Fluentd 配置
[GitHub] https://github.com/fluent/fluentd
[Doc] http://docs.fluentd.org/articles/config-file
[Example] https://github.com/fluent/fluentd/tree/master/example
默认配置文件:/etc/td-agent/td-agent.conf
Fluentd directives
source:确定输入源match: 确定输出目的地filter:确定 event 处理流system:设置系统范围的配置label:将内部路由的输出和过滤器分组@include:包括其它文件
source 指令
通过使用 source 指令,来选择和配置所需的输入插件来启用 Fluentd 输入源。Fluentd 的标准输入插件包含 http(监听 9880) 和 forward 模式(监听 24224),分别用来接收 HTTP 请求和 TCP 请求。
http:使 fluentd 转变为一个 httpd 端点,以接受进入的 http 报文。forward:使 fluentd 转变为一个 TCP 端点,以接受 TCP 报文。
| 1 2 3 4 5 6 7 8 9 10 11 12 |
### Receive events from 24224/tcp ### This is used by log forwarding and the fluent-cat command @type forward port 24224 ### http://this.host:9880/myapp.access?json={“event”:”data”} @type http port 9880 |
每个 source 指令必须包括 “type” 参数,指定使用那种插件。
Routing(路由):source 把事件提交到 fluentd 的路由引擎中。一个事件由三个实体组成:tag、time 和 record。
tag:是一个通过 “.” 来分离的字符串(e.g. myapp.access),用作 Fluentd 内部路由引擎的方向。time:时间字段由输入插件指定,并且必须为 Unix 时间格式。record:一个 JSON 对象。
在上面的例子中,http 输入插件提交了以下的事件
| 1 2 3 4 |
### generated by http://this.host:9880/myapp.access?json={“event”:”data”} tag: myapp.access time: (current time) record: {“event”:”data”} |
match 指令
match 指令查找匹配 “tags” 的事件,并处理它们。match 命令的最常见用法是将事件输出到其他系统(因此,与 match 命令对应的插件称为 “输出插件”)。 Fluentd 的标准输出插件包括 file 和 forward。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
### Receive events from 24224/tcp ### This is used by log forwarding and the fluent-cat command @type forward port 24224 ### http://this.host:9880/myapp.access?json={“event”:”data”} @type http port 9880 ### Match events tagged with “myapp.access” and ### store them to /var/log/fluent/access.%Y-%m-%d ### Of course, you can control how you partition your data ### with the time_slice_format option. @type file path /var/log/fluent/access |
每个 match 指令必须包括一个匹配模式和 type 参数。只有与模式匹配的 “tags” 事件才会发送到输出目标(在上面的示例中,只有标记 “myapp.access” 的事件匹配)。type 参数指定使用哪种输出插件。
match 模式
*:匹配单个 tag 部分- 例:a.*,匹配 a.b,但不匹配 a 或者 a.b.c
**:匹配 0 或 多个 tag 部分- 例:a.**,匹配 a、a.b 和 a.b.c
{X,Y,Z}:匹配 X、Y 或 Z,其中 X、Y 和 Z 是匹配模式。可以和*和**模式组合使用- 例 1:{a, b},匹配 a 和 b,但不匹配 c
- 例 2:a.{b,c}. 和 a.{b,c.*}
- 当多个模式列在一个
Fluentd 尝试按照它们在配置文件中出现的顺序,从上到下来进行 "tags" 匹配 。 所以,如果是下面的配置,那么 myapp.access 将永远不会匹配。
| 1 2 3 4 5 6 7 8 9 |
### ** matches all tags. Bad @type blackhole_plugin @type file path /var/log/fluent/access |
filter 指令
Event processing pipeling(事件处理流)
“filter” 指令具有与 “match” 相同的语法,但是 filter 可以串联成 pipeline,对数据进行串行处理,最终再交给 match 输出。 使用 fliters,事件流如下:
| 1 |
Input -> filter 1 -> … -> filter N -> Output(Match tag) |
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
### http://this.host:9880/myapp.access?json={“event”:”data”} @type http port 9880 @type record_transformer host_param “#{Socket.gethostname}” @type file path /var/log/fluent/access |
这个例子里,filter 获取数据后,调用原生的 @type record_transformer 插件,在事件的 record 里插入了新的字段 host_param,然后再交给 match 输出。
filter 匹配顺序与 match 相同,我们应该在
system 指令
fluentd 的相关设置,可以在启动时设置,也可以在配置文件里设置,包含:
- log_level
- suppress_repeated_stacktrace
- emit_error_log_interval
- suppress_config_dump
- without_source
例 1:fluentd 启动配置
| 1 2 3 4 5 6 7 |
# equal to -qq option log_level error # equal to –without-source option without_source # … |
例 2:fluentd 进程名
| 1 2 3 |
process_name fluentd1 |
| 1 2 3 |
% ps aux | grep fluentd1 foo 45673 0.4 0.2 2523252 38620 s001 S+ 7:04AM 0:00.44 worker:fluentd1 foo 45647 0.0 0.1 2481260 23700 s001 S+ 7:04AM 0:00.40 supervisor:fluentd1 |
label 指令
label 用于将任务进行分组,方便复杂任务的管理。
@label @
你可以在 source 里指定 @label @,这个 source 所触发的事件就会被发送给指定的 label 所包含的任务,而不会被后续的其他任务获取到。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
@type forward ### 这个任务指定了 label 为 @SYSTEM ### 会被发送给 ### 而不会被发送给下面紧跟的 filter 和 match @type tail @label @SYSTEM @type record_transformer # … @type elasticsearch # … ### 将会接收到上面 @type tail 的 source event @type grep # … @type s3 # … |
@ERROR label
用来接收插件通过调用 emit_error_event API 抛出的异常,使用方法和 label 一样,通过设定 就可以接收到相关的异常。
include 指令
导入其它独立的配置文件中的指令,这些文件可以使用:
- 相对路径
- 绝对路由
- HTTP URL
Fluentd Plugins
[Plugins] http://www.fluentd.org/plugins
Fluentd 有 6 种类型的插件:
Input:输入Output:输出Buffer:缓冲区Filter:过滤器Parset:解析器Formatter:格式化器
Input Plugins
[Doc] http://docs.fluentd.org/articles/input-plugin-overview
input 插件扩展 Fluentd,以从外部源检索和拉取事件日志。 input 插件通常创建线程套接字和侦听套接字。 它还可以被写入以周期性地从数据源拉取数据。
- in_udp
- in_tcp
- in_forward
- in_secure_forward
- in_http
- in_unix
- in_tail
- in_exec
- in_syslog
- in_scribe
- in_multiprocess
- in_dummy
in_udp
[Doc] http://docs.fluentd.org/articles/in_tcp
Parameters:
- type(required)
- tag( required)
- port
- bind
- delimiter
- source_host_key
- format (required): 参见 “2.5 Parser Plugins”
- regexp
- apache2
- apoache_error
- nginx
- syslog
- tsv or csv
- ltsv
- json
- none
- mulitline
- keep_time_key
- log_level
- fatal
- error
- warn
- info
- debug
- trace
in_tcp
[Doc] http://docs.fluentd.org/articles/in_tcp
Parameters: 同 in_udp
in_forward
[Doc] http://docs.fluentd.org/articles/in_forward
- 侦听 TCP 套接字以接收事件流,它还侦听 UDP 套接字以接收心跳消息
- in_forward 不提供解析机制,不像 in_tail 或 in_tcp,因为 in_forward 主要是为了高效的日志传输。 如果要解析传入事件,请在 pipeline 中使用 parser filter
Parameters:
- type(required):forward
- port
- bind
- linger_timeout
- chunk_zine_limit
- chunk_size_warn_limit
- skip_invalid_event
- source_hostname_key
- log_level
in_secure_forward
[Doc] http://docs.fluentd.org/articles/in_secure_forward
in_http
[Doc] http://docs.fluentd.org/articles/in_http
Parameters:
- type(required):forward
- port
- bind
- body_size_limit
- keepalive_timeout
- add_http_headers
- add_remote_addr
- cors_allow_origins
- format: 参见 “2.5 Parser Plugins”
- default:json、msgpack
- regexp
- json
- ltsv
- tsv or csv
- none
- log_level
in_unix
[Doc] http://docs.fluentd.org/articles/in_unix
in_tail
[Doc] http://docs.fluentd.org/articles/in_tail
- When Fluentd is first configured with in_tail, it will start reading from the tail of that log, not the beginning.
- Once the log is rotated, Fluentd starts reading the new file from the beginning. It keeps track of the current inode number.
- If td-agent restarts, it starts reading from the last position td-agent read before the restart. This position is recorded in the position file specified by the pos_file parameter.
| 1 2 3 4 5 6 7 8 9 |
@type tail path /var/log/httpd-access.log exclude_path ["/var/log/*.gz", "/var/log/*.zip"] pos_file /var/log/td-agent/httpd-access.log.pos tag apache.access format apache2 keep_time_key false |
Parameters:
- type (required)
- tag (required)
- path (required)
- exclude_path
- refresh_interval
- read_from_head
- read_lines_limit
- multiline_flush_interval
- pos_file (highly recommended)
- format (required): 参见 “2.5 Parser Plugins”
- regexp
- apache2
- apache_error
- nginx
- syslog
- tsv or csv
- ltsv
- json
- none
- multiline
- time_format
- rotate_wait
- enable_watch_timer
in_exec
[Doc] http://docs.fluentd.org/articles/in_exec
in_exec Input 插件执行外部程序以接收或拉取事件日志。 然后它将从程序的 stdout 读取 TSV(制表符分隔值),JSON 或 MessagePack。
Example:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
@type exec command cmd arg arg keys k1,k2,k3 tag_key k1 time_key k2 time_format %Y-%m-%d %H:%M:%S run_interval 10s @type exec format json tag hackernews command ruby /path/to/hn.rb run_interval 5m # don’t hit HN too frequently! @type stdout |
Parameters:
- type(required)
- command(required)
- format
- tsv(default)
- josn
- msgpack
- tag (required if tag_key is not specified)
- tag_key
- time_key
- time_format
- run_interval
- log_level
in_syslog
[Doc] http://docs.fluentd.org/articles/in_syslog
Parameters:
- type(required)
- port
- bind
- protocol_type
- tag(required)
- format: 参见 “2.5 Parser Plugins”
- regexp
- apache2
- apache_error
- nginx
- syslog
- tsv or osv
- ltsv
- json
- none
- multiline
Othter
- in_scribe
- in_multiprocess
- in_dummy
Ouput Plugins
[Doc] http://docs.fluentd.org/articles/output-plugin-overview
- out_file
- out_forward
- out_secure_forward
- out_exec
- out_exec_filter
- out_copy
- out_geoip
- out_roundrobin
- out_stdout
- out_null
- out_s3
- out_mongo
- out_mongo_replset
- out_relabel
- out_rewrite_tag_filter
- out_webhdfs
Plugins Type

输出插件的缓冲区行为(如果有的话)由单独的缓冲区插件定义。 可以为每个输出插件选择不同的缓冲区插件。 一些输出插件是完全自定义的,不使用缓冲区。
Non-Buffered- 非缓冲输出插件不缓冲数据并立即写出结果。
- includes:
- out_copy
- out_stdout
- out_null
- out_stdout
Buffered- 时间切片输出插件事实上是一种缓冲插件,但块是按时间键入的。
- includes:
- out_exec_filter
- out_forward
- out_mongo or out_mongo_replset
Time Sliced- 时间切片输出插件事实上是一种缓冲插件,但块是按时间键入的。
- includes:
- out_exec
- out_file
- out_s3
- out_webhdfs
out_file
[Doc] http://docs.fluentd.org/articles/out_file
out_file TimeSliced 输出插件将事件写入文件。 默认情况下,它每天创建文件(大约 00:10)。 这意味着,当您首次使用插件导入记录时,不会立即创建文件。 当满足 time_slice_format 条件时,将创建该文件。 要更改输出频率,请修改 time_slice_format 值。
Example:
| 1 2 3 4 5 6 7 8 9 |
@type file path /var/log/fluent/myapp time_slice_format %Y%m%d time_slice_wait 10m time_format %Y%m%dT%H%M%S%z ### 20170104T202425+0800 compress gzip utc |
Parameters:
type (required)path (required)append:默认值 false,即刷新日志到不同的文件;若为 true 则输出到同一文件,直到触发 time_slice_formatformat:默认值 out_file,其它格式有:json、hash、ltsv、single_value、csv、stdout,参见 “2.6 Formatter Plugins”time_formatutccompress:gzipsymlink_path:当 buffer_type 是文件时,创建到临时缓冲文件的符号链接。 默认情况下不创建符号链接。This is useful for tailing file content to check logs.
Time Sliced Output Parameters:
- time_slice_format:
- The default format is %Y%m%d%H, which creates one file per hour.
- time_slice_wait
- buffer_type
- buffer_queue_limit, buffer_chunk_limit
- flush_interval
- flush_at_shutdown
- retry_wait, max_retry_wait
- retry_limit, disable_retry_limit
- num_threads
- slow_flush_log_threshold
out_forward
[Doc] http://docs.fluentd.org/articles/out_forward
out_forward 缓冲输出插件将事件转发到其他 fluentd节点。 此插件支持负载平衡和自动故障切换(又名主动 – 主动备份)。 对于复制,请使用 out_copy 插件。
out_forward 插件使用 “φaccrual failure detector” 算法检测服务器故障。 您可以自定义算法的参数。 当服务器故障恢复时,插件使服务器在几秒钟后自动可用。
out_forward 插件支持最多一次和至少一次消息投递语义。 默认值为最多一次。参见 “4. Fluentd 高可用”。
Example:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
@type forward send_timeout 60s recover_wait 10s heartbeat_interval 1s phi_threshold 16 hard_timeout 60s name myserver1 host 192.168.1.3 port 24224 weight 60 name myserver2 host 192.168.1.4 port 24224 weight 60 … @type file path /var/log/fluent/forward-failed |
Parameters:
- type (required)
- require_ack_response
- ack_response_timeout
- send_timeout
- recover_wait
- heartbeat_type
- heartbeat_interval
- phi_failure_detector
- phi_threshold
- hard_timeout
standby- expire_dns_cache
- dns_round_robin
Buffered Output Parameters:
- buffer_type
- buffer_queue_limit, buffer_chunk_limit
- flush_interval
- flush_at_shutdown
- retry_wait, max_retry_wait
- retry_limit, disable_retry_limit
- num_threads
- slow_flush_log_threshold
out_copy
[Doc] http://docs.fluentd.org/articles/out_copy
copy 输出插件将事件复制到多个输出。
Parameters:
- type (required)
- deep_copy
Example:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
@type copy @type file path /var/log/fluent/myapp time_slice_format %Y%m%d time_slice_wait 10m time_format %Y%m%dT%H%M%S%z compress gzip utc @type mongo host fluentd port 27017 database fluentd collection test |
out_stdout
[Doc] http://docs.fluentd.org/articles/out_stdout
stdout 输出插件将事件打印到 stdout(或日志,如果以守护进程模式启动)。 对于调试目的,这个输出插件是很有用的。
Parameters
- type (required)
- output_type:json or hash (Ruby’s hash)
out_exec
[Doc] http://docs.fluentd.org/articles/out_exec
out_exec TimeSliced 输出插件将事件传递到外部程序。 程序接收包含传入事件作为其最后一个参数的文件的路径。 默认情况下,文件格式为制表符分隔值(TSV)。
Parameters:
- type (required)
- command (required)
- format
- tsv(default)
- json
- msgpack
- tag_key
- time_key
- time_format
Time Sliced Output Parameters:
- time_slice_format
- time_slice_wait
- buffer_type
- buffer_queue_limit, buffer_chunk_limit
- flush_interval
- flush_at_shutdown
- retry_wait, max_retry_wait
- retry_limit, disable_retry_limit
- num_threads
- slow_flush_log_threshold
Buffer Plugins
[Doc] http://docs.fluentd.org/articles/buffer-plugin-overview
- buf_memory
- buf_file
缓冲插件由缓冲输出插件使用,如 out_file,out_forward 等。用户可以选择最适合其性能和可靠性需求的缓冲插件。
Buffer Structure
The buffer structure is a queue of chunks like the following:
| 1 2 3 4 5 6 7 8 9 10 11 12 |
queue +———+ | | | chunk <– write events to the top chunk | | | chunk | | | | chunk | | | | chunk –> write out the bottom chunk | | +———+ |
When the top chunk exceeds the specified size or time limit (buffer_chunk_limit and flush_interval, respectively), a new empty chunk is pushed to the top of the queue. The bottom chunk is written out immediately when new chunk is pushed.
If the bottom chunk fails to be written out, it will remain in the queue and Fluentd will retry after waiting several seconds (retry_wait). If the retry limit has not been disabled (disable_retry_limit is false) and the retry count exceeds the specified limit (retry_limit), the chunk is trashed. The retry wait time doubles each time (1.0sec, 2.0sec, 4.0sec, …) until max_retry_wait is reached. If the queue length exceeds the specified limit (buffer_queue_limit), new events are rejected.

Filter Plugins
[Doc] http://docs.fluentd.org/articles/filter-plugin-overview
- filter_record_transformer
- filter_grep
- filter_parser
- filter_stdout
过滤插件使 Fluentd 可以修改事件流。 示例用例:
- 通过删除一个或多个字段的值来过滤事件
- 通过添加新字段丰富事件
- 删除或屏蔽某些字段,以确保隐私权和合规性。
Example:
| 1 2 3 4 5 6 7 8 9 10 11 |
@type grep regexp1 message cool @type record_transformer hostname “#{Socket.gethostname}” |
Only the events whose “message” field contain “cool” get the new field “hostname” with the machine’s hostname as its value.
filter_record_transformer
[Doc] http://docs.fluentd.org/articles/filter_record_transformer
The filter_record_transformer filter plugin mutates/transforms incoming event streams in a versatile manner. If there is a need to add/delete/modify events, this plugin is the first filter to try.
Parameters
- enable_ruby (optional)
- auto_typecast (optional)
- renew_record (optional)
- renew_time_key (optional, string type)
- keep_keys (optional, string type)
- remove_keys (optional, string type)
Example:
| 1 2 3 4 5 6 7 |
@type record_transformer hostname “#{Socket.gethostname}” tag ${tag} |
The above filter adds the new field “hostname” with the server’s hostname as its value (It is taking advantage of Ruby’s string interpolation) and the new field “tag” with tag value. So, an input like
| 1 |
{“message”:”hello world!”} |
is transformed into
| 1 |
{“message”:”hello world!”, “hostname”:”db001.internal.example.com”, “tag”:”foo.bar”} |
Parameters inside directives are considered to be new key-value pairs:
| 1 2 3 |
NEW_FIELD NEW_VALUE |
对于NEW_FIELD和NEW_VALUE,特殊语法${}允许用户动态生成新字段。 在花括号中,以下变量可用:
- The incoming event’s existing values can be referred
by their field names. So, if the record is {“total”:100, “count”:10}, then total=10 and count=10. tag_parts[N]:refers to the Nth part of the tag. It works like the usual zero-based array accessor.tag_prefix[N]:refers to the first N parts of the tag. It works like the usual zero-based array accessor.tag_suffix[N]:refers to the last N parts of the tag. It works like the usual zero-based array accessor.tag:refers to the whole tag.time:refers to stringanized event time.
filter_grep
[Doc] http://docs.fluentd.org/articles/filter_grep
filter_grep 过滤器插件通过指定字段的值 “greps” 事件。
Parameters
- regexpN (optional)
- excludeN (optional)
Example:
| 1 2 3 4 5 6 |
@type grep regexp1 message cool regexp2 hostname ^web\d+\.example\.com$ exclude1 message uncool |
regexpN (optional)
The “N” at the end should be replaced with an integer between 1 and 20 (ex: “regexp1”). regexpN takes two whitespace-delimited arguments.
- The first argument is the field name to which the regular expression is applied.
- The second argument is the regular expression.
The above example matches any event that satisfies the following conditions:
- The value of the “message” field contains “cool”
- The value of the “hostname” field matches web.example.com.
- The value of the “message” field does NOT contain “uncool”.
因此,以下事件将被保留:
| 1 2 |
{“message”:”It’s cool outside today”, “hostname”:”web001.example.com”} {“message”:”That’s not cool”, “hostname”:”web1337.example.com”} |
而以下事件被过滤掉:
| 1 2 3 |
{“message”:”I am cool but you are uncool”, “hostname”:”db001.example.com”} {“hostname”:”web001.example.com”} {“message”:”It’s cool outside today”} |
filter_parser
[Doc] http://docs.fluentd.org/articles/filter_parser
filter_parser 过滤器插件在事件记录中 “解析” 字符串字段,并使用解析的结果更改其事件记录。
Parameters
- reserve_data
- suppress_parse_error_log
- replace_invalid_sequence
- inject_key_prefix
- hash_value_field
- time_parse
Example:
| 1 2 3 4 5 6 |
@type parser format /^(?(? ]*)\] “(?[^ ]*) (? |
filter_parser 使用内置的解析器插件和您自己的自定义解析器插件,因此您可以重新使用像 apache,json 等预定义的格式。有关详细信息,参见 “2.5 Parser Plugins”。
filter_stdout
[Doc] http://docs.fluentd.org/articles/filter_stdout
filter_stdout 过滤器插件将事件打印到 stdout(或日志,如果以守护进程模式启动)。 对于调试目的,这个过滤器插件是很有用的。
Parameters:
- type(required)
- format:stdout
- output_type:可以指定任何格式化插件,默认为 json。
- out_file
Parser Plugins
[Doc] http://docs.fluentd.org/articles/parser-plugin-overview
有时,输入插件(例如:in_tail,in_syslog,in_tcp 和 in_udp)的格式参数无法解析用户的自定义数据格式(例如,不能使用正则表达式解析的上下文相关语法)。 为了解决这种情况,对于 v0.10.46 及以上版本,Fluentd 有一个可插拔的系统,使用户能够创建自己的解析器格式。
| 1 2 3 4 5 |
@type tail path /path/to/input/file format my_custom_parser ### 自定义解析器格式 |
List of Core Input Plugins with Parser support
with format parameter.
- in_tail
- in_tcp
- in_udp
- in_syslog
- in_http
List of Built-in Parsers(内置解析列表)
regexp
The regexp for the format parameter can be specified. If the parameter value starts and ends with “/”, it is considered to be a regexp. The regexp must have at least one named capture (? If the regexp has a capture named ‘time’, it is used as the time of the event. You can specify the time format using the time_format parameter.
apache2
Reads apache’s log file for the following fields: host, user, time, method, path, code, size, referer and agent. This template is analogous to the following configuration:
| 1 2 |
format /^(? (? ]*)\] “(?[^ ]*) (? |
apache_error
Reads apache’s error log file for the following fields: time, level, pid, client and (error) message. This template is analogous to the following configuration:
| 1 |
format /^ [^ ]* (? ]*)\](? pid (? client (? |
nginx
Reads Nginx’s log file for the following fields: remote, user, time, method, path, code, size, referer and agent. This template is analogous to the following configuration:
| 1 2 |
format /^(? (? ]*)\] “(?[^ ]*) (? |
syslog
Reads syslog’s output file (e.g. /var/log/syslog) for the following fields: time, host, ident, and message. This template is analogous to the following configuration:
| 1 2 |
format /^(? |
tsv or csv
If you use tsv or csv format, please also specify the keys parameter.
| 1 2 3 |
format tsv keys key1,key2,key3 time_key key2 |
If you specify the time_key parameter, it will be used to identify the timestamp of the record. The timestamp when Fluentd reads the record is used by default.
| 1 2 3 |
format csv keys key1,key2,key3 time_key key3 |
ltsv
ltsv (Labeled Tab-Separated Value) is a tab-delimited key-value pair format. You can learn more about it on its webpage.
| 1 2 3 |
format ltsv delimiter = # Optional. ‘:’ is used by default time_key time_field_name |
If you specify the time_key parameter, it will be used to identify the timestamp of the record. The timestamp when Fluentd reads the record is used by default.
json
One JSON map, per line. This is the most straight forward format :).
| 1 |
from json |
One JSON map, per line. This is the most straight forward format :).
| 1 2 |
format json time_key key3 |
none
You can use the none format to defer parsing/structuring the data. This will parse the line as-is with the key name “message”. For example, if you had a line
| 1 |
hello world. I am a line of log! |
It will be parsed as
| 1 |
{“message”:”hello world. I am a line of log!”} |
The key field is “message” by default, but you can specify a different value using the message_key parameter as shown below:
| 1 2 |
format none message_key my_message |
multiline
Read multiline log with formatN and format_firstline parameters. format_firstline is for detecting start line of multiline log. formatN, N’s range is 1..20, is the list of Regexp format for multiline log. Here is Rails log Example:
| 1 2 3 4 5 6 7 |
format multiline format_firstline /^Started/ format1 /Started (? format2 /Processing by (? format3 /( Parameters: (? format4 / Rendered (?[^ ]+) within (? format5 /Completed (? |
If you have a multiline log
| 1 2 3 4 5 |
Started GET “/users/123/” for 127.0.0.1 at 2013-06-14 12:00:11 +0900 Processing by UsersController#show as HTML Parameters: {“user_id”=>”123″} Rendered users/show.html.erb within layouts/application (0.3ms) Completed 200 OK in 4ms (Views: 3.2ms | ActiveRecord: 0.0ms) |
It will be parsed as
| 1 |
{“method”:”GET”,”path”:”/users/123/”,”host”:”127.0.0.1″,”controller”:”UsersController”,”controller_method”:”show”,”format”:”HTML”,”parameters”:”{ \”user_id\” = >\”123\”}”, …} |
One more example, you can parse Java like stacktrace logs with multiline. Here is a configuration example.
| 1 2 3 |
format multiline format_firstline /\d{4}-\d{1,2}-\d{1,2}/ format1 /^(? |
If you have a following log:
| 1 2 3 4 5 |
2013-3-03 14:27:33 [main] INFO Main – Start 2013-3-03 14:27:33 [main] ERROR Main – Exception javax.management.RuntimeErrorException: null at Main.main(Main.java:16) ~[bin/:na] 2013-3-03 14:27:33 [main] INFO Main – End |
It will be parsed as:
| 1 2 3 |
2013-03-03 14:27:33 +0900 zimbra.mailbox: {“thread”:”main”,”level”:”INFO”,”message”:” Main – Start”} 2013-03-03 14:27:33 +0900 zimbra.mailbox: {“thread”:”main”,”level”:”ERROR”,”message”:” Main – Exception\njavax.management.RuntimeErrorException: null\n at Main.main(Main.java:16) ~[bin/:na]“} 2013-03-03 14:27:33 +0900 zimbra.mailbox: {“thread”:”main”,”level”:”INFO”,”message”:” Main – En |
Formatter Plugins
[Doc] http://docs.fluentd.org/articles/formatter-plugin-overview
有时,输出插件的输出格式不能满足需要。 Fluentd 有一个称为文本格式器的可插拔系统,允许用户扩展和重新使用自定义输出格式。
对于支持文本格式器的输出插件,format 参数可用于更改输出格式。
For example, by default, out_file plugin outputs data as
| 1 |
2014-08-25 00:00:00 +0000 |
However, if you set format json like this
| 1 2 3 4 5 |
@type file path /path/to/file format json ### 格式化日志输出 |
The output changes to
| 1 |
{“time”: “2014-08-25 00:00:00 +0000″, “tag”:”foo.bar”, “k1:”v1″, “k2″:”v2″} |
List of Output Plugins with Text Formatter Support
- out_file
- out_s3
List of Built-in Formatters
stdout
此格式旨在由 stdout 插件使用。
Output time, tag and formatted record as follows:
| 1 |
time tag: formatted_record\n |
Example:
| 1 |
2015-05-02 12:12:17 +0900 tag: {“field1″:”value1″,”field2″:”value2″}\n |
stdout format has a following option to customize the format of the record part.
| 1 2 |
output_type format # Optional, defaults to “json”. The format of `formatted_record`. Any formatter plugins can be specified. |
For this format, the following common parameters are also supported.
include_time_key(Boolean, Optional, defaults to false)- If true, the time field (as specified by the time_key parameter) is kept in the record.
time_key(String, xOptional, defaults to “time”)- The field name for the time key.
time_format(String. Optional)- By default, the output format is iso8601 (e.g. “2008-02-01T21:41:49”). One can specify their own format with this parameter.
include_tag_key(Boolean. Optional, defaults to false)- If true, the tag field (as specified by the tag_key parameter) is kept in the record.
tag_key(String, Optional, defaults to “tag”)- The field name for the tag key.
localtime(Boolean. Optional, defaults to true)- If true, use local time. Otherwise, UTC is used. This parameter is overwritten by the utc parameter.
timezone(String. Optional)- By setting this parameter, one can parse the time value in the specified timezone. The following formats are accepted:
- [+–]HH:MM (e.g. “+09:00”)
- [+–]HHMM (e.g. “+0900”)
- [+–]HH (e.g. “+09”)
- Region/Zone (e.g. “Asia/Tokyo”)
- Region/Zone/Zone (e.g. “America/Argentina/Buenos_Aires”)
- By setting this parameter, one can parse the time value in the specified timezone. The following formats are accepted:
The timezone set in this parameter takes precedence over localtime, e.g., if localtime is set to true but timezone is set to +0000, UTC would be used.
out_file
| 1 |
time[delimiter]tag[delimiter]record\n |
| 1 2 3 |
delimiter SPACE # Optional, SPACE or COMMA. “\t”(TAB) is used by default output_tag false # Optional, defaults to true. Output the tag field if true. output_time true # Optional, defaults to true. Output the time field if true. |
record is json format data. Example:
| 1 |
2014-06-08T23:59:40[TAB]file.server.logs[TAB]{“field1″:”value1″,”field2″:”value2″}\n |
其它支持的参数同 stdout。
json
| 1 |
{“field1″:”value1″,”field2″:”value2″}\n |
其它支持的参数同 stdout。
hash
| 1 |
{“field1″=>”value1″,”field2″=>”value2″}\n |
其它支持的参数同 stdout。
ltsv
| 1 |
field1[label_delimiter]value1[delimiter]field2[label_delimiter]value2\n |
| 1 2 3 |
format ltsv delimiter SPACE # Optional. “\t”(TAB) is used by default label_delimiter = # Optional. “:” is used by default |
其它支持的参数同 stdout。
single_value
| 1 |
value1\n |
single_value format supports the add_newline and message_key options.
| 1 2 |
add_newline false # Optional, defaults to true. If there is a trailing “\n” already, set it “false” message_key my_field # Optional, defaults to “message”. The value of this field is outputted. |
csv
| 1 |
“value1″[delimiter]“value2″[delimiter]“value3″\n |
csv format supports the delimiter and force_quotes options.
| 1 2 3 4 |
format csv fields field1,field2,field3 delimiter \t # Optional. “,” is used by default. force_quotes false # Optional. true is used by default. If false, value won’t be fra |
其它支持的参数同 stdout。
Fluentd UI
[Doc] http://docs.fluentd.org/articles/fluentd-ui
| 1 |
# nohup td-agent-ui start & |
访问 Flunetd UI 界面(默认用户为:admin,默认密码 changeme)

Fluentd 高可用
消息投递语义(Message Delivery Semantics)
系统可以提供的几种可能的消息传递保障,如下所示:
最多一次:消息立即传输。 如果传输成功,则不会再次发送消息。 但是,许多故障情况可能导致丢失消息(例如:没有更多的写入容量)至少一次:每条消息至少会发送一次,在故障情况下,消息可能会传送两次。仅仅一次:每条消息只会而且仅会发送一次,这种是人们实际想要的。
如果系统 “不能丢失单个事件”,并且还必须传输 “仅仅一次”,则系统必须在写入容量不足时停止提取事件。 正确的方法是使用同步日志记录并在不能接受事件时返回错误。
这就是为什么 Fluentd 提供 “最多一次” 和 “至少一次” 传输。 为了在不影响应用程序性能的情况下收集大量数据,数据记录器必须异步传输数据。 这以潜在传送失败为代价提高了性能。
然而,大多数故障情况是可预防的。 以下各节介绍如何设置 Fluentd 的拓扑以实现高可用性。
高可用架构
[Plugins]
- [主备] http://docs.fluentd.org/articles/out_forward
- [复制] http://docs.fluentd.org/articles/out_copy
网络拓扑
要配置 Fluentd 以实现高可用性,我们假设您的网络由 “日志转发器” 和 “日志聚合器” 组成。如下图所示,其中 “日志转发器” 通常安装在每个节点上以接收本地事件。 一旦接收到事件,它们通过网络将其转发到 “日志聚合器”。
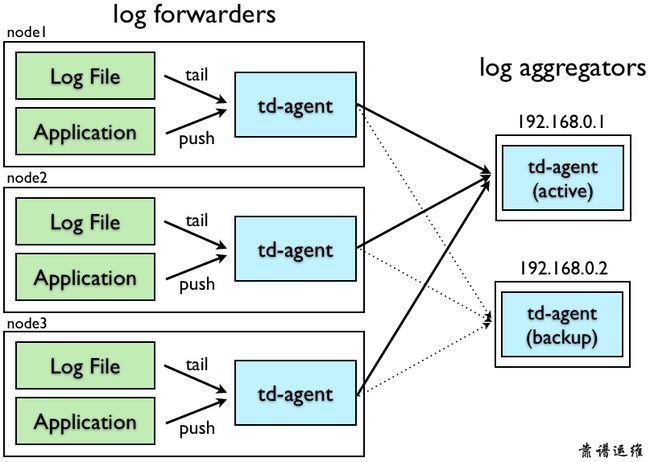
“日志聚合器” 是继续从日志转发器接收事件的守护程序。 他们缓冲事件并定期将数据上传到云中。

Fluentd 可以充当日志转发器或日志聚合器,具体取决于其配置。
日志转发器配置
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
### TCP input @type forward port 24224 ### HTTP input @type http port 9880 ### Log Forwarding @type forward # primary host host 192.168.0.1 port 24224 ### use secondary host host 192.168.0.2 port 24224 standby ### 指定备节点 ### use longer flush_interval to reduce CPU usage. ### note that this is a trade-off against latency. flush_interval 60s |
当活动聚合器(192.168.0.1)死机时,日志将被发送到备份聚合器(192.168.0.2)。 如果两个服务器都死机,则日志在相应的转发器节点上缓存在磁盘上。
日志聚合器配置
| 1 2 3 4 5 6 7 8 9 10 |
### Input @type forward port 24224 ### Output … |
传入日志被缓冲,然后定期上传到云中。 如果上传失败,日志将存储在本地磁盘上,直到重传成功。
转发器和聚合器故障失败
当日志转发器从应用程序接收事件时,事件首先写入磁盘缓冲区(由buffer_path指定)。 在每个 flush_interval 之后,缓冲的数据被转发到聚合器(或云中)。
这个过程对于数据丢失是固有的鲁棒性。 如果日志转发器(或聚合器)的 fluentd 进程死机,则缓冲的数据在重新启动后会正确传输到其聚合器(云中)。 如果转发器和聚合器(或聚合器和云)之间的网络断开,则会自动重试数据传输。
但是,存在可能的消息丢失情况:
- 在接收到事件之后,但在将它们写入缓冲器之前,处理立即结束。
- 转发器(或聚合器)的磁盘损坏,文件缓冲区丢失。
因此,请确保您可以使用不仅 TCP,而且 UDP 与端口 24224通信。 这些命令将有助于检查网络配置。
| 1 2 |
$ telnet host 24224 $ nmap -p 24224 -sU host |
案例
[Docker+fluentd] http://www.fluentd.org/guides/recipes/docker-logging
Nginx
日志格式
| 1 2 3 |
log_format main ‘$remote_addr – $remote_user [$time_local] “$request” ‘ ‘$status $body_bytes_sent “$request_body” “$http_referer” ‘ ‘”$http_user_agent” “$http_x_forwarded_for”‘; |
fluentd 配置
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
### —— NGINX —— @type tail @label @NGINX path /data/logs/**-nginx/access.log tag webapp.nginx.access format /^(?(? ]*)\] \”(?[^ ]*) (? |
Java
日志格式
| 1 |
[%-5level] [%contextName] %d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] [%X{req.remoteHost}] [%X{req.requestURI}] [%X{traceId}] %logger – %msg%n |
fluentd 配置
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
### —— JAVA —— @type tail @label @JAVA tag webapp.java.access path /data/logs/**/*.log exclude_path ["/data/logs/**/*.gz"] format multiline format_firstline /^[\w]+[\w]+ /format1 /^(? (? |
Fluentd Docker
Dockerfile
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
FROM 192.168.101.26/library/ubuntu:14.04.5 MAINTAINER Mallux “[email protected]” ENV LANG en_US.UTF-8 ENV TZ Asia/Shanghai RUN echo ‘LANG=”en_US.UTF-8″‘ > /etc/default/locale && \ echo ‘LANGUAGE=”en_US:en”‘ >> /etc/default/locale && \ ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && \ echo $TZ > /etc/timezone COPY ./archives/sources.list /etc/apt/sources.list ENV FLUENTD_VERSION 2.3.4 RUN apt-key adv –keyserver hkp://keyserver.ubuntu.com –recv EA312927 && \ apt-get update && \ apt-get install -y –no-install-recommends \ apt-transport-https curl wget vim lrzsz net-tools && \ apt-get clean && rm -rf /var/lib/apt/lists/* COPY ./archives/vimrc /root/.vimrc RUN sed -i ‘/^#force_color_prompt=yes/ s/#//’ /root/.bashrc && \ sed -i “/^if\"$colorprompt\"=yes\"$colorprompt\"=yes / { N; s/.∗PS1.∗PS1 .*/\1=’\${debian_chroot:+(\$debian_chroot)}[\\\e[0;32;1m\e[0;32;1m \\\u\\\e[0m\e[0m @\\\e[0;36;1m\e[0;36;1m \\\h\\\e[0m\e[0m \\\e[0;33;1m\e[0;33;1m \\\W\\\e[0m\e[0m ]\\\\$ ‘/}” /root/.bashrcCOPY ./archives/td-agent_2.3.4-0_amd64.deb / RUN dpkg -i /td-agent_2.3.4-0_amd64.deb && \ rm -rf /td-agent_2.3.4-0_amd64.deb && \ td-agent-gem source -a https://rubygems.org/ && \ td-agent-gem install fluent-plugin-elasticsearch \ fluent-plugin-typecast \ fluent-plugin-secure-forward COPY ./fluentd/td-agent.conf /etc/td-agent/td-agent.conf COPY ./fluentd/entrypoint.sh / RUN mkdir -p /var/log/td-agent /data/logs /data/log && \ chown td-agent.td-agent -R /var/log/td-agent && \ chmod +x /entrypoint.sh VOLUME /var/log/td-agent VOLUME /data/logs VOLUME /data/log EXPOSE 24224 EXPOSE 9880 EXPOSE 9292 ENTRYPOINT ["/entrypoint.sh"] |
entrypoint.sh
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
#!/usr/bin/env bash ### ————————————————– ### Filename: entrypoint.sh ### Revision: latest stable ### Author: Mallux ### E-mail: [email protected] ### Blog: blog.mallux.me ### Description: ### ————————————————– ### Copyright © 2014-2016 Mallux #set -e ### starting up fluentd service function gosu_td-agent { chown -R td-agent.td-agent /etc/td-agent /var/log/td-agent service td-agent start ; echo “=> Done!” nohup td-agent-ui start &>/dev/null & } gosu_td-agent while : do ### check your fluentd server is running. ps -ef | grep td-agent | grep -v grep >/dev/null 2>&1 exit_code=$? if [ x"$exit_code" != x"0" ] then echo “your fluentd server has stop, please restart it” #service td-agent restart fi ### wait for 60 seconds sleep 60 done |
END
[GitHub] https://github.com/fluent/fluentd
[Doc] http://docs.fluentd.org/articles/config-file
[Example] https://github.com/fluent/fluentd/tree/master/example
默认配置文件:/etc/td-agent/td-agent.conf
Fluentd directives
source:确定输入源match: 确定输出目的地filter:确定 event 处理流system:设置系统范围的配置label:将内部路由的输出和过滤器分组@include:包括其它文件
source 指令
通过使用 source 指令,来选择和配置所需的输入插件来启用 Fluentd 输入源。Fluentd 的标准输入插件包含 http(监听 9880) 和 forward 模式(监听 24224),分别用来接收 HTTP 请求和 TCP 请求。
http:使 fluentd 转变为一个 httpd 端点,以接受进入的 http 报文。forward:使 fluentd 转变为一个 TCP 端点,以接受 TCP 报文。
| 1 2 3 4 5 6 7 8 9 10 11 12 |
### Receive events from 24224/tcp ### This is used by log forwarding and the fluent-cat command @type forward port 24224 ### http://this.host:9880/myapp.access?json={“event”:”data”} @type http port 9880 |
每个 source 指令必须包括 “type” 参数,指定使用那种插件。
Routing(路由):source 把事件提交到 fluentd 的路由引擎中。一个事件由三个实体组成:tag、time 和 record。
tag:是一个通过 “.” 来分离的字符串(e.g. myapp.access),用作 Fluentd 内部路由引擎的方向。time:时间字段由输入插件指定,并且必须为 Unix 时间格式。record:一个 JSON 对象。
在上面的例子中,http 输入插件提交了以下的事件
| 1 2 3 4 |
### generated by http://this.host:9880/myapp.access?json={“event”:”data”} tag: myapp.access time: (current time) record: {“event”:”data”} |
match 指令
match 指令查找匹配 “tags” 的事件,并处理它们。match 命令的最常见用法是将事件输出到其他系统(因此,与 match 命令对应的插件称为 “输出插件”)。 Fluentd 的标准输出插件包括 file 和 forward。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
### Receive events from 24224/tcp ### This is used by log forwarding and the fluent-cat command @type forward port 24224 ### http://this.host:9880/myapp.access?json={“event”:”data”} @type http port 9880 ### Match events tagged with “myapp.access” and ### store them to /var/log/fluent/access.%Y-%m-%d ### Of course, you can control how you partition your data ### with the time_slice_format option. @type file path /var/log/fluent/access |
每个 match 指令必须包括一个匹配模式和 type 参数。只有与模式匹配的 “tags” 事件才会发送到输出目标(在上面的示例中,只有标记 “myapp.access” 的事件匹配)。type 参数指定使用哪种输出插件。
match 模式
*:匹配单个 tag 部分- 例:a.*,匹配 a.b,但不匹配 a 或者 a.b.c
**:匹配 0 或 多个 tag 部分- 例:a.**,匹配 a、a.b 和 a.b.c
{X,Y,Z}:匹配 X、Y 或 Z,其中 X、Y 和 Z 是匹配模式。可以和*和**模式组合使用- 例 1:{a, b},匹配 a 和 b,但不匹配 c
- 例 2:a.{b,c}. 和 a.{b,c.*}
- 当多个模式列在一个
Fluentd 尝试按照它们在配置文件中出现的顺序,从上到下来进行 "tags" 匹配 。 所以,如果是下面的配置,那么 myapp.access 将永远不会匹配。
| 1 2 3 4 5 6 7 8 9 |
### ** matches all tags. Bad @type blackhole_plugin @type file path /var/log/fluent/access |
filter 指令
Event processing pipeling(事件处理流)
“filter” 指令具有与 “match” 相同的语法,但是 filter 可以串联成 pipeline,对数据进行串行处理,最终再交给 match 输出。 使用 fliters,事件流如下:
| 1 |
Input -> filter 1 -> … -> filter N -> Output(Match tag) |
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
### http://this.host:9880/myapp.access?json={“event”:”data”} @type http port 9880 @type record_transformer host_param “#{Socket.gethostname}” @type file path /var/log/fluent/access |
这个例子里,filter 获取数据后,调用原生的 @type record_transformer 插件,在事件的 record 里插入了新的字段 host_param,然后再交给 match 输出。
filter 匹配顺序与 match 相同,我们应该在
system 指令
fluentd 的相关设置,可以在启动时设置,也可以在配置文件里设置,包含:
- log_level
- suppress_repeated_stacktrace
- emit_error_log_interval
- suppress_config_dump
- without_source
例 1:fluentd 启动配置
| 1 2 3 4 5 6 7 |
# equal to -qq option log_level error # equal to –without-source option without_source # … |
例 2:fluentd 进程名
| 1 2 3 |
process_name fluentd1 |
| 1 2 3 |
% ps aux | grep fluentd1 foo 45673 0.4 0.2 2523252 38620 s001 S+ 7:04AM 0:00.44 worker:fluentd1 foo 45647 0.0 0.1 2481260 23700 s001 S+ 7:04AM 0:00.40 supervisor:fluentd1 |
label 指令
label 用于将任务进行分组,方便复杂任务的管理。
@label @
你可以在 source 里指定 @label @,这个 source 所触发的事件就会被发送给指定的 label 所包含的任务,而不会被后续的其他任务获取到。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
@type forward ### 这个任务指定了 label 为 @SYSTEM ### 会被发送给 ### 而不会被发送给下面紧跟的 filter 和 match @type tail @label @SYSTEM @type record_transformer # … @type elasticsearch # … ### 将会接收到上面 @type tail 的 source event @type grep # … @type s3 # … |
@ERROR label
用来接收插件通过调用 emit_error_event API 抛出的异常,使用方法和 label 一样,通过设定 就可以接收到相关的异常。
include 指令
导入其它独立的配置文件中的指令,这些文件可以使用:
- 相对路径
- 绝对路由
- HTTP URL
Fluentd Plugins
[Plugins] http://www.fluentd.org/plugins
Fluentd 有 6 种类型的插件:
Input:输入Output:输出Buffer:缓冲区Filter:过滤器Parset:解析器Formatter:格式化器
Input Plugins
[Doc] http://docs.fluentd.org/articles/input-plugin-overview
input 插件扩展 Fluentd,以从外部源检索和拉取事件日志。 input 插件通常创建线程套接字和侦听套接字。 它还可以被写入以周期性地从数据源拉取数据。
- in_udp
- in_tcp
- in_forward
- in_secure_forward
- in_http
- in_unix
- in_tail
- in_exec
- in_syslog
- in_scribe
- in_multiprocess
- in_dummy
in_udp
[Doc] http://docs.fluentd.org/articles/in_tcp
Parameters:
- type(required)
- tag( required)
- port
- bind
- delimiter
- source_host_key
- format (required): 参见 “2.5 Parser Plugins”
- regexp
- apache2
- apoache_error
- nginx
- syslog
- tsv or csv
- ltsv
- json
- none
- mulitline
- keep_time_key
- log_level
- fatal
- error
- warn
- info
- debug
- trace
in_tcp
[Doc] http://docs.fluentd.org/articles/in_tcp
Parameters: 同 in_udp
in_forward
[Doc] http://docs.fluentd.org/articles/in_forward
- 侦听 TCP 套接字以接收事件流,它还侦听 UDP 套接字以接收心跳消息
- in_forward 不提供解析机制,不像 in_tail 或 in_tcp,因为 in_forward 主要是为了高效的日志传输。 如果要解析传入事件,请在 pipeline 中使用 parser filter
Parameters:
- type(required):forward
- port
- bind
- linger_timeout
- chunk_zine_limit
- chunk_size_warn_limit
- skip_invalid_event
- source_hostname_key
- log_level
in_secure_forward
[Doc] http://docs.fluentd.org/articles/in_secure_forward
in_http
[Doc] http://docs.fluentd.org/articles/in_http
Parameters:
- type(required):forward
- port
- bind
- body_size_limit
- keepalive_timeout
- add_http_headers
- add_remote_addr
- cors_allow_origins
- format: 参见 “2.5 Parser Plugins”
- default:json、msgpack
- regexp
- json
- ltsv
- tsv or csv
- none
- log_level
in_unix
[Doc] http://docs.fluentd.org/articles/in_unix
in_tail
[Doc] http://docs.fluentd.org/articles/in_tail
- When Fluentd is first configured with in_tail, it will start reading from the tail of that log, not the beginning.
- Once the log is rotated, Fluentd starts reading the new file from the beginning. It keeps track of the current inode number.
- If td-agent restarts, it starts reading from the last position td-agent read before the restart. This position is recorded in the position file specified by the pos_file parameter.
| 1 2 3 4 5 6 7 8 9 |
@type tail path /var/log/httpd-access.log exclude_path ["/var/log/*.gz", "/var/log/*.zip"] pos_file /var/log/td-agent/httpd-access.log.pos tag apache.access format apache2 keep_time_key false |
Parameters:
- type (required)
- tag (required)
- path (required)
- exclude_path
- refresh_interval
- read_from_head
- read_lines_limit
- multiline_flush_interval
- pos_file (highly recommended)
- format (required): 参见 “2.5 Parser Plugins”
- regexp
- apache2
- apache_error
- nginx
- syslog
- tsv or csv
- ltsv
- json
- none
- multiline
- time_format
- rotate_wait
- enable_watch_timer
in_exec
[Doc] http://docs.fluentd.org/articles/in_exec
in_exec Input 插件执行外部程序以接收或拉取事件日志。 然后它将从程序的 stdout 读取 TSV(制表符分隔值),JSON 或 MessagePack。
Example:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
@type exec command cmd arg arg keys k1,k2,k3 tag_key k1 time_key k2 time_format %Y-%m-%d %H:%M:%S run_interval 10s @type exec format json tag hackernews command ruby /path/to/hn.rb run_interval 5m # don’t hit HN too frequently! @type stdout |
Parameters:
- type(required)
- command(required)
- format
- tsv(default)
- josn
- msgpack
- tag (required if tag_key is not specified)
- tag_key
- time_key
- time_format
- run_interval
- log_level
in_syslog
[Doc] http://docs.fluentd.org/articles/in_syslog
Parameters:
- type(required)
- port
- bind
- protocol_type
- tag(required)
- format: 参见 “2.5 Parser Plugins”
- regexp
- apache2
- apache_error
- nginx
- syslog
- tsv or osv
- ltsv
- json
- none
- multiline
Othter
- in_scribe
- in_multiprocess
- in_dummy
Ouput Plugins
[Doc] http://docs.fluentd.org/articles/output-plugin-overview
- out_file
- out_forward
- out_secure_forward
- out_exec
- out_exec_filter
- out_copy
- out_geoip
- out_roundrobin
- out_stdout
- out_null
- out_s3
- out_mongo
- out_mongo_replset
- out_relabel
- out_rewrite_tag_filter
- out_webhdfs
Plugins Type
输出插件的缓冲区行为(如果有的话)由单独的缓冲区插件定义。 可以为每个输出插件选择不同的缓冲区插件。 一些输出插件是完全自定义的,不使用缓冲区。
Non-Buffered- 非缓冲输出插件不缓冲数据并立即写出结果。
- includes:
- out_copy
- out_stdout
- out_null
- out_stdout
Buffered- 时间切片输出插件事实上是一种缓冲插件,但块是按时间键入的。
- includes:
- out_exec_filter
- out_forward
- out_mongo or out_mongo_replset
Time Sliced- 时间切片输出插件事实上是一种缓冲插件,但块是按时间键入的。
- includes:
- out_exec
- out_file
- out_s3
- out_webhdfs
out_file
[Doc] http://docs.fluentd.org/articles/out_file
out_file TimeSliced 输出插件将事件写入文件。 默认情况下,它每天创建文件(大约 00:10)。 这意味着,当您首次使用插件导入记录时,不会立即创建文件。 当满足 time_slice_format 条件时,将创建该文件。 要更改输出频率,请修改 time_slice_format 值。
Example:
| 1 2 3 4 5 6 7 8 9 |
@type file path /var/log/fluent/myapp time_slice_format %Y%m%d time_slice_wait 10m time_format %Y%m%dT%H%M%S%z ### 20170104T202425+0800 compress gzip utc |
Parameters:
type (required)path (required)append:默认值 false,即刷新日志到不同的文件;若为 true 则输出到同一文件,直到触发 time_slice_formatformat:默认值 out_file,其它格式有:json、hash、ltsv、single_value、csv、stdout,参见 “2.6 Formatter Plugins”time_formatutccompress:gzipsymlink_path:当 buffer_type 是文件时,创建到临时缓冲文件的符号链接。 默认情况下不创建符号链接。This is useful for tailing file content to check logs.
Time Sliced Output Parameters:
- time_slice_format:
- The default format is %Y%m%d%H, which creates one file per hour.
- time_slice_wait
- buffer_type
- buffer_queue_limit, buffer_chunk_limit
- flush_interval
- flush_at_shutdown
- retry_wait, max_retry_wait
- retry_limit, disable_retry_limit
- num_threads
- slow_flush_log_threshold
out_forward
[Doc] http://docs.fluentd.org/articles/out_forward
out_forward 缓冲输出插件将事件转发到其他 fluentd节点。 此插件支持负载平衡和自动故障切换(又名主动 – 主动备份)。 对于复制,请使用 out_copy 插件。
out_forward 插件使用 “φaccrual failure detector” 算法检测服务器故障。 您可以自定义算法的参数。 当服务器故障恢复时,插件使服务器在几秒钟后自动可用。
out_forward 插件支持最多一次和至少一次消息投递语义。 默认值为最多一次。参见 “4. Fluentd 高可用”。
Example:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
@type forward send_timeout 60s recover_wait 10s heartbeat_interval 1s phi_threshold 16 hard_timeout 60s name myserver1 host 192.168.1.3 port 24224 weight 60 name myserver2 host 192.168.1.4 port 24224 weight 60 … @type file path /var/log/fluent/forward-failed |
Parameters:
- type (required)
- require_ack_response
- ack_response_timeout
- send_timeout
- recover_wait
- heartbeat_type
- heartbeat_interval
- phi_failure_detector
- phi_threshold
- hard_timeout
standby- expire_dns_cache
- dns_round_robin
Buffered Output Parameters:
- buffer_type
- buffer_queue_limit, buffer_chunk_limit
- flush_interval
- flush_at_shutdown
- retry_wait, max_retry_wait
- retry_limit, disable_retry_limit
- num_threads
- slow_flush_log_threshold
out_copy
[Doc] http://docs.fluentd.org/articles/out_copy
copy 输出插件将事件复制到多个输出。
Parameters:
- type (required)
- deep_copy
Example:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
@type copy @type file path /var/log/fluent/myapp time_slice_format %Y%m%d time_slice_wait 10m time_format %Y%m%dT%H%M%S%z compress gzip utc @type mongo host fluentd port 27017 database fluentd collection test |
out_stdout
[Doc] http://docs.fluentd.org/articles/out_stdout
stdout 输出插件将事件打印到 stdout(或日志,如果以守护进程模式启动)。 对于调试目的,这个输出插件是很有用的。
Parameters
- type (required)
- output_type:json or hash (Ruby’s hash)
out_exec
[Doc] http://docs.fluentd.org/articles/out_exec
out_exec TimeSliced 输出插件将事件传递到外部程序。 程序接收包含传入事件作为其最后一个参数的文件的路径。 默认情况下,文件格式为制表符分隔值(TSV)。
Parameters:
- type (required)
- command (required)
- format
- tsv(default)
- json
- msgpack
- tag_key
- time_key
- time_format
Time Sliced Output Parameters:
- time_slice_format
- time_slice_wait
- buffer_type
- buffer_queue_limit, buffer_chunk_limit
- flush_interval
- flush_at_shutdown
- retry_wait, max_retry_wait
- retry_limit, disable_retry_limit
- num_threads
- slow_flush_log_threshold
Buffer Plugins
[Doc] http://docs.fluentd.org/articles/buffer-plugin-overview
- buf_memory
- buf_file
缓冲插件由缓冲输出插件使用,如 out_file,out_forward 等。用户可以选择最适合其性能和可靠性需求的缓冲插件。
Buffer Structure
The buffer structure is a queue of chunks like the following:
| 1 2 3 4 5 6 7 8 9 10 11 12 |
queue +———+ | | | chunk <– write events to the top chunk | | | chunk | | | | chunk | | | | chunk –> write out the bottom chunk | | +———+ |
When the top chunk exceeds the specified size or time limit (buffer_chunk_limit and flush_interval, respectively), a new empty chunk is pushed to the top of the queue. The bottom chunk is written out immediately when new chunk is pushed.
If the bottom chunk fails to be written out, it will remain in the queue and Fluentd will retry after waiting several seconds (retry_wait). If the retry limit has not been disabled (disable_retry_limit is false) and the retry count exceeds the specified limit (retry_limit), the chunk is trashed. The retry wait time doubles each time (1.0sec, 2.0sec, 4.0sec, …) until max_retry_wait is reached. If the queue length exceeds the specified limit (buffer_queue_limit), new events are rejected.
Filter Plugins
[Doc] http://docs.fluentd.org/articles/filter-plugin-overview
- filter_record_transformer
- filter_grep
- filter_parser
- filter_stdout
过滤插件使 Fluentd 可以修改事件流。 示例用例:
- 通过删除一个或多个字段的值来过滤事件
- 通过添加新字段丰富事件
- 删除或屏蔽某些字段,以确保隐私权和合规性。
Example:
| 1 2 3 4 5 6 7 8 9 10 11 |
@type grep regexp1 message cool @type record_transformer hostname “#{Socket.gethostname}” |
Only the events whose “message” field contain “cool” get the new field “hostname” with the machine’s hostname as its value.
filter_record_transformer
[Doc] http://docs.fluentd.org/articles/filter_record_transformer
The filter_record_transformer filter plugin mutates/transforms incoming event streams in a versatile manner. If there is a need to add/delete/modify events, this plugin is the first filter to try.
Parameters
- enable_ruby (optional)
- auto_typecast (optional)
- renew_record (optional)
- renew_time_key (optional, string type)
- keep_keys (optional, string type)
- remove_keys (optional, string type)
Example:
| 1 2 3 4 5 6 7 |
@type record_transformer hostname “#{Socket.gethostname}” tag ${tag} |
The above filter adds the new field “hostname” with the server’s hostname as its value (It is taking advantage of Ruby’s string interpolation) and the new field “tag” with tag value. So, an input like
| 1 |
{“message”:”hello world!”} |
is transformed into
| 1 |
{“message”:”hello world!”, “hostname”:”db001.internal.example.com”, “tag”:”foo.bar”} |
Parameters inside directives are considered to be new key-value pairs:
| 1 2 3 |
NEW_FIELD NEW_VALUE |
对于NEW_FIELD和NEW_VALUE,特殊语法${}允许用户动态生成新字段。 在花括号中,以下变量可用:
- The incoming event’s existing values can be referred
by their field names. So, if the record is {“total”:100, “count”:10}, then total=10 and count=10. tag_parts[N]:refers to the Nth part of the tag. It works like the usual zero-based array accessor.tag_prefix[N]:refers to the first N parts of the tag. It works like the usual zero-based array accessor.tag_suffix[N]:refers to the last N parts of the tag. It works like the usual zero-based array accessor.tag:refers to the whole tag.time:refers to stringanized event time.
filter_grep
[Doc] http://docs.fluentd.org/articles/filter_grep
filter_grep 过滤器插件通过指定字段的值 “greps” 事件。
Parameters
- regexpN (optional)
- excludeN (optional)
Example:
| 1 2 3 4 5 6 |
@type grep regexp1 message cool regexp2 hostname ^web\d+\.example\.com$ exclude1 message uncool |
regexpN (optional)
The “N” at the end should be replaced with an integer between 1 and 20 (ex: “regexp1”). regexpN takes two whitespace-delimited arguments.
- The first argument is the field name to which the regular expression is applied.
- The second argument is the regular expression.
The above example matches any event that satisfies the following conditions:
- The value of the “message” field contains “cool”
- The value of the “hostname” field matches web.example.com.
- The value of the “message” field does NOT contain “uncool”.
因此,以下事件将被保留:
| 1 2 |
{“message”:”It’s cool outside today”, “hostname”:”web001.example.com”} {“message”:”That’s not cool”, “hostname”:”web1337.example.com”} |
而以下事件被过滤掉:
| 1 2 3 |
{“message”:”I am cool but you are uncool”, “hostname”:”db001.example.com”} {“hostname”:”web001.example.com”} {“message”:”It’s cool outside today”} |
filter_parser
[Doc] http://docs.fluentd.org/articles/filter_parser
filter_parser 过滤器插件在事件记录中 “解析” 字符串字段,并使用解析的结果更改其事件记录。
Parameters
- reserve_data
- suppress_parse_error_log
- replace_invalid_sequence
- inject_key_prefix
- hash_value_field
- time_parse
Example:
| 1 2 3 4 5 6 |
@type parser format /^(?(? ]*)\] “(?[^ ]*) (? |
filter_parser 使用内置的解析器插件和您自己的自定义解析器插件,因此您可以重新使用像 apache,json 等预定义的格式。有关详细信息,参见 “2.5 Parser Plugins”。
filter_stdout
[Doc] http://docs.fluentd.org/articles/filter_stdout
filter_stdout 过滤器插件将事件打印到 stdout(或日志,如果以守护进程模式启动)。 对于调试目的,这个过滤器插件是很有用的。
Parameters:
- type(required)
- format:stdout
- output_type:可以指定任何格式化插件,默认为 json。
- out_file
Parser Plugins
[Doc] http://docs.fluentd.org/articles/parser-plugin-overview
有时,输入插件(例如:in_tail,in_syslog,in_tcp 和 in_udp)的格式参数无法解析用户的自定义数据格式(例如,不能使用正则表达式解析的上下文相关语法)。 为了解决这种情况,对于 v0.10.46 及以上版本,Fluentd 有一个可插拔的系统,使用户能够创建自己的解析器格式。
| 1 2 3 4 5 |
@type tail path /path/to/input/file format my_custom_parser ### 自定义解析器格式 |
List of Core Input Plugins with Parser support
with format parameter.
- in_tail
- in_tcp
- in_udp
- in_syslog
- in_http
List of Built-in Parsers(内置解析列表)
regexp
The regexp for the format parameter can be specified. If the parameter value starts and ends with “/”, it is considered to be a regexp. The regexp must have at least one named capture (? If the regexp has a capture named ‘time’, it is used as the time of the event. You can specify the time format using the time_format parameter.
apache2
Reads apache’s log file for the following fields: host, user, time, method, path, code, size, referer and agent. This template is analogous to the following configuration:
| 1 2 |
format /^(? (? ]*)\] “(?[^ ]*) (? |
apache_error
Reads apache’s error log file for the following fields: time, level, pid, client and (error) message. This template is analogous to the following configuration:
| 1 |
format /^ [^ ]* (? ]*)\](? pid (? client (? |
nginx
Reads Nginx’s log file for the following fields: remote, user, time, method, path, code, size, referer and agent. This template is analogous to the following configuration:
| 1 2 |
format /^(? (? ]*)\] “(?[^ ]*) (? |
syslog
Reads syslog’s output file (e.g. /var/log/syslog) for the following fields: time, host, ident, and message. This template is analogous to the following configuration:
| 1 2 |
format /^(? |
tsv or csv
If you use tsv or csv format, please also specify the keys parameter.
| 1 2 3 |
format tsv keys key1,key2,key3 time_key key2 |
If you specify the time_key parameter, it will be used to identify the timestamp of the record. The timestamp when Fluentd reads the record is used by default.
| 1 2 3 |
format csv keys key1,key2,key3 time_key key3 |
ltsv
ltsv (Labeled Tab-Separated Value) is a tab-delimited key-value pair format. You can learn more about it on its webpage.
| 1 2 3 |
format ltsv delimiter = # Optional. ‘:’ is used by default time_key time_field_name |
If you specify the time_key parameter, it will be used to identify the timestamp of the record. The timestamp when Fluentd reads the record is used by default.
json
One JSON map, per line. This is the most straight forward format :).
| 1 |
from json |
One JSON map, per line. This is the most straight forward format :).
| 1 2 |
format json time_key key3 |
none
You can use the none format to defer parsing/structuring the data. This will parse the line as-is with the key name “message”. For example, if you had a line
| 1 |
hello world. I am a line of log! |
It will be parsed as
| 1 |
{“message”:”hello world. I am a line of log!”} |
The key field is “message” by default, but you can specify a different value using the message_key parameter as shown below:
| 1 2 |
format none message_key my_message |
multiline
Read multiline log with formatN and format_firstline parameters. format_firstline is for detecting start line of multiline log. formatN, N’s range is 1..20, is the list of Regexp format for multiline log. Here is Rails log Example:
| 1 2 3 4 5 6 7 |
format multiline format_firstline /^Started/ format1 /Started (? format2 /Processing by (? format3 /( Parameters: (? format4 / Rendered (?[^ ]+) within (? format5 /Completed (? |
If you have a multiline log
| 1 2 3 4 5 |
Started GET “/users/123/” for 127.0.0.1 at 2013-06-14 12:00:11 +0900 Processing by UsersController#show as HTML Parameters: {“user_id”=>”123″} Rendered users/show.html.erb within layouts/application (0.3ms) Completed 200 OK in 4ms (Views: 3.2ms | ActiveRecord: 0.0ms) |
It will be parsed as
| 1 |
{“method”:”GET”,”path”:”/users/123/”,”host”:”127.0.0.1″,”controller”:”UsersController”,”controller_method”:”show”,”format”:”HTML”,”parameters”:”{ \”user_id\” = >\”123\”}”, …} |
One more example, you can parse Java like stacktrace logs with multiline. Here is a configuration example.
| 1 2 3 |
format multiline format_firstline /\d{4}-\d{1,2}-\d{1,2}/ format1 /^(? |
If you have a following log:
| 1 2 3 4 5 |
2013-3-03 14:27:33 [main] INFO Main – Start 2013-3-03 14:27:33 [main] ERROR Main – Exception javax.management.RuntimeErrorException: null at Main.main(Main.java:16) ~[bin/:na] 2013-3-03 14:27:33 [main] INFO Main – End |
It will be parsed as:
| 1 2 3 |
2013-03-03 14:27:33 +0900 zimbra.mailbox: {“thread”:”main”,”level”:”INFO”,”message”:” Main – Start”} 2013-03-03 14:27:33 +0900 zimbra.mailbox: {“thread”:”main”,”level”:”ERROR”,”message”:” Main – Exception\njavax.management.RuntimeErrorException: null\n at Main.main(Main.java:16) ~[bin/:na]“} 2013-03-03 14:27:33 +0900 zimbra.mailbox: {“thread”:”main”,”level”:”INFO”,”message”:” Main – En |
Formatter Plugins
[Doc] http://docs.fluentd.org/articles/formatter-plugin-overview
有时,输出插件的输出格式不能满足需要。 Fluentd 有一个称为文本格式器的可插拔系统,允许用户扩展和重新使用自定义输出格式。
对于支持文本格式器的输出插件,format 参数可用于更改输出格式。
For example, by default, out_file plugin outputs data as
| 1 |
2014-08-25 00:00:00 +0000 |
However, if you set format json like this
| 1 2 3 4 5 |
@type file path /path/to/file format json ### 格式化日志输出 |
The output changes to
| 1 |
{“time”: “2014-08-25 00:00:00 +0000″, “tag”:”foo.bar”, “k1:”v1″, “k2″:”v2″} |
List of Output Plugins with Text Formatter Support
- out_file
- out_s3
List of Built-in Formatters
stdout
此格式旨在由 stdout 插件使用。
Output time, tag and formatted record as follows:
| 1 |
time tag: formatted_record\n |
Example:
| 1 |
2015-05-02 12:12:17 +0900 tag: {“field1″:”value1″,”field2″:”value2″}\n |
stdout format has a following option to customize the format of the record part.
| 1 2 |
output_type format # Optional, defaults to “json”. The format of `formatted_record`. Any formatter plugins can be specified. |
For this format, the following common parameters are also supported.
include_time_key(Boolean, Optional, defaults to false)- If true, the time field (as specified by the time_key parameter) is kept in the record.
time_key(String, xOptional, defaults to “time”)- The field name for the time key.
time_format(String. Optional)- By default, the output format is iso8601 (e.g. “2008-02-01T21:41:49”). One can specify their own format with this parameter.
include_tag_key(Boolean. Optional, defaults to false)- If true, the tag field (as specified by the tag_key parameter) is kept in the record.
tag_key(String, Optional, defaults to “tag”)- The field name for the tag key.
localtime(Boolean. Optional, defaults to true)- If true, use local time. Otherwise, UTC is used. This parameter is overwritten by the utc parameter.
timezone(String. Optional)- By setting this parameter, one can parse the time value in the specified timezone. The following formats are accepted:
- [+–]HH:MM (e.g. “+09:00”)
- [+–]HHMM (e.g. “+0900”)
- [+–]HH (e.g. “+09”)
- Region/Zone (e.g. “Asia/Tokyo”)
- Region/Zone/Zone (e.g. “America/Argentina/Buenos_Aires”)
- By setting this parameter, one can parse the time value in the specified timezone. The following formats are accepted:
The timezone set in this parameter takes precedence over localtime, e.g., if localtime is set to true but timezone is set to +0000, UTC would be used.
out_file
| 1 |
time[delimiter]tag[delimiter]record\n |
| 1 2 3 |
delimiter SPACE # Optional, SPACE or COMMA. “\t”(TAB) is used by default output_tag false # Optional, defaults to true. Output the tag field if true. output_time true # Optional, defaults to true. Output the time field if true. |
record is json format data. Example:
| 1 |
2014-06-08T23:59:40[TAB]file.server.logs[TAB]{“field1″:”value1″,”field2″:”value2″}\n |
其它支持的参数同 stdout。
json
| 1 |
{“field1″:”value1″,”field2″:”value2″}\n |
其它支持的参数同 stdout。
hash
| 1 |
{“field1″=>”value1″,”field2″=>”value2″}\n |
其它支持的参数同 stdout。
ltsv
| 1 |
field1[label_delimiter]value1[delimiter]field2[label_delimiter]value2\n |
| 1 2 3 |
format ltsv delimiter SPACE # Optional. “\t”(TAB) is used by default label_delimiter = # Optional. “:” is used by default |
其它支持的参数同 stdout。
single_value
| 1 |
value1\n |
single_value format supports the add_newline and message_key options.
| 1 2 |
add_newline false # Optional, defaults to true. If there is a trailing “\n” already, set it “false” message_key my_field # Optional, defaults to “message”. The value of this field is outputted. |
csv
| 1 |
“value1″[delimiter]“value2″[delimiter]“value3″\n |
csv format supports the delimiter and force_quotes options.
| 1 2 3 4 |
format csv fields field1,field2,field3 delimiter \t # Optional. “,” is used by default. force_quotes false # Optional. true is used by default. If false, value won’t be fra |
其它支持的参数同 stdout。
Fluentd UI
[Doc] http://docs.fluentd.org/articles/fluentd-ui
| 1 |
# nohup td-agent-ui start & |
访问 Flunetd UI 界面(默认用户为:admin,默认密码 changeme)
Fluentd 高可用
消息投递语义(Message Delivery Semantics)
系统可以提供的几种可能的消息传递保障,如下所示:
最多一次:消息立即传输。 如果传输成功,则不会再次发送消息。 但是,许多故障情况可能导致丢失消息(例如:没有更多的写入容量)至少一次:每条消息至少会发送一次,在故障情况下,消息可能会传送两次。仅仅一次:每条消息只会而且仅会发送一次,这种是人们实际想要的。
如果系统 “不能丢失单个事件”,并且还必须传输 “仅仅一次”,则系统必须在写入容量不足时停止提取事件。 正确的方法是使用同步日志记录并在不能接受事件时返回错误。
这就是为什么 Fluentd 提供 “最多一次” 和 “至少一次” 传输。 为了在不影响应用程序性能的情况下收集大量数据,数据记录器必须异步传输数据。 这以潜在传送失败为代价提高了性能。
然而,大多数故障情况是可预防的。 以下各节介绍如何设置 Fluentd 的拓扑以实现高可用性。
高可用架构
[Plugins]
- [主备] http://docs.fluentd.org/articles/out_forward
- [复制] http://docs.fluentd.org/articles/out_copy
网络拓扑
要配置 Fluentd 以实现高可用性,我们假设您的网络由 “日志转发器” 和 “日志聚合器” 组成。如下图所示,其中 “日志转发器” 通常安装在每个节点上以接收本地事件。 一旦接收到事件,它们通过网络将其转发到 “日志聚合器”。
“日志聚合器” 是继续从日志转发器接收事件的守护程序。 他们缓冲事件并定期将数据上传到云中。
Fluentd 可以充当日志转发器或日志聚合器,具体取决于其配置。
日志转发器配置
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
### TCP input @type forward port 24224 ### HTTP input @type http port 9880 ### Log Forwarding @type forward # primary host host 192.168.0.1 port 24224 ### use secondary host host 192.168.0.2 port 24224 standby ### 指定备节点 ### use longer flush_interval to reduce CPU usage. ### note that this is a trade-off against latency. flush_interval 60s |
当活动聚合器(192.168.0.1)死机时,日志将被发送到备份聚合器(192.168.0.2)。 如果两个服务器都死机,则日志在相应的转发器节点上缓存在磁盘上。
日志聚合器配置
| 1 2 3 4 5 6 7 8 9 10 |
### Input @type forward port 24224 ### Output … |
传入日志被缓冲,然后定期上传到云中。 如果上传失败,日志将存储在本地磁盘上,直到重传成功。
转发器和聚合器故障失败
当日志转发器从应用程序接收事件时,事件首先写入磁盘缓冲区(由buffer_path指定)。 在每个 flush_interval 之后,缓冲的数据被转发到聚合器(或云中)。
这个过程对于数据丢失是固有的鲁棒性。 如果日志转发器(或聚合器)的 fluentd 进程死机,则缓冲的数据在重新启动后会正确传输到其聚合器(云中)。 如果转发器和聚合器(或聚合器和云)之间的网络断开,则会自动重试数据传输。
但是,存在可能的消息丢失情况:
- 在接收到事件之后,但在将它们写入缓冲器之前,处理立即结束。
- 转发器(或聚合器)的磁盘损坏,文件缓冲区丢失。
因此,请确保您可以使用不仅 TCP,而且 UDP 与端口 24224通信。 这些命令将有助于检查网络配置。
| 1 2 |
$ telnet host 24224 $ nmap -p 24224 -sU host |
案例
[Docker+fluentd] http://www.fluentd.org/guides/recipes/docker-logging
Nginx
日志格式
| 1 2 3 |
log_format main ‘$remote_addr – $remote_user [$time_local] “$request” ‘ ‘$status $body_bytes_sent “$request_body” “$http_referer” ‘ ‘”$http_user_agent” “$http_x_forwarded_for”‘; |
fluentd 配置
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
### —— NGINX —— @type tail @label @NGINX path /data/logs/**-nginx/access.log tag webapp.nginx.access format /^(?(? ]*)\] \”(?[^ ]*) (? |
Java
日志格式
| 1 |
[%-5level] [%contextName] %d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] [%X{req.remoteHost}] [%X{req.requestURI}] [%X{traceId}] %logger – %msg%n |
fluentd 配置
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
### —— JAVA —— @type tail @label @JAVA tag webapp.java.access path /data/logs/**/*.log exclude_path ["/data/logs/**/*.gz"] format multiline format_firstline /^[\w]+[\w]+ /format1 /^(? (? |
Fluentd Docker
Dockerfile
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
FROM 192.168.101.26/library/ubuntu:14.04.5 MAINTAINER Mallux “[email protected]” ENV LANG en_US.UTF-8 ENV TZ Asia/Shanghai RUN echo ‘LANG=”en_US.UTF-8″‘ > /etc/default/locale && \ echo ‘LANGUAGE=”en_US:en”‘ >> /etc/default/locale && \ ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && \ echo $TZ > /etc/timezone COPY ./archives/sources.list /etc/apt/sources.list ENV FLUENTD_VERSION 2.3.4 RUN apt-key adv –keyserver hkp://keyserver.ubuntu.com –recv EA312927 && \ apt-get update && \ apt-get install -y –no-install-recommends \ apt-transport-https curl wget vim lrzsz net-tools && \ apt-get clean && rm -rf /var/lib/apt/lists/* COPY ./archives/vimrc /root/.vimrc RUN sed -i ‘/^#force_color_prompt=yes/ s/#//’ /root/.bashrc && \ sed -i “/^if\"$colorprompt\"=yes\"$colorprompt\"=yes / { N; s/.∗PS1.∗PS1 .*/\1=’\${debian_chroot:+(\$debian_chroot)}[\\\e[0;32;1m\e[0;32;1m \\\u\\\e[0m\e[0m @\\\e[0;36;1m\e[0;36;1m \\\h\\\e[0m\e[0m \\\e[0;33;1m\e[0;33;1m \\\W\\\e[0m\e[0m ]\\\\$ ‘/}” /root/.bashrcCOPY ./archives/td-agent_2.3.4-0_amd64.deb / RUN dpkg -i /td-agent_2.3.4-0_amd64.deb && \ rm -rf /td-agent_2.3.4-0_amd64.deb && \ td-agent-gem source -a https://rubygems.org/ && \ td-agent-gem install fluent-plugin-elasticsearch \ fluent-plugin-typecast \ fluent-plugin-secure-forward COPY ./fluentd/td-agent.conf /etc/td-agent/td-agent.conf COPY ./fluentd/entrypoint.sh / RUN mkdir -p /var/log/td-agent /data/logs /data/log && \ chown td-agent.td-agent -R /var/log/td-agent && \ chmod +x /entrypoint.sh VOLUME /var/log/td-agent VOLUME /data/logs VOLUME /data/log EXPOSE 24224 EXPOSE 9880 EXPOSE 9292 ENTRYPOINT ["/entrypoint.sh"] |
entrypoint.sh
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
#!/usr/bin/env bash ### ————————————————– ### Filename: entrypoint.sh ### Revision: latest stable ### Author: Mallux ### E-mail: [email protected] ### Blog: blog.mallux.me ### Description: ### ————————————————– ### Copyright © 2014-2016 Mallux #set -e ### starting up fluentd service function gosu_td-agent { chown -R td-agent.td-agent /etc/td-agent /var/log/td-agent service td-agent start ; echo “=> Done!” nohup td-agent-ui start &>/dev/null & } gosu_td-agent while : do ### check your fluentd server is running. ps -ef | grep td-agent | grep -v grep >/dev/null 2>&1 exit_code=$? if [ x"$exit_code" != x"0" ] then echo “your fluentd server has stop, please restart it” #service td-agent restart fi ### wait for 60 seconds sleep 60 done |