R语言数据筛选、汇总、重构
最近学习的知识点总结如下:
3.1 去掉多余的数据
1)去掉不需要的行:
使用sqldf包中的sqldf()函数使用sql语句进行操作
library(sqldf)
sqldf("select* from mtcars where am=1 and vs=1") 运行结果如下:
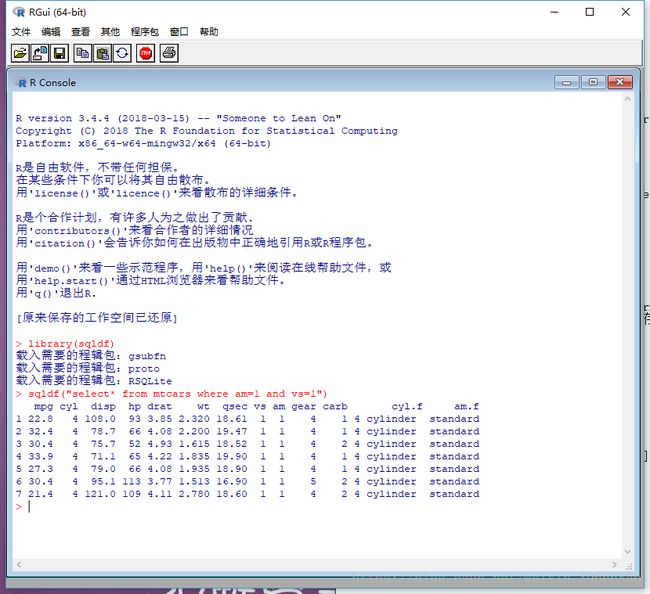
与上面语句相同结果的语句如下:
subset(mtcars,am==1&vs==1) 运行结果如下:

这是由于sqdf()函数的默认参数row.names=FALSE,需要修改为TRUE。然后结果就一致,比较结果是否一致用的函数是:
identical()函数
identical(sqldf("select* from mtcars where am=1 and vs=1",row.names=TRUE),
+ subset(mtcars,am==1&vs==1)
+ )2)去掉不需要的列
subset(mtcars,am==1&vs==1,select=hp:wt)
3.1.1 快速去掉多余数据
library(hflights)
library(sqldf)
system.time(sqldf("SELECT * from hflights where Dest == 'BNA'",row.names=TRUE)) #计算时间
system.time(subset(hflights,Dest=='BNA'))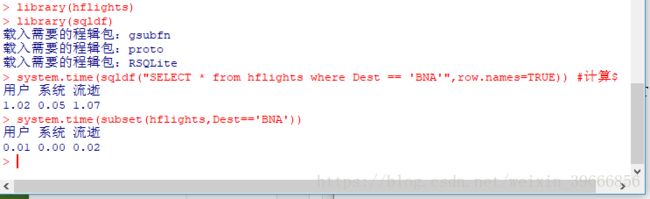
library(dplyr) #dplyr包可以处理
system.time(filter(hflights,Dest=='BNA'))
从效果上来看dplyr包可以更快的处理数据,但是不会保存行名称,需要先保存下来
mtcars$rownames<-rownames(mtcars)
select(filter(mtcars,hp>300),c(rownames,hp))3.1.2 快速去掉多余数据的其他方法
install.packages("data.table")
library(data.table)
hflights_dt<-data.table(hflights)
hflights_dt[,rownames:=rownames(hflights)]
system.time(hflights_dt[Dest=='BNA'])这里用到的是data.table包的方法,下面显示的是如何用data.table语法来选择列:
str(hflights_dt[Dest=='BNA',list(DepTime,ArrTime)])
3.2 聚集
1)利用stats包中的aggregate函数:通过分组变量将数据划分成不同的子集,并分别对这些子集进行统计汇总。
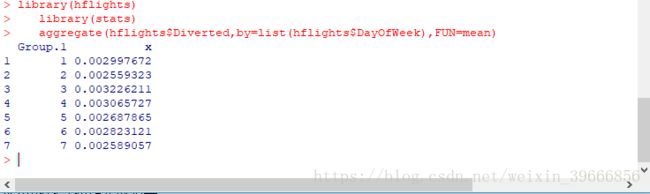
library(hflights)
library(stats)
aggregate(hflights$Diverted,by=list(hflights$DayOfWeek),FUN=mean) #利用dayofweek求航班延误的均值2) 另外一种实现上面结果的函数是with()函数
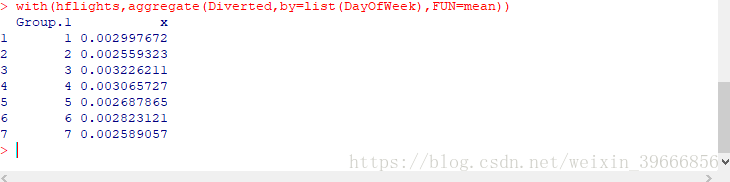
with(hflights,aggregate(Diverted,by=list(DayOfWeek),FUN=mean))
3.2.1 使用基础的R命令实现快速聚集
tapply(hflights$Diverted,hflights$DayOfWeek,mean)返回结果是一个array对象,然后将结果增加合适的列名转换为data.frame是可行的。

plyr包包含很多函数处理data.frame\list\array 类型的对象
函数名的第一个字符代表输入类型的类别,第二个字符代表输出格式,所有都以ply结尾
d(data.frame)s(array)l(list)m(以表格的方式为函数提供了多个参数)r(函数希望输入一个整数
以指明函数将要复制的次数,_是一种特殊的输出类型,此时函数将不返回任何结果)
ddply以data.frame为输入,返回也为data.frame
ldply以list为输入,返回data.frame
l_ply不返回任何结果
library(plyr)
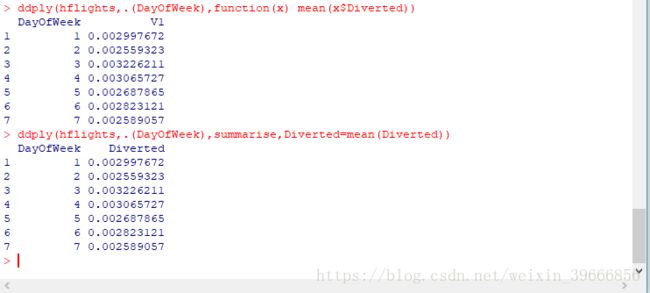
ddply(hflights,.(DayOfWeek),function(x) mean(x$Diverted))
修改上面输出结果的第二列的名称
3.2.4 使用data.table完成聚集
library(data.table)
hflights_dt<-data.table(hflights)
hflights_dt[,mean(Diverted),by=DayOfWeek]hflights_dt[,list('mean(Diverted)'=mean(Diverted),by=DayOfWeek)]3.3 汇总函数
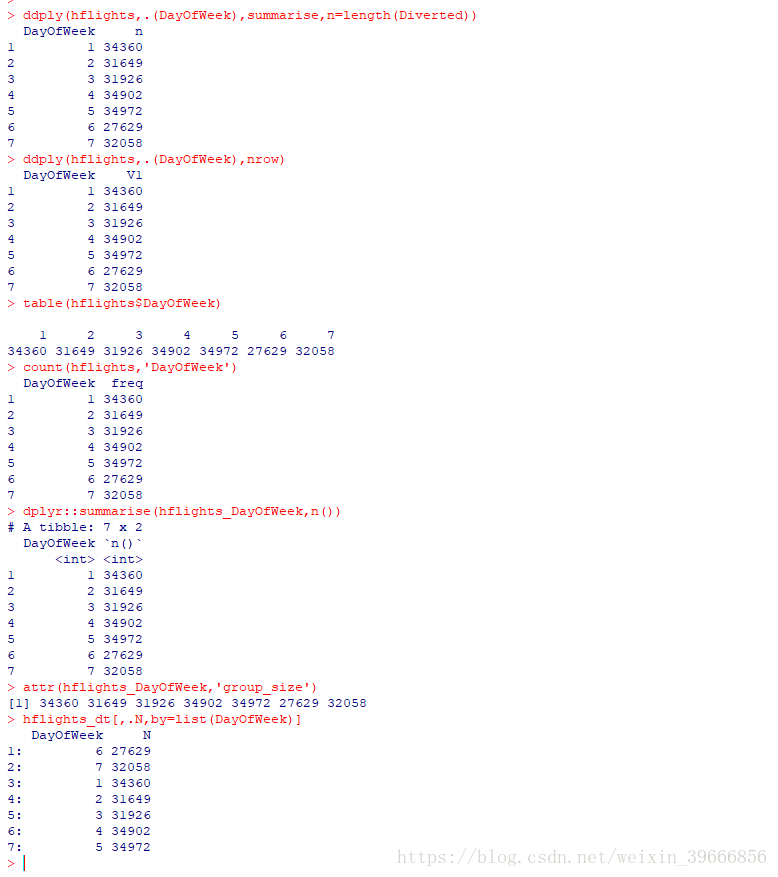
统计hflights数据集的分组样例数目
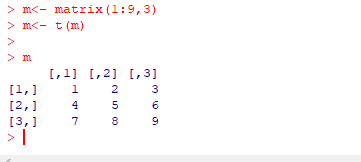
4.1 矩阵转置
4.2 基于字符串匹配实现数据筛选

#筛选以delay结尾的数据
library(dplyr)
library(hflights)
str(select(hflights,ends_with("delay",ignore.case=FALSE))) #也可以换成starts_with
str(select(hflights,contains("T",ignore.case=FALSE))) #ignore.case=FALSE 是否考虑大小写
str(select(hflights,matches("^[[:alpha:]]{5,6}$"))) #match 函数使用表达式作为参数,可以一次性
#处理所有列名的匹配检测
table(nchar(names(hflights))) #计算出数据的列名长度
names(select(hflights,-matches("^[[:alpha:]]{7,8}$"))) #去掉列名长度为7或8的列,显示处理后的列名4.3 数据重排序

自动导入的magrittr包提供的管道操作命令操作符调用上面三个表达式,将R对象作为其后R表达式的第一个参数
hflights %>% arrange(ActualElapsedTime) %>% str下面语句,找到除了austin以外,距离最近的机场
hflights %>%
arrange(ActualElapsedTime) %>%
select(ActualElapsedTime,Dest) %>%
subset(Dest !='AUS') %>%
head %>%
str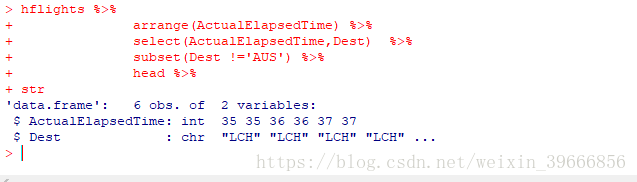
str(head(data.table(hflights,key='ActualElapsedTime')[Dest!='AUS',c('ActualElapsedTime','Dest'),with=FALSE])) #但是处理后的数据有缺失值
str(head(na.omit(data.table(hflights,key='ActualElapsedTime'))[Dest!='AUS',list(ActualElapsedTime,Dest)]))
比较一下上面两种方法system.time():

4.5 创建新变量

hflights_dt<-data.table(hflights)
hflights_dt[,DistanceKMs:=Distance/0.62137]
system.time(hflights_dt$DistanceKMs<-hflights_dt$Distance/0.62137)
system.time(hflights_dt[,DistanceKMs:=Distance/0.62137])使用pyyr包,我们可以更好地了解一些辅助函数对内存的使用过程:
library(pryr)
hflights_dt<-data.table(hflights)

第一种方法重新分配了地址,第二种没有分配新的地址,所以第二种速度要更快一些
4.5.2 同时创建多个变量
hflights_dt[,c('DistanceKMs','DistanceFeets'):=list(Distance/0.62137,Distance*5280)]
carriers<-unique(hflights_dt$UniqueCarrier)
hflights_dt[,paste('carrier',carriers,sep='_')
:=lapply(carriers,function(x) as.numeric(UniqueCarrier==x))]
str(hflights_dt[,grep('^carrier',names(hflights_dt)),with=FALSE])
library(dplyr)
hflignts<-hflights %>% mutate(DistanceKMs=Distance/0.62137) str(hflights)#和以下运行结果是一样的hflights<-mutate(hflights,DistanceKMs=Distance/0.62137)str(hflights)数据框溶解是指将表格数据根据给定标识变量转换为键-值对类型

library(reshape)
head(melt(hflights))
system.time(head(melt(hflights)))
library(reshape2)
system.time(head(melt(hflights)))
hflights_melted<-melt(hflights,id.vars=0,measure.vars=c('ActualElapsedTime','AirTime'))
str(hflights_melted)
library(ggplot2)
ggplot(hflights_melted,aes(x=variable,y=value))+geom_boxplot()