PyTorch——YOLOv1代码学习笔记
文章目录
- 数据读取 dataset.py
- 损失函数 yoloLoss.py
数据读取 dataset.py
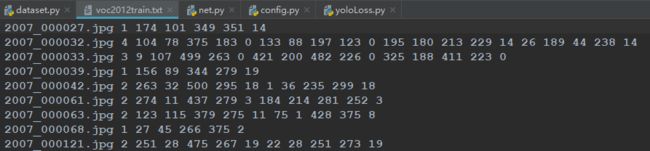
txt格式:[图片名字 目标个数 左上角坐标x 左上角坐标y 右下角坐标x 右下角坐标y 类别]
数据读取代码部分最终返回的item是(img, label),其中img是读取并处理好的图像矩阵224x224大小,label是一个7x7x30的矩阵,包含了bbox坐标和类别信息。一张图被分为7x7的网格;30=(2x5+20),一个网格预测两个框 , 一个网格预测所有分类概率,VOC数据集分类为20类。
#encoding:utf-8
#
'''
txt描述文件 image_name.jpg num x_min y_min x_max y_max c x_min y_min x_max y_max c 这样就是说一张图片中有两个目标
'''
import os
import sys
import os.path
import random
import numpy as np
import torch
import torch.utils.data as data
import torchvision.transforms as transforms
import cv2
class yoloDataset(data.Dataset):
'''
自定义封装数据集
'''
image_size = 224
def __init__(self,root,list_file,train,transform):
print('数据初始化')
self.root=root
self.train = train
self.transform=transform #对图像转化
self.fnames = [] #图像名字
self.boxes = []
self.labels = []
self.mean = (123,117,104) #RGB均值
with open(list_file) as f:
lines = f.readlines()
# 遍历voc2012train.txt每一行
for line in lines:
splited = line.strip().split()
# 赋值图像名字
self.fnames.append(splited[0])
# 赋值一张图的物体总数
num_faces = int(splited[1])
box=[]
label=[]
# 遍历一张图的所有物体
# bbox坐标(4个值) 物体对应的类的序号(1个值) 所以要加5*i
for i in range(num_faces):
x = float(splited[2+5*i])
y = float(splited[3+5*i])
x2 = float(splited[4+5*i])
y2 = float(splited[5+5*i])
c = splited[6+5*i]
box.append([x,y,x2,y2])
label.append(int(c)+1)
# bbox 写入所有物体的坐标值
self.boxes.append(torch.Tensor(box))
# label 写入标签
self.labels.append(torch.LongTensor(label))
# 数据集中图像总数
self.num_samples = len(self.boxes)
def __getitem__(self,idx):
'''
继承Dataset,需实现该方法,得到一个item
'''
fname = self.fnames[idx]
# 读取图像
img = cv2.imread(os.path.join(self.root+fname))
# clone 深复制,不共享内存
# 拿出对应的bbox及 标签对应的序号
boxes = self.boxes[idx].clone()
labels = self.labels[idx].clone()
# 如果为训练集,进行数据增强
if self.train:
# 随机翻转
img, boxes = self.random_flip(img, boxes)
#固定住高度,以0.6-1.4伸缩宽度,做图像形变
img,boxes = self.randomScale(img,boxes)
# 随机模糊
img = self.randomBlur(img)
# 随机亮度
img = self.RandomBrightness(img)
# 随机色调
img = self.RandomHue(img)
# 随机饱和度
img = self.RandomSaturation(img)
# 随机转换
img,boxes,labels = self.randomShift(img,boxes,labels)
h,w,_ = img.shape
boxes /= torch.Tensor([w,h,w,h]).expand_as(boxes)
img = self.BGR2RGB(img) #因为pytorch自身提供的预训练好的模型期望的输入是RGB
img = self.subMean(img,self.mean) #减去均值
img = cv2.resize(img,(self.image_size,self.image_size)) #改变形状到(224,224)
# 拿到图像对应的真值,以便计算loss
target = self.encoder(boxes,labels)# 7x7x30 一张图被分为7x7的网格;30=(2x5+20) 一个网格预测两个框 一个网格预测所有分类概率,VOC数据集分类为20类
# 图像转化
for t in self.transform:
img = t(img)
#返回 最终处理好的img 以及 对应的 真值target(形状为网络的输出结果的大小)
return img,target
def __len__(self):
'''
继承Dataset,需实现该方法,得到数据集中图像总数
'''
return self.num_samples
def encoder(self,boxes,labels):
'''
boxes (tensor) [[x1,y1,x2,y2],[x1,y1,x2,y2],[]]
labels (tensor) [...]
return 7x7x30
'''
target = torch.zeros((7,7,30))
cell_size = 1./7
# boxes[:, 2:]代表 2: 代表xmax,ymax
# boxes[:, :2]代表 :2 代表xmin,ymin
# wh代表 bbox的宽(xmax-xmin)和高(ymax-ymin)
wh = boxes[:,2:]-boxes[:,:2]
# bbox的中心点坐标
cxcy = (boxes[:,2:]+boxes[:,:2])/2
# cxcy.size()[0]代表 一张图像的物体总数
# 遍历一张图像的物体总数
for i in range(cxcy.size()[0]):
# 拿到第i行数据,即第i个bbox的中心点坐标(相对于整张图,取值在0-1之间)
cxcy_sample = cxcy[i]
# ceil返回数字的上入整数
# cxcy_sample为一个物体的中心点坐标,求该坐标位于7x7网格的哪个网格
# cxcy_sample坐标在0-1之间 现在求它再0-7之间的值,故乘以7
# ij长度为2,代表7x7框的某一个框 负责预测一个物体
ij = (cxcy_sample/cell_size).ceil()-1
# 每行的第4和第9的值设置为1,即每个网格提供的两个真实候选框 框住物体的概率是1.
#xml中坐标理解:原图像左上角为原点,右边为x轴,下边为y轴。
# 而二维矩阵(x,y) x代表第几行,y代表第几列
# 假设ij为(1,2) 代表x轴方向长度为1,y轴方向长度为2
# 二维矩阵取(2,1) 从0开始,代表第2行,第1列的值
# 画一下图就明白了
target[int(ij[1]),int(ij[0]),4] = 1
target[int(ij[1]),int(ij[0]),9] = 1
# 加9是因为前0-9为两个真实候选款的值。后10-20为20分类 将对应分类标为1
target[int(ij[1]),int(ij[0]),int(labels[i])+9] = 1
# 匹配到的网格的左上角的坐标(取值在0-1之间)(原作者)
# 根据二维矩阵的性质,从上到下 从左到右
xy = ij*cell_size
#cxcy_sample:第i个bbox的中心点坐标 xy:匹配到的网格的左上角相对坐标
# delta_xy:真实框的中心点坐标相对于 位于该中心点所在网格的左上角 的相对坐标,此时可以将网格的左上角看做原点,你这点相对于原点的位置。取值在0-1,但是比1/7小
delta_xy = (cxcy_sample -xy)/cell_size
# x,y代表了检测框中心相对于网格边框的坐标。w,h的取值相对于整幅图像的尺寸
# 写入一个网格对应两个框的x,y, wh:bbox的宽(xmax-xmin)和高(ymax-ymin)(取值在0-1之间)
target[int(ij[1]),int(ij[0]),2:4] = wh[i]
target[int(ij[1]),int(ij[0]),:2] = delta_xy
target[int(ij[1]),int(ij[0]),7:9] = wh[i]
target[int(ij[1]),int(ij[0]),5:7] = delta_xy
return target
def BGR2RGB(self,img):
return cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
def BGR2HSV(self,img):
return cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
def HSV2BGR(self,img):
return cv2.cvtColor(img,cv2.COLOR_HSV2BGR)
def RandomBrightness(self,bgr):
if random.random() < 0.5:
hsv = self.BGR2HSV(bgr)
h,s,v = cv2.split(hsv)
adjust = random.choice([0.5,1.5])
v = v*adjust
v = np.clip(v, 0, 255).astype(hsv.dtype)
hsv = cv2.merge((h,s,v))
bgr = self.HSV2BGR(hsv)
return bgr
def RandomSaturation(self,bgr):
if random.random() < 0.5:
hsv = self.BGR2HSV(bgr)
h,s,v = cv2.split(hsv)
adjust = random.choice([0.5,1.5])
s = s*adjust
s = np.clip(s, 0, 255).astype(hsv.dtype)
hsv = cv2.merge((h,s,v))
bgr = self.HSV2BGR(hsv)
return bgr
def RandomHue(self,bgr):
if random.random() < 0.5:
hsv = self.BGR2HSV(bgr)
h,s,v = cv2.split(hsv)
adjust = random.choice([0.5,1.5])
h = h*adjust
h = np.clip(h, 0, 255).astype(hsv.dtype)
hsv = cv2.merge((h,s,v))
bgr = self.HSV2BGR(hsv)
return bgr
def randomBlur(self,bgr):
'''
随机模糊
'''
if random.random()<0.5:
bgr = cv2.blur(bgr,(5,5))
return bgr
def randomShift(self,bgr,boxes,labels):
#平移变换
center = (boxes[:,2:]+boxes[:,:2])/2
if random.random() <0.5:
height,width,c = bgr.shape
after_shfit_image = np.zeros((height,width,c),dtype=bgr.dtype)
after_shfit_image[:,:,:] = (104,117,123) #bgr
shift_x = random.uniform(-width*0.2,width*0.2)
shift_y = random.uniform(-height*0.2,height*0.2)
#print(bgr.shape,shift_x,shift_y)
#原图像的平移
if shift_x>=0 and shift_y>=0:
after_shfit_image[int(shift_y):,int(shift_x):,:] = bgr[:height-int(shift_y),:width-int(shift_x),:]
elif shift_x>=0 and shift_y<0:
after_shfit_image[:height+int(shift_y),int(shift_x):,:] = bgr[-int(shift_y):,:width-int(shift_x),:]
elif shift_x <0 and shift_y >=0:
after_shfit_image[int(shift_y):,:width+int(shift_x),:] = bgr[:height-int(shift_y),-int(shift_x):,:]
elif shift_x<0 and shift_y<0:
after_shfit_image[:height+int(shift_y),:width+int(shift_x),:] = bgr[-int(shift_y):,-int(shift_x):,:]
shift_xy = torch.FloatTensor([[int(shift_x),int(shift_y)]]).expand_as(center)
center = center + shift_xy
mask1 = (center[:,0] >0) & (center[:,0] < width)
mask2 = (center[:,1] >0) & (center[:,1] < height)
mask = (mask1 & mask2).view(-1,1)
boxes_in = boxes[mask.expand_as(boxes)].view(-1,4)
if len(boxes_in) == 0:
return bgr,boxes,labels
box_shift = torch.FloatTensor([[int(shift_x),int(shift_y),int(shift_x),int(shift_y)]]).expand_as(boxes_in)
boxes_in = boxes_in+box_shift
labels_in = labels[mask.view(-1)]
return after_shfit_image,boxes_in,labels_in
return bgr,boxes,labels
def randomScale(self,bgr,boxes):
#固定住高度,以0.6-1.4伸缩宽度,做图像形变
if random.random() < 0.5:
scale = random.uniform(0.6,1.4)
height,width,c = bgr.shape
bgr = cv2.resize(bgr,(int(width*scale),height))
scale_tensor = torch.FloatTensor([[scale,1,scale,1]]).expand_as(boxes)
boxes = boxes * scale_tensor
return bgr,boxes
return bgr,boxes
def randomCrop(self,bgr,boxes,labels):
if random.random() < 0.5:
center = (boxes[:,2:]+boxes[:,:2])/2
height,width,c = bgr.shape
h = random.uniform(0.6*height,height)
w = random.uniform(0.6*width,width)
x = random.uniform(0,width-w)
y = random.uniform(0,height-h)
x,y,h,w = int(x),int(y),int(h),int(w)
center = center - torch.FloatTensor([[x,y]]).expand_as(center)
mask1 = (center[:,0]>0) & (center[:,0]<w)
mask2 = (center[:,1]>0) & (center[:,1]<h)
mask = (mask1 & mask2).view(-1,1)
boxes_in = boxes[mask.expand_as(boxes)].view(-1,4)
if(len(boxes_in)==0):
return bgr,boxes,labels
box_shift = torch.FloatTensor([[x,y,x,y]]).expand_as(boxes_in)
boxes_in = boxes_in - box_shift
labels_in = labels[mask.view(-1)]
img_croped = bgr[y:y+h,x:x+w,:]
return img_croped,boxes_in,labels_in
return bgr,boxes,labels
def subMean(self,bgr,mean):
mean = np.array(mean, dtype=np.float32)
bgr = bgr - mean
return bgr
def random_flip(self, im, boxes):
'''
随机翻转
'''
if random.random() < 0.5:
im_lr = np.fliplr(im).copy()
h,w,_ = im.shape
xmin = w - boxes[:,2]
xmax = w - boxes[:,0]
boxes[:,0] = xmin
boxes[:,2] = xmax
return im_lr, boxes
return im, boxes
def random_bright(self, im, delta=16):
alpha = random.random()
if alpha > 0.3:
im = im * alpha + random.randrange(-delta,delta)
im = im.clip(min=0,max=255).astype(np.uint8)
return im
损失函数 yoloLoss.py
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
class yoloLoss(nn.Module):
'''
定义一个torch.nn中并未实现的网络层,以使得代码更加模块化
torch.nn.Modules相当于是对网络某种层的封装,包括网络结构以及网络参数,和其他有用的操作如输出参数
继承Modules类,需实现__init__()方法,以及forward()方法
'''
def __init__(self,S,B,l_coord,l_noobj):
super(yoloLoss,self).__init__()
self.S = S #7代表将图像分为7x7的网格
self.B = B #2代表一个网格预测两个框
self.l_coord = l_coord #5代表 λcoord 更重视8维的坐标预测
self.l_noobj = l_noobj #0.5代表没有object的bbox的confidence loss
def compute_iou(self, box1, box2):
'''
计算两个框的重叠率IOU
通过两组框的联合计算交集,每个框为[x1,y1,x2,y2]。
Compute the intersection over union of two set of boxes, each box is [x1,y1,x2,y2].
Args:
box1: (tensor) bounding boxes, sized [N,4].
box2: (tensor) bounding boxes, sized [M,4].
Return:
(tensor) iou, sized [N,M].
'''
N = box1.size(0)
M = box2.size(0)
lt = torch.max(
box1[:,:2].unsqueeze(1).expand(N,M,2), # [N,2] -> [N,1,2] -> [N,M,2]
box2[:,:2].unsqueeze(0).expand(N,M,2), # [M,2] -> [1,M,2] -> [N,M,2]
)
rb = torch.min(
box1[:,2:].unsqueeze(1).expand(N,M,2), # [N,2] -> [N,1,2] -> [N,M,2]
box2[:,2:].unsqueeze(0).expand(N,M,2), # [M,2] -> [1,M,2] -> [N,M,2]
)
wh = rb - lt # [N,M,2]
# wh(wh<0)= 0 # clip at 0
wh= (wh < 0).float()
inter = wh[:,:,0] * wh[:,:,1] # [N,M]
area1 = (box1[:,2]-box1[:,0]) * (box1[:,3]-box1[:,1]) # [N,]
area2 = (box2[:,2]-box2[:,0]) * (box2[:,3]-box2[:,1]) # [M,]
area1 = area1.unsqueeze(1).expand_as(inter) # [N,] -> [N,1] -> [N,M]
area2 = area2.unsqueeze(0).expand_as(inter) # [M,] -> [1,M] -> [N,M]
iou = inter / (area1 + area2 - inter)
return iou
def forward(self,pred_tensor,target_tensor):
'''
pred_tensor: (tensor) size(batchsize,S,S,Bx5+20=30) [x,y,w,h,c]
target_tensor: (tensor) size(batchsize,S,S,30)
Mr.Li个人见解:
本来有,预测无--》计算response loss响应损失
本来有,预测有--》计算not response loss 未响应损失
本来无,预测无--》无损失(不计算)
本来无,预测有--》计算不包含obj损失 只计算第4,9位的有无物体概率的loss
'''
# N为batchsize
N = pred_tensor.size()[0]
# 坐标mask 4:是物体或者背景的confidence >0 拿到有物体的记录
coo_mask = target_tensor[:,:,:,4] > 0
# 没有物体mask ==0 拿到无物体的记录
noo_mask = target_tensor[:,:,:,4] == 0
# unsqueeze(-1) 扩展最后一维,用0填充,使得形状与target_tensor一样
# coo_mask、noo_mask形状扩充到[32,7,7,30]
# coo_mask 大部分为0 记录为1代表真实有物体的网格
# noo_mask 大部分为1 记录为1代表真实无物体的网格
coo_mask = coo_mask.unsqueeze(-1).expand_as(target_tensor)
noo_mask = noo_mask.unsqueeze(-1).expand_as(target_tensor)
# coo_pred 取出预测结果中有物体的网格,并改变形状为(xxx,30) xxx代表一个batch的图片上的存在物体的网格总数 30代表2*5+20 例如:coo_pred[72,30]
coo_pred = pred_tensor[coo_mask].view(-1,30)
# 一个网格预测的两个box 30的前10即为2个x,y,w,h,c,并调整为(xxx,5) xxx为所有真实存在物体的预测框,而非所有真实存在物体的网格 例如:box_pred[144,5]
# contiguous将不连续的数组调整为连续的数组
box_pred = coo_pred[:,:10].contiguous().view(-1,5) #box[x1,y1,w1,h1,c1]
# #[x2,y2,w2,h2,c2]
# 每个网格预测的类别 后20
class_pred = coo_pred[:,10:]
# 对真实标签做同样操作
coo_target = target_tensor[coo_mask].view(-1,30)
box_target = coo_target[:,:10].contiguous().view(-1,5)
class_target = coo_target[:,10:]
# 计算不包含obj损失 即本来无,预测有
# 在预测结果中拿到真实无物体的网格,并改变形状为(xxx,30) xxx代表一个batch的图片上的不存在物体的网格总数 30代表2*5+20 例如:[1496,30]
noo_pred = pred_tensor[noo_mask].view(-1,30)
noo_target = target_tensor[noo_mask].view(-1,30) # 例如:[1496,30]
# ByteTensor:8-bit integer (unsigned)
noo_pred_mask = torch.cuda.ByteTensor(noo_pred.size()) # 例如:[1496,30]
noo_pred_mask.zero_() #初始化全为0
# 将第4、9 即有物体的confidence置为1
noo_pred_mask[:,4]=1;noo_pred_mask[:,9]=1
# 拿到第4列和第9列里面的值(即拿到真实无物体的网格中,网络预测这些网格有物体的概率值) 一行有两个值(第4和第9位) 例如noo_pred_c:2992 noo_target_c:2992
# noo pred只需要计算类别c的损失
noo_pred_c = noo_pred[noo_pred_mask]
# 拿到第4列和第9列里面的值 真值为0,真实无物体(即拿到真实无物体的网格中,这些网格有物体的概率值,为0)
noo_target_c = noo_target[noo_pred_mask]
# 均方误差 如果 size_average = True,返回 loss.mean()。 例如noo_pred_c:2992 noo_target_c:2992
# nooobj_loss 一个标量
nooobj_loss = F.mse_loss(noo_pred_c,noo_target_c,size_average=False)
#计算包含obj损失 即本来有,预测有 和 本来有,预测无
coo_response_mask = torch.cuda.ByteTensor(box_target.size())
coo_response_mask.zero_()
coo_not_response_mask = torch.cuda.ByteTensor(box_target.size())
coo_not_response_mask.zero_()
# 选择最好的IOU
for i in range(0,box_target.size()[0],2):
box1 = box_pred[i:i+2]
box1_xyxy = Variable(torch.FloatTensor(box1.size()))
box1_xyxy[:,:2] = box1[:,:2] -0.5*box1[:,2:4]
box1_xyxy[:,2:4] = box1[:,:2] +0.5*box1[:,2:4]
box2 = box_target[i].view(-1,5)
box2_xyxy = Variable(torch.FloatTensor(box2.size()))
box2_xyxy[:,:2] = box2[:,:2] -0.5*box2[:,2:4]
box2_xyxy[:,2:4] = box2[:,:2] +0.5*box2[:,2:4]
iou = self.compute_iou(box1_xyxy[:,:4],box2_xyxy[:,:4]) #[2,1]
max_iou,max_index = iou.max(0)
max_index = max_index.data.cuda()
coo_response_mask[i+max_index]=1
coo_not_response_mask[i+1-max_index]=1
# 1.response loss响应损失,即本来有,预测有 有相应 坐标预测的loss (x,y,w开方,h开方)参考论文loss公式
# box_pred [144,5] coo_response_mask[144,5] box_pred_response:[72,5]
# 选择IOU最好的box来进行调整 负责检测出某物体
box_pred_response = box_pred[coo_response_mask].view(-1,5)
box_target_response = box_target[coo_response_mask].view(-1,5)
# box_pred_response:[72,5] 计算预测 有物体的概率误差,返回一个数
contain_loss = F.mse_loss(box_pred_response[:,4],box_target_response[:,4],size_average=False)
# 计算(x,y,w开方,h开方)参考论文loss公式
loc_loss = F.mse_loss(box_pred_response[:,:2],box_target_response[:,:2],size_average=False) + F.mse_loss(torch.sqrt(box_pred_response[:,2:4]),torch.sqrt(box_target_response[:,2:4]),size_average=False)
# 2.not response loss 未响应损失,即本来有,预测无 未响应
# box_pred_not_response = box_pred[coo_not_response_mask].view(-1,5)
# box_target_not_response = box_target[coo_not_response_mask].view(-1,5)
# box_target_not_response[:,4]= 0
# box_pred_response:[72,5]
# 计算c 有物体的概率的loss
not_contain_loss = F.mse_loss(box_pred_response[:,4],box_target_response[:,4],size_average=False)
# 3.class loss 计算传入的真实有物体的网格 分类的类别损失
class_loss = F.mse_loss(class_pred,class_target,size_average=False)
# 除以N 即平均一张图的总损失
return (self.l_coord*loc_loss + contain_loss + not_contain_loss + self.l_noobj*nooobj_loss + class_loss)/N
一文看懂YOLO v1:https://blog.csdn.net/litt1e/article/details/88814417
一文看懂YOLO v2:https://blog.csdn.net/litt1e/article/details/88852745
一文看懂YOLO v3:https://blog.csdn.net/litt1e/article/details/88907542