【YOLO学习】从YOLOv1开始的YOLO学习之路
从YOLOv1开始的YOLO学习之路
文章目录
- 从YOLOv1开始的YOLO学习之路
- 前言
- YOLO算法整体思路
- 核心思想
- 总结
- 网络结构学习
- 总结
- loss计算
- 位置损失
- 置信度损失
- NMS(非极大值抑制)
- 预测流程
- 优缺点
前言
YOLO是一个单阶段的检测算法,他就是把检测问题转化成回归问题,一个CNN就搞定了,同时也可以对视频进行实时检测,应用范围非常广。
YOLO算法整体思路
核心思想
要预测一张图像上的物体,比如要预测一个狗,那么我们要怎么去确定这个狗的位置?
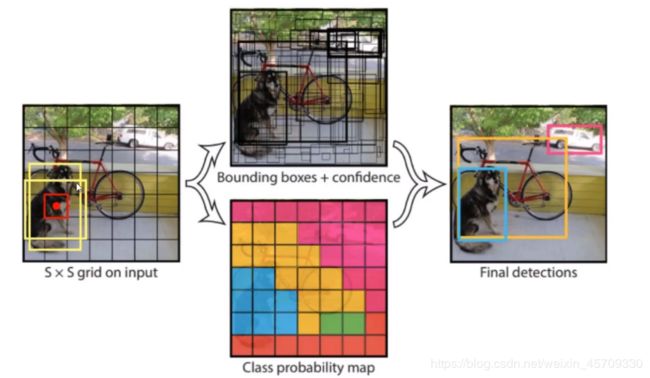
那么我们首先输入一张 S × S S\times S S×S的格子的图片(这里为了方便理解,就是把原本的像素点放大成一个又一个格子,在实际的结构当中就是判断像素点的)。那么yolo算法就会把些所有网格都会预测一下,然后确定代表的物体。
但是因为物体的位置比较多,单纯通过网络直接预测的准确率还不够。通过我们人为给定一些框,这些框(上图中的黄框)就是锚点(Anchor)。这些通过经验确定的框肯定是有一些误差,但可以给网络提供一个参考,所以yolo检测本质上就是通过训练之后对我们人为给定的框进行一个修正,对这些框的长和宽进行一个微调,到这里就变成了一个回归任务了,当相于就是找到一个最合适的长和宽,也就是**参数的求解和调整。**所以yolov1中就是先作出两个候选框,针对每一个格子都要去进行这么一个回归的求解。
根据之前学习过的IOU这个指标,我们可以先用候选框和实际框分别计算出对应每一个候选框的IOU,因为IOU越大代表越接近实际值。我们对每一个候选框计算IOU,然后就对IOU最大的那个框进行微调。
但这里就会出现一个问题,因为要对每一个位置进行预测,就会导致要对整个图像上每一个像素点进行计算,这样就会出现很多很多物体,但有些是背景,不是我们需要的物体,所以还需要预测一个置信度,我们需要过滤掉那些我们不需要的框,只有大于这个置信度的框才是真正预测到的物体。
通过这样的检测过程就可以算出我们需要的东西。
总结
在v1版本中,输入就是一个网格,针对网格里面每一个格子我们都会产生两个候选框,通过网络对候选框进行一个微调,因为有些只是背景,不是物体,所以我们不是对每一个候选框都进行微调,必须要有物体才行,所以每一个格子都需要预测一个置信度,置信度比较高的,大于这个阈值的,才是一个物体,只有是物体我们才对那个框进行微调,然后进行筛选,筛选IOU比较大,就是作为结果的,然后算出他们的 x , y , w , h x,y,w,h x,y,w,h映射到原始的图像就可以算出这个框了。
网络结构学习
在v1版本中,我们先输入一个 448 × 448 × 3 448\times448\times3 448×448×3的图像,是无法改变图像的大小的,只能是 448 × 448 × 3 448\times448\times3 448×448×3,因为卷积层对输入大小没有限制,任意大小的矩阵都可以进行卷积运算得到我们需要的特征,但全连接层是定死的,如果经过最后一层卷积层之后得到的是一个列为2048长度的一个矩阵,那么权重参数 W W W的大小就是 2048 × 1024 2048\times 1024 2048×1024,偏置参数的大小为 1024 1024 1024,这个权重参数是不能够一直在改变的(因为从最后的全连接之后得到的就是我们特征和类别),全连接层一定要固定特征图的大小
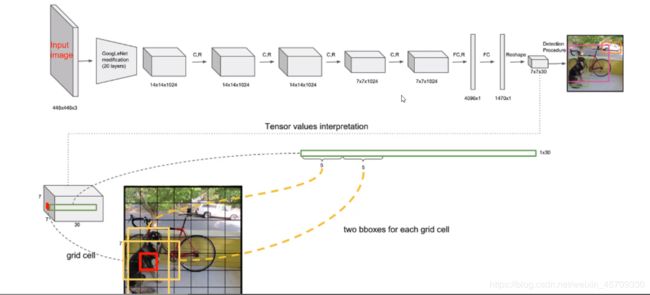
上图为v1的网络结构(主要看v2和v3的)
v1的全连接当中被转换成了 4096 × 1 4096\times 1 4096×1的向量,之后再经过全连接之后得到了一个 1470 × 1 1470\times 1 1470×1的一个向量,为了能够是我们能够获取里面的信息,我们reshape成 7 × 7 × 30 7\times7\times 30 7×7×30的一个张量,这个就是我们的图片经过神经网络之后得到的特征,也是至关重要的,下面我们看看这个里面是什么。
最后得到的 7 × 7 × 30 7\times7\times 30 7×7×30的一个张量, 7 × 7 7\times7 7×7代表了特征图的大小是 7 × 7 7\times7 7×7的,后面的 30 30 30表示 7 × 7 7\times7 7×7中每一个格子都有30个值,每一个点都有30个值。
那么对于每一个格子,要产生两种框,也就是两个锚点。那么这30个值的前10个值表示了
{ B 1 : x 1 , y 1 , w 1 , h 1 , C 1 B 2 : x 2 , y 2 , w 2 , h 2 , C 2 \begin{cases}B1: x_1,y_1,w_1,h_1,C_1\\ B2: x_2,y_2,w_2,h_2,C_2\end{cases} {B1:x1,y1,w1,h1,C1B2:x2,y2,w2,h2,C2
这10个值,不是表示方框在图像上的位置坐标,而是表示在归一化完之后在相对的一个长宽里面的值是多少。(可以理解为是一个相对坐标值)后面的 20 20 20就是一个 20 20 20分类,也就是后面剩下的值的数量就对应了你目前要检测的类别有几类(num_class)。这里的20代表了对应每一个类的一个概率,其实就是一个分类的问题。
- 为什么计算机能这样?因为我规定了一个loss函数,希望这个损失函数到什么程度是最小的,就会逐渐去迎合你的损失函数达到最小,逐渐就会猜到每个值代表了什么,满足你需求和期望,只要提供合适的损失值就能够预测出来。
总结
每个数字的含义
- 10 = ( X , Y , H , W , C ) × B 10 = (X,Y,H,W,C)\times B 10=(X,Y,H,W,C)×B(2个框(boundingbox(yolov1)))
- 当前数据集有 20 20 20个类别
- 7 × 7 7\times7 7×7表示最终网格的大小
- 预测结果: ( S × S ) × ( B × 5 + C ) (S\times S)\times(B\times5+C) (S×S)×(B×5+C)
YOLOv1的目的是为了更快的检测,而不是追求精度。
什么是归一化,为什么?为什么就代表了?
loss计算
算法要看网络结构和损失函数,由网络结构确定损失函数
由于预测和真实之间存在一些差距,所以我们要计算他们的误差,而且是对5个量都需要计算损失。
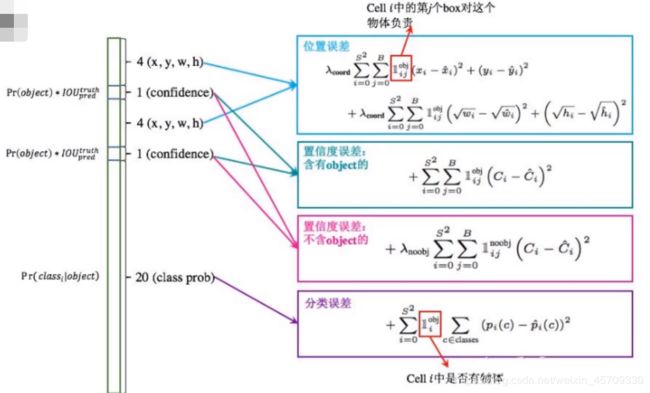
上图是总的损失函数计算。
位置损失
第一个框中的是位置误差:是用来计算 x , y , w , h x,y,w,h x,y,w,h这四个量的损失值,为了要找到他们变化率最小的地方,也就是损失最低的地方。
- 对于 w , h w,h w,h做根号的运算是因为,对于大物体来说,因为物体较大,所以真实框和预测框之间的(偏移程度)误差对其结果的影响不大。(因为物体较大,就算有偏差,由于物体大,所以对于精度影响比较小,依然能够识别出来)
- 但对于小物体来说,因为物体较小,稍微有一点偏差可能会导致很大的差距(真实框和预测框之间的误差)。所以,这就是一种对于值比较小的时候需要敏感,对于值比较大的时候可以不用很敏感的一个变化特点。,所以我们可以使用 y = x y=\sqrt{x} y=x这个函数的特点
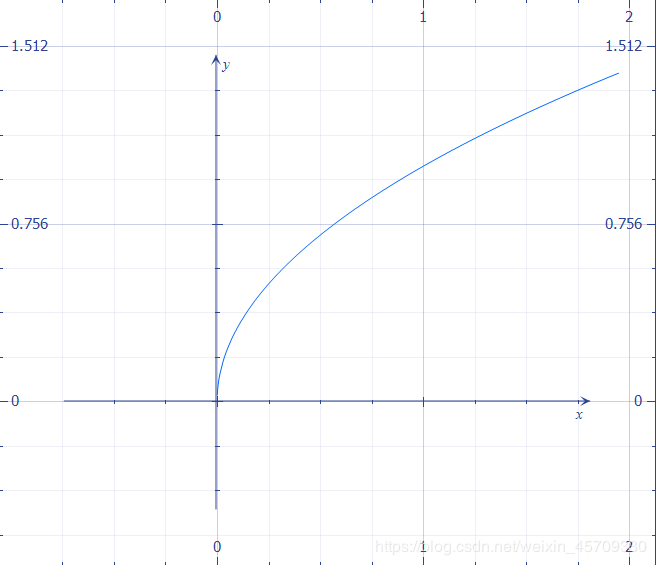
对于 x x x值比较小的时候, y y y的变化率比较大,对于 x x x比较大的时候 y y y的变化率比较小。
所以我们要注重 x x x比较小的时候的损失,也就是需要对小物体敏感,大物体粗糙也没关系。虽然不能控制物体的大小,但我们可以通过调整损失函数来达到相同的目的。
置信度损失
我们需要对置信度进行一个分类,因为图像中分前景和背景,但由于大部分都是背景。所以也要计算置信度损失。
第二个框中的是置信度误差(含有object的):是用来计算置信度 C C C的损失,也就是当前置信度和最大的IOU之间的差距,且是含有obj的。
第三个框中的是置信度误差(不含有object的):是用来计算置信度 C C C的损失,且是不含有obj的。计算时前面要加上一个权重系数,为了让损失函数更加注重前景,忽略背景,让背景占比较小的权重。
第四个框中的是分类误差:是计算每一个类中的误差
其中 S 2 S^2 S2表示在整个网格框中对每一个网格都要计算损失, B B B表示对于某一个格子都有两个boundingbox,也就是我们人为框定的候选框,这个损失函数就是为了对我们之前人为框定的候选框进行一个微调,但只会选其中一个进行微调(上面提到的先计算 I O U IOU IOU再进行对 I O U IOU IOU大的那个框进行微调)。在yolov1中只有两个锚点,所以也就只有 B 1 B_1 B1和 B 2 B_2 B2。 λ c o o r d \lambda_{coord} λcoord表示了一个权重系数,表示各部分占总部分的权重。
NMS(非极大值抑制)
我们通常在预测训练的时候会有很多个不同的概率框,如果有很多重合部分的框,那我们就挑选IOU比较大的作为极大值,我们就选择这个极大值的框。
预测流程
网络的输出是 S × S × 30 S×S×30 S×S×30 的数据块,首先用一个阈值选取含有目标的box,再用一个阈值筛选 c o n f i d e n c e × P ( c l a s s ) confidence×P(class) confidence×P(class),筛选后的框的 c x , c y cx,cy cx,cy从距离所在网格左上角的偏差解码为相对于图像左上角的距离,最后由NMS去除一些重叠的框。
NMS是大部分深度学习目标检测网络所需要的,大致算法流程为:
1.对所有预测框的置信度降序排序
2.选出置信度最高的预测框,确认其为正确预测(下次就没有他了,已经被确认了),并计算他与其他预测框的IOU
3.根据2中计算的IOU去除重叠度高的,IOU>threshold就删除
4.剩下的预测框返回第1步,直到没有剩下的为止
优缺点
优点:
- 速度快,可以实时检测
缺点:
- 重合的物体是很难检测的。
- 之前的人为选的Boundingbox比较少,每一个框只能识别一个类别,如果重叠就无法解决。
- 长款比单一,非常规的物体很难预测。
上一篇参数解释:https://blog.csdn.net/weixin_45709330/article/details/106771522
下一篇YOLOv2博客:https://blog.csdn.net/weixin_45709330/article/details/106851885