软件测试之MySQL数据库必知必会,面试必备!
软件测试之MySQL数据库必知必会,面试必备!
- 一、前言
- 1.1 数据库概念及分类
- 1.2 SQL语句概念及分类
- 1.3 MySQL数据类型
- 二、常用SQL语句
- 2.1 数据库相关SQL
- 2.2 表相关SQL
- 2.3 修改表相关SQL
- 2.4 操作表记录相关SQL
- 三、DQL(查询)详解
- 3.1 条件查询
- 3.2 别名、去重
- 3.3 排序、分页查询
- 3.4 聚合函数、时间相关函数
- 3.5 分组与having
- 3.6 子查询
- 3.7 关联查询
- 四、约束、索引、存储过程、事务
- 4.1 约束
- 4.2 索引
- 4.3 存储过程
- 4.4 事务
- 五、相关面试题
- 分组(group by) + 聚合函数筛选(having) + join on(关联查询)——第12题
- 自连接——第19题
- 使用同一个表两次、解题思路——第24题
一、前言
1.1 数据库概念及分类
首先,我们经常说的
MySQL是一个数据库管理系统,而非数据库。数据库是组织、存储和管理数据的仓库,存储数据的容器。而数据库管理系统是操纵和管理数据库的大型软件,建立、使用和维护数据库。数据表是真正的数据存储单元,其他对象的基础。三者之间的关系为:一个数据库管理系统维护了多个数据库,一个数据库包含若干数据表。
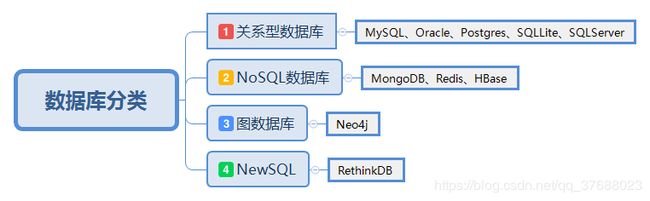
关于数据库的分类,可能有很多种分类。一般来说,我们用到最多的就是
关系型数据库和NoSQL数据库。而其中关系型数据库又是应用最为广泛的。
1.2 SQL语句概念及分类
SQL:一种
结构化查询语句,用于访问和操作数据库的标准计算机语言。通常用途为操作数据库对象(表、存储过程、函数、索引),表记录的增删改查。SQL是一门弱语言,不区分大小写。通常,将SQL语句分为下面五大类。

1.3 MySQL数据类型
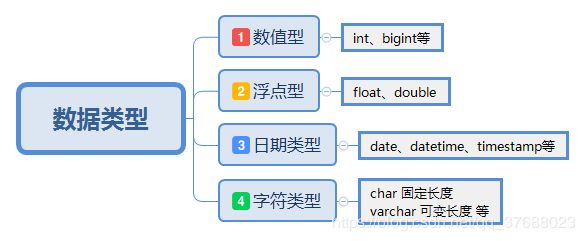
MySQL支持多种数据类型,大致可以分为四大类,如下图所示。关于MySQL数据类型的详细内容,请参考链接 MySQL常见的数据类型
二、常用SQL语句
2.1 数据库相关SQL
- 查询所有数据库
show databases; - 创建数据库
create database 数据库名称; - 删除数据库
drop database 数据库名称; - 查询数据库详情、查看数据库的字符集
show create database 数据库名称; - 创建指定字符集数据库
##创建数据库语句后面用character set设置数据库字符集,注意这里是utf8,不是utf-8 create database 数据库名称 character set gbk/utf8; - 选中数据库
use 数据库名称;
2.2 表相关SQL
如果不借助工具的情况下,在命令中输入下面相关的命令,需要先使用
use 数据库名选择要操作表所属的数据库。
- 创建表
##创建数据库表语句如下: CREATE TABLE IF NOT EXISTS 表名( 字段名1 字段类型, 字段名2 字段类型 )ENGINE=InnoDB DEFAULT CHARSET=utf8; ## 实际案例语句 CREATE TABLE IF NOT EXISTS NUMBER( ID INT NOT NULL AUTO_INCREMENT, USERNAME VARCHAR(40), PRIMARY KEY (ID) )ENGINE=INNODB DEFAULT CHARSET=UTF8; - 查询所有表
show tables; - 查询表详情
show create table 表名; - 查看表结构
desc 表名; - 删除表
drop table 表名;
2.3 修改表相关SQL
关于修改表相关的SQL,除了修改表前没加
alter table 表名,其他都是在该基础添加的语句。这部分的SQL一般来说在实际工作中用的不多,因为相关操作都可以借助Navicat实现。
- 修改表名
rename table 原表名 to 新表名; - 修改表引擎和字符集
alter table 表名 engine=innodb/myisam charset=gbk; - 添加表字段(在最后)
alter table 表名 add 字段名 字段类型; - 添加表字段(最前面)
alter table 表名 add 字段名 字段类型 first; - 添加字段(某个字段后添加)
alter table 表名 add 字段名A 字段A类型 after 字段名B; - 删除表字段
alter table 表名 drop 字段名; - 修改表字段名称和类型
alter table 表名 change字段名 原字段名 新字段名 新类型;
2.4 操作表记录相关SQL
对于测试工程师而言,SQL语言中最常用的就是DML——数据操作语言,即为增删改查。而其中
用到最多的就是DQL——数据查询语句。
- 插入数据(全表插入)
insert into 表名 values (字段1值,字段2值); insert into 表名 values (字段1值,字段2值),(字段1值,字段2值); - 插入数据(指定字段)
insert into 表名 (字段1,字段2) values (值1,值2); insert into 表名 (字段1,字段2) values (值1,值2),(值1,值2); - 删除数据
#删除指定数据 delete from 表名 where 字段名=值; #删除表中全部数据 delete from 表名; - 修改数据
#修改指定值 update 表名 set 字段名=值1 where 字段名=值2; #修改全部值 update 表名 set 字段名=值1; - 查询数据
#查询所有 select * from 表名
三、DQL(查询)详解
DQL即为数据查询语句,也是使用最多的一种SQL语句。将该部分的内容分为以下几部分:其中最为常用的是
关联查询、分组、分页、排序、条件查询这几种。对于其中常用的where 、group by、having、order by、limit,其顺序为:·select * from 表A join 表B on 条件 where 条件 group by 分组字段 having 聚合函数过滤 order by 排序字段 limit ...
3.1 条件查询
- 判断是否为空(
is null、is not null)# is null代表为空 is not null代表不为空 #案例 查看图书借阅表中归还时间为空的借阅记录 SELECT * FROM book_borrow WHERE return_time is NULL; - 比较运行符(
>、<、>=、<=、!=、<>)#分别代表大于、小于、大于等于、小于等于、不等于、不等于 #案例 查看图书表中图书id大于2的图书信息 SELECT * FROM book WHERE book_id>2 and和or## 等同于 &&和 || ,表示同时满足两个条件和满足两个条件中一个 ## 案例1:查询图书借阅表中用户id和图书id都为1的图书信息 SELECT * FROM book_borrow WHERE user_id=1 AND book_id=1; ##案例2:查询图书借阅表中用户id为1或者图书id为1的图书信息 SELECT * FROM book_borrow WHERE user_id=1 OR book_id=1;in在某些可选值范围内# select * from 表名 where 字段 in (值1,值2,值3); # 案例1 查询图书借阅表中读者id在1,2,3范围内 SELECT * FROM book_borrow WHERE user_id in (1,2,3);between和not between# 字段 between 值1 and 值2; 字段在值1和值2之间 #案例1:查询图书借阅表中读者id在1-2范围内,包含1和2 SELECT * FROM book_borrow WHERE user_id BETWEEN 1 AND 2;- 模糊查询
like_代表单个字符,%代表0个或多个字符# 案例1 查询图书表中图书名字为两个字符,且图书名第一个字为三的图书信息 SELECT * FROM book WHERE book_name LIKE '三_'; # 案例2 查询图书表中图书名以天才开头的图书信息 SELECT * FROM book WHERE book_name LIKE '天才%';
3.2 别名、去重
- 别名——使用
as关键字或空格 给表名或字段别名# 案例 查询图书表中图书名称为‘天才在左 疯子在右’的作者 SELECT b.author as 作者 FROM book b WHERE b.book_name ='天才在左 疯子在右'; - 去重——使用
distinct对查询出来的去重#案例 查询员工表中所有的员工名称,且不重复 select distinct employeeName from employee;
3.3 排序、分页查询
- 排序——
order by(ASC 升序 默认、DESC 降序 )#案例:查询学生表数据并以id降序、年龄升序排序 select * from student order by id desc,age; - 分页查询——
limit 跳过条数A 每页数量B#案例 查询学生表中年龄第三大的学生信息 select * from student order by age desc limit 2,1; #分页查询sql的格式为 start为页码 pageSize是每页显示的条数 select * from table limit (start-1)*pageSize,pageSize;
3.4 聚合函数、时间相关函数
- 聚合函数——sum(字段名) 求和
#案例 对分数表中分数进行求和 SELECT SUM(a.score) FROM table_socre as a; - 聚合函数——avg(字段名) 平均值
#案例 求分数表中分数平均值 SELECT AVG(a.score) FROM table_socre as a; - 聚合函数——max(字段名) 最大值
#案例 求分数表中最大值 SELECT MAX(a.score) FROM table_socre as a; - 聚合函数——min(字段名) 最小值
#案例 求分数表中最小值 SELECT MIN(a.score) FROM table_socre as a; - 聚合函数——count(字段名) 统计数量
#实例 查询图书表中图书总数 SELECT COUNT(*) as 图书总数 FROM book 注意点,count()函数的扩号中也可以填写字段,如果 字段的值为0,则不参与合计 - 时间函数——now() 当前年月日时分秒
SELECT NOW(); #输出当前时间 2020-07-03 23:21:03 - 时间函数——current_date() 当前时间年月日
SELECT CURRENT_DATE(); #输出当前时间年月日 2020-07-03
3.5 分组与having
- 分组——
group by
group by的常规用法是配合聚合函数,利用分组信息进行统计。#案例 以title字段分组,查询每个分组中score的最大值 SELECT t.t.title,MAX(score) FROM table_socre t GROUP BY t.title; having——解决聚合函数过滤问题,一般配合group by一起使用。#案例 以title字段分组,查询每个分组中score的最大值,并且通过最大值必须大于20来过滤数据 SELECT t.t.title,MAX(score) FROM table_socre t GROUP BY t.title having MAX(score)>20;
3.6 子查询
- 写在where/having后作为查询条件的值
#案例 查询员工工资最低的员工信息,由于可能最低有多个员工,所以需要先查询出最低工资 SELECT * FROM employees WHERE salary=( SELECT MIN(salary) FROM employees ); 临时表——用在from后面,当做一个新表,新表必须有名称#案例 将一个查询结果作为一个新表,让后从这个新表中查询数据 select cou,name from (select count(*) AS cou,enabled AS name from `user` group by enabled ) as a where cou>0
3.7 关联查询
参考链接:Mysql中的关联查询(内连接,外连接,自连接)
- 内连接——
表A inner join 表B on 条件,特点:只查询连接的表中能够有对应的记录的数据#查询员工姓名及对应部门名称 没有部门的人员和没有人员的部门都不显示 SELECT e.empName, d.deptName FROM t_employee e INNER JOIN t_dept d ON e.dept = d.id; - 左外连接——
表A left join 表B on 条件,特点:以左边的表的数据为基准,去匹配右边的表的数据,如果匹配到就显示,匹配不到就显示为null#查询员工表中员工姓名及对应部门名称,若员工没有部门,则显示null SELECT e.empName, d.deptName FROM t_employee e LEFT JOIN t_dept d ON d.id = e.dept; - 右外连接——
表A right join 表B on 条件,特点:与坐外连接类似,只是基准表变了,用右表去匹配左表。所以左外连接能做到的事情,右外连接也能做到。#查询所有部门和对应的员工,如果部门没有员工,则显示null SELECT e.empName, d.deptName FROM t_employee e RIGHT JOIN t_dept d ON d.id = e.dept; - 自连接——当前表与自身连接查询
#查询员工以及他的上司的名称,由于上司也是员工,所以这里虚拟化出一张上司表 SELECT e.empName, b.empName FROM t_employee e LEFT JOIN t_employee b ON e.bossId = b.id;
四、约束、索引、存储过程、事务
4.1 约束
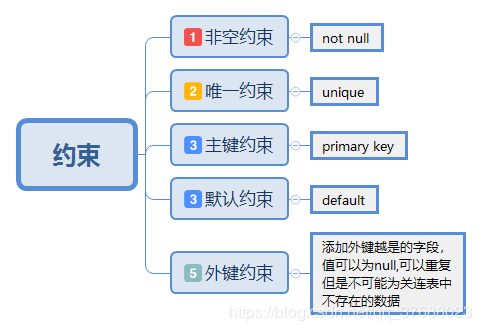
MySQL中约束是一种
限制,它通过对表的行或列的数据做出限制,来确保表的数据的完整性、唯一性。
4.2 索引
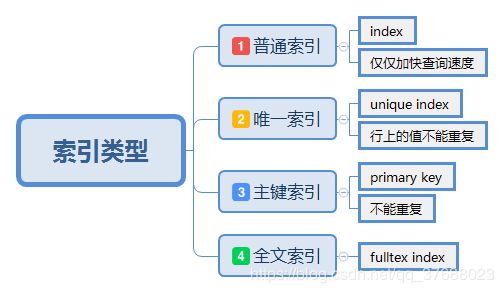
MySQL中的索引是一种高效获取数据的存储结构——
B+Tree;MySQL中索引的好处在于加快查询速度,坏处就是降低了增删改的速度,增大了表的文件大小(索引文件可能比数据文件还要大)。MySQL索引实现原理可以参考:mysql索引实现原理
#1.如何创建索引 注意:添加主键约束是,会自动创建主键字段的索引
create index 索引名 on 表名(字段);
#2.查看索引
show index from 表名;
#3.删除索引
drop index 索引名 on 表名;
4.3 存储过程
MySQL中存储过程
类似于函数,就是把一段代码封装起来,当要执行这一段代码的时候,可以通过调用该存储过程来实现。
#1.查看数据库中的存储过程
show procedure status;
#2.查看存储过程的创建代码
show create PROCEDURE 存储过程名;
#3.创建存储过程
CREATE PROCEDURE 名称()
BEGIN
.........
END
#4.创建存储过程,并执行存储过程
#4.1创建存储过程
drop procedure if exists proc_addNum;
create procedure proc_addNum (in x int,in y int,out sum int)
BEGIN
SET sum= x + y;
end
#4.2执行过程,out输出返回值
call proc_addNum(2,3,@sum);
select @sum;
4.4 事务
参考链接:MySQL数据库事务的四大特性以及事务的隔离级别
事务:是数据库中执行SQL语句的工作单元,可以保证事务内的SQL语句要么全部成功,要么全部失败。

五、相关面试题
对于软件测试而言,在MySQL数据库相关的面试题中,除了上面
MySQL数据库相关的概念,最重要的就是DQL语句的编写。关于DQL相关语句的考题,可以直接参考牛客网中SQL实战编程:牛客网SQL实战。
分组(group by) + 聚合函数筛选(having) + join on(关联查询)——第12题
#获取部门中员工薪水最高相关信息
SELECT
B.dept_no,
B.emp_no,
A.salary AS salary
FROM
salaries AS A
JOIN dept_emp AS B ON A.emp_no = B.emp_no
WHERE
A.to_date = '9999-01-01'
AND B.to_date = '9999-01-01'
GROUP BY
B.dept_no
HAVING
A.salary = max( A.salary );
自连接——第19题
#查看薪水第二多的员工信息(不使用order by)
#思路一:查询最大薪水,然后查询小于最大薪水的薪水值中的最大值
SELECT
e.emp_no,
s.salary,
e.last_name,
e.first_name
FROM
employees e
JOIN salaries s ON e.emp_no = s.emp_no
AND s.to_date = '9999-01-01'
AND s.salary = (
SELECT
max( salary )
FROM
salaries
WHERE
salary < ( SELECT max( salary ) FROM salaries WHERE to_date = '9999-01-01' )
AND to_date = '9999-01-01'
)
#思路二:对薪水表自连接,使用s1.salary <= s2.salary查询出第二多薪水
SELECT
e.emp_no,
s.salary,
e.last_name,
e.first_name
FROM
employees e
JOIN salaries s ON e.emp_no = s.emp_no
AND s.to_date = '9999-01-01'
AND s.salary = (
SELECT
s1.salary
FROM
salaries s1
JOIN salaries s2 ON s1.salary <= s2.salary
AND s1.to_date = '9999-01-01'
AND s2.to_date = '9999-01-01'
GROUP BY
s1.salary
HAVING
count( DISTINCT s2.salary ) = 2
)
使用同一个表两次、解题思路——第24题
#获取员工其当前的薪水比其manager当前薪水还高的相关信息
#1.先查出员工的工号和薪水:
SELECT
de.emp_no,
sa.salary
FROM
dept_emp de,
salaries sa
WHERE
de.emp_no = sa.emp_no
AND de.to_date = '9999-01-01'
AND sa.to_date = '9999-01-01'
#2.再查出经理的工号和薪水:
SELECT
dm.emp_no manager_no,
sal.salary
FROM
dept_manager dm,
salaries sal
WHERE
dm.emp_no = sal.emp_no
AND dm.to_date = '9999-01-01'
AND sal.to_date = '9999-01-01'
#3.最后就是组合,看准条件,做好条件衔接
SELECT
de.emp_no,
dm.emp_no manager_no,
sa.salary emp_salary,
sal.salary manager_salary
FROM
dept_emp de,
salaries sa,
dept_manager dm,
salaries sal
WHERE
de.emp_no = sa.emp_no
AND dm.emp_no = sal.emp_no
AND de.dept_no = dm.dept_no
AND de.to_date = '9999-01-01'
AND sa.to_date = '9999-01-01'
AND dm.to_date = '9999-01-01'
AND sal.to_date = '9999-01-01'
AND sa.salary > sal.salary
对于测试工程师而言,在面试中,应该不会遇到特别难的SQL题目。且工作中,对于SQL要求不会特别高,重点在于根据需求梳理好思路,然后编写相关的SQL,对于其SQL的效率不回特别追求。