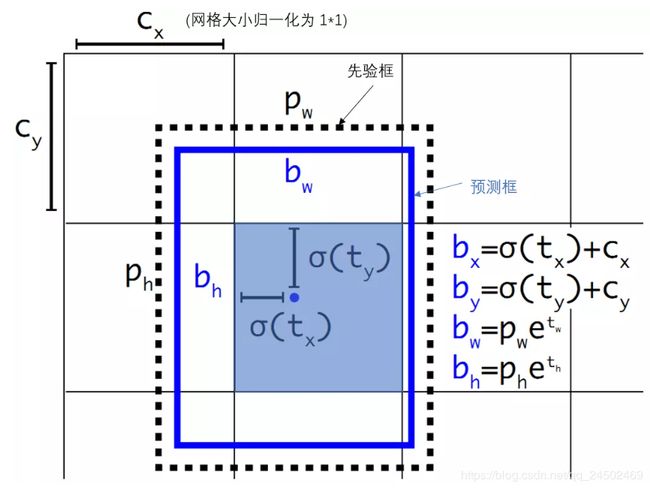
由于Faster RCNN参数取值没有任何约束,因此预测边框的中心可能出现在任何位置,训练早期阶段不容易稳定。YOLO调整了预测公式,将预测边框的中心约束在特定gird网格内。

首先将网格的宽高归一化到1,Cx,Cy是当前网格的左上角到整个图像的左上角的距离,Pw,Ph是当前先验框的宽高,而tx,ty,ew,eh是要学习的参数,用sigmoid将偏移量输出到(0, 1)。
passthrough层检测细粒度特征
图像中对象会有大有小,输入图像经过多层网络提取特征,最后输出的特征图中(YOLO2最后输出是13*13),较小的对象可能特征已经不明显甚至被忽略掉了
YOLO2引入一种称为passthrough层,在最后pooling之前,feature map大小是26*26*512,然后将这个map分成四份,所以是4*13*13*512,然后和池化后的13*13*1024直接拼接。
Yolo2代码用1*1卷积将通道数从512降到64


多尺度图像训练
因为去掉了全连接层,YOLO2可以输入任何尺寸的图像,作者采用了{320,352,...,608}等10种输入图像的尺寸
高分辨率图像的对象检测
因为YOLO2调整网络结构后能够支持多种尺寸的输入图像
Faster
DarkNet-19比VGG-16小一些,精度不弱于VGG-16,但浮点运算量减少到约1/5,以保证更快的运算速度。
YOLO2的训练主要包括三个阶段:
第一阶段就是先在ImageNet分类数据集上预训练Darknet-19,此时模型输入为 224*224。
第二阶段将网络的输入调整为 448*448 ,继续在ImageNet数据集上finetune分类模型。
第三个阶段就是修改Darknet-19分类模型为检测模型,移除最后一个卷积层、global avgpooling层以及softmax层,并且新增了三个 3*3*1024卷积层,同时增加了一个passthrough层,最后使用 1*1 卷积层输出预测结果,输出的channels数为:num_anchors*(5+num_classes)
总结就是:从416*416*3 变换到 13*13*5*25。稍微大一点的变化是增加了batch normalization,增加了一个passthrough层,去掉了全连接层,以及采用了5个先验框
损失函数:

YoloV3:对比
YOLO3采用了称之为Darknet-53的网络结构(含有53个卷积层),它借鉴了残差网络residual network的做法,在一些层之间设置了快捷链路
采用了3个不同尺度的特征图来进行对象检测
9种尺度的先验框