编程的两种方式执行Spark SQL查询(方式一)
现在我们来实现在自定义程序中编写Spark SQL查询程序。
实现查询的方式有两种:
方式一:通过反射推断schema。
方式二:通过structtype直接指定schema。
我们先用方式一来实现自定义查询。
首先创建一个team.txt文件,内容有5列,分别是id,球队名称,综合值,进攻值,防守值。
部分数据如下:
1,火箭,94,95,93
2,马刺,95,96,94
3,灰熊,92,94,90
4,勇士,99,99,98
5,湖人,72,75,69
6,猛龙,86,85,87
特别说明:team.txt文件一定要用UTF-8的格式保存,否则计算结果中文字符会出现乱码。
开启虚拟机集群,我这里是三台机器:hadoop001、hadoop002、hadoop003。
使用RZ命令将team.txt文件上传到虚拟机,通过hdfs命令操作将文件保存到hdfs存储介质中。
hdfs dfs -put /home/hadoop/files/player/team1.txt input/team1.txt
接下来,在maven项目的pom.xml中添加Spark SQL的依赖。
org.apache.spark
spark-sql_2.10
1.6.1
package cn.allengao.sparksql
import org.apache.spark.sql.SQLContext
import org.apache.spark.{SparkConf, SparkContext}
/**
* class_name:
* package:
* describe: SparkSql通过反射推断schema
* creat_user: Allen Gao
* creat_date: 2018/2/5
* creat_time: 9:53
**/
object InferringSchema {
def main(args: Array[String]): Unit = {
//1、模板代码
val conf = new SparkConf().setAppName("SQL-typeOne").setMaster("local[*]")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
//2、获取数据
val linesRDD = sc.textFile(args(0)).map(_.split(","))
//3、将RDD和case class进行关联
val teamRDD = linesRDD.map(x => PlayTeam(x(0).toInt, x(1), x(2).toInt, x(3).toInt,x(4).toInt))
//4、创建DataFrame
import sqlContext.implicits._
val teamDF = teamRDD.toDF
//5、注册表
teamDF.registerTempTable("t_team")
//6、查询
val df = sqlContext.sql("select * from t_team order by colligate desc limit 3")
//7、输出
df.write.json(args(1))
sc.stop()
}
}
//id 队名 综合 进攻 防守
case class PlayTeam(id: Int, name: String, colligate: Int, attack: Int,defense:Int)设置运行参数:hdfs://hadoop001:9000/user/hadoop/input/team.txt hdfs://hadoop001:9000/output/team
运行程序代码。
通过WEB页面打开hadoop目录可以看到执行成功的结果文件:
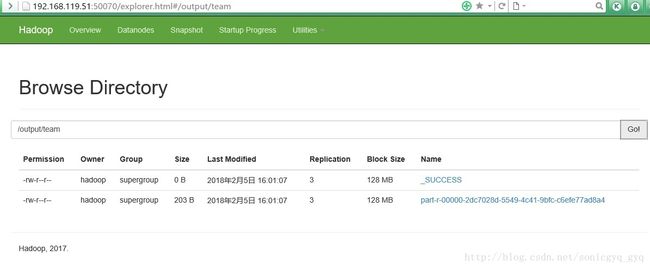
通过hdfs命令查看结果文件:
hdfs dfs -cat hdfs://hadoop001:9000/output/team1/part-r-00000-2dc7028d-5549-4c41-9bfc-c6efe77ad8a4
可以看到如下结果信息:
{"id":4,"name":"勇士","colligate":99,"attack":99,"defense":98}
{"id":2,"name":"马刺","colligate":95,"attack":96,"defense":94}
{"id":1,"name":"火箭","colligate":94,"attack":95,"defense":93}