python 的垃圾回收机制(Garbage Collection)
以后都在 github 更新,请参考 python 垃圾回收
最近读了一些关于 Python 内部实现的博客,其中有几篇关于 Garbage Collection 的,在此分享一下
对于比较小块的内存(比如小于等于512bytes), 当你认为这个对象所占的内存需要被解释器回收时,解释器实际上不会对这块内存进行回收,而是保留起来,下次使用。这有点像 C++ 的默认的 std::allocator, C++ 默认的 std::allocator 会初始化一个链表,每个链表里面的对象都指向一段和操作系统申请的内存块,当你需要一个比较小的内存块时,直接从这个链表里找一块未被使用过的给你,并标记为使用中。这样做可以避免内存碎片,还有频繁的和操作系统申请内存,频繁的向操作系统申请内存是非常影响性能的。
我估计 Python 解释器的内存管理也使用了类似的方案,回头再来研究,这里讨论的是内存回收机制。
Python 主要使用以下两种方法进行内存回收:
1. 引用计数器(Reference Counting)
在Python中,所有你赋值/创建的变量都是指向这个真正的对象的引用,每一次赋值,引用数就会加一,每次这个变量销毁,这个真正的对象的引用数就会减一,当引用数变为0的时候,这个真正的对象就会被解释器的 Garbage Collector 回收, 达到释放内存的目的。
如果这个对象还含有指向其他对象的引用,那么这些被指向的其他对象的引用计数器都会减一(比如列表中含有好几个元素, 如果列表被删除,列表中的这些元素都会删除该索引)
import sys
a = []
# 一个来自变量a, 一个来自函数调用的传参
sys.getrefcount(a)
Out[4]: 2
# 来自函数调用的传参
sys.getrefcount([])
Out[5]: 1
2. 分代回收机制(Generational Garbage Collector)
引用计数器无法覆盖到所有的情况,比如 引用循环 或者 互相引用
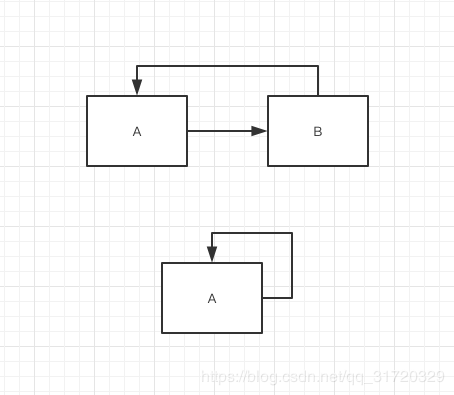
import gc
import sys
import ctypes
class PyObject(ctypes.Structure):
_fields_ = [("refcnt", ctypes.c_long)]
gc.disable()
lst = []
lst.append(lst)
lst_addr = id(lst)
lst
Out[3]: [[...]]
del lst
obj1 = dict()
obj2 = dict()
obj1["obj2"] = obj2
obj2["obj1"] = obj1
obj1_addr, obj2_addr = id(obj1), id(obj2)
del obj1
del obj2
print(PyObject.from_address(obj1_addr).refcnt)
1
print(PyObject.from_address(obj2_addr).refcnt)
1当你删除上面的对象以后,他们依然呆在内存中,这是因为他们的引用数都不为0, 基于引用计数器的回收机制自然没法回收到这类对象, 此时需要另一个算法来进行垃圾回收:
Generational Garbage Collector, 这个算法的触发和 Reference Counting 不太一样, 每当某个对象的引用数降到0, 就会触发 Reference Counting 算法,而 Generational Garbage Collector 是隔一段时间间隔启动一次
Generational 的意思是世代的,这个算法把仍然存活着的对象分成三个世代,我们叫一代,二代,三代(想象成三个容器)
所有通过Python解释器创建的对象都会存放在一代里,一次代际间垃圾回收完成后,一代中仍然存活的对象会存放到二代,同样,二代中仍然存活的对象会存放到三代,Python 默认认为新创建的对象普遍存活时间比较短,所以低代中的容器回收频率会比高代的回收频率要高,比如一代回收频率大于二代,二代回收频率大于三代
每一个世代都会保留一个阈值(threshold) 还有 当前世代内存活的对象数量, 每次触发这个回收机制时,从高代到低代依次检测存活的数量是否超过阈值,如果超过,就回收当前这一代(回收算法会把低代也一并回收, 比如回收二代的时候,一代内存活的对象也会一并回收),这个阈值是可以查看也是可以设置的
import gc
gc.get_threshold()
Out[15]: (700, 10, 10)
gc.set_threshold(80)
gc.get_threshold()
Out[26]: (80, 10, 10)
gc.set_threshold(800, 100, 100)
gc.get_threshold()
Out[28]: (800, 100, 100)
分代回收机制(Generational Garbage Collector) 工作原理
引用计数器(Reference Counting) 算法很好理解,我就不多描述了,下面来讲一讲 代际间的垃圾回收机制(Generational Garbage Collector) 是如何工作的
你可以在 github 源码上面找到 gc.collect 这个函数, 比如回收第一代的时候,第一代里面是这样的
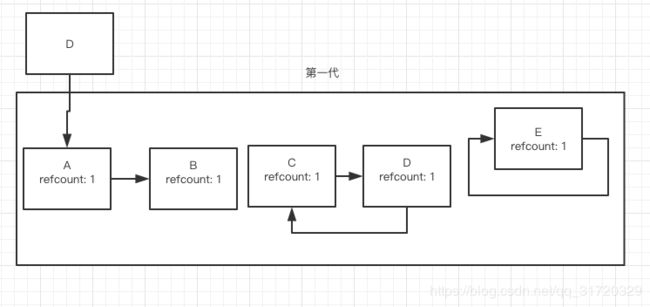
第一步创建一个临时容器,然后对第一代中的每一个对象的索引数做一个备份

然后遍历每个第一代中的对象,将每个对象指向的,在同一代里面的对象的 备份索引数减一,这一步是为了去除掉同一代里面的相互索引,或者索引循环, 比如对象A,含有一个第一代以外的索引,这个索引不会被减一
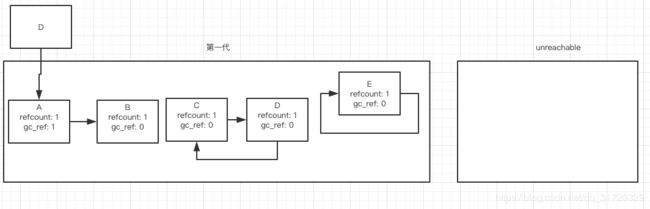
此时,遍历所有第一代中的对象,
- 把 gc_ref 为 0 的对象标记为 UNREACHABLE 并移到临时容器中,并标记为 UNREACHABLE
- 把所有 gc_ref 不为 0 的对象留在 第一代中,并标记为 REACHABLE, 如果 标记为 REACHABLE 含有指向在同一代中的指引,则指向的对象也保留在 第一代中并标记为 REACHABLE
第一步之后:
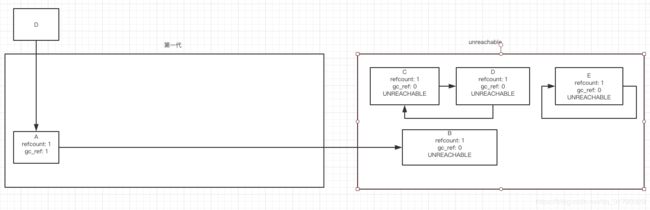
第二步之后:
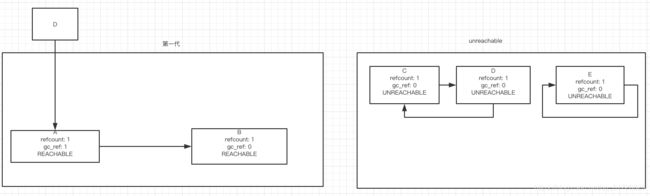
此时,临时容器里面的对象可以被回收释放,第一代里面存活的对象会被升级到第二代,本次垃圾回收就结束了
定义了 __del__ 函数的对象
在 Python3.3 以前,所有定义了该函数的对象是不参与回收的,因为不知道你是否会在这个函数里面给该对象添加新的索引
Python 3.4 以后定义了 __del__ 函数的对象在标记为 UNREACHABLE 之后,又移回第N代中进行 ref_count 的检测,重新标记,再度回收,如果你的 __del__ 函数增加了某个对象的索引导致没有被回收到,__del__ 函数会被执行,但是这个对象会依然存活着,所以通常情况下不要自定义这个函数。而且据个人经验,除非你显式的 del 某个对象,你无法知道解释器什么时候释放你创建的对象。如果你创建了某个存活时间很长的对象,并且你在 __del__ 函数执行了 print, fclose, logging 等操作的时候,很可能 print/logging 这些模块已经不在了,解释器先释放了这些资源,再来执行你的 __del__ 函数
参考资料:
Garbage collection in Python: things you need to know
The Garbage Collector
Cpython 源码