spark02(spark-shell使用,scala开发spark)
文章目录
- Spark角色介绍
- spark任务提交以及spark-shell使用
- 运行spark-shell --master local[N] 读取hdfs上面的文件
- 使用scala开发spark程序代码本地运行
Spark角色介绍
Spark是基于内存计算的大数据并行计算框架。因为其基于内存计算,比Hadoop中MapReduce计算框架具有更高的实时性,同时保证了高效容错性和可伸缩性。从2009年诞生于AMPLab到现在已经成为Apache顶级开源项目,并成功应用于商业集群中,学习Spark就需要了解其架构。
Spark架构图如下:
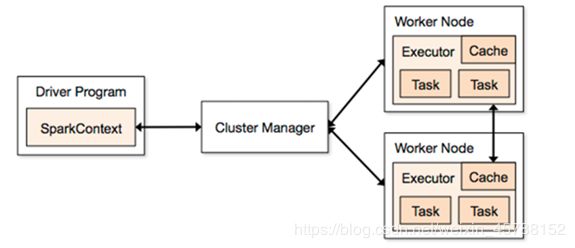
Spark架构使用了分布式计算中master-slave模型,master是集群中含有master进程的节点,slave是集群中含有worker进程的节点。
Driver Program :运⾏main函数并且新建SparkContext的程序。
Application:基于Spark的应用程序,包含了driver程序和集群上的executor。
Cluster Manager:指的是在集群上获取资源的外部服务。目前有三种类型
(1)Standalone: spark原生的资源管理,由Master负责资源的分配
(2)Apache Mesos:与hadoop MR兼容性良好的一种资源调度框架
(3)Hadoop Yarn: 主要是指Yarn中的ResourceManager
Worker Node: 集群中任何可以运行Application代码的节点,在Standalone模式中指的是通过slaves文件配置的Worker节点,在Spark on Yarn模式下就是NodeManager节点
Executor:是在一个worker node上为某应⽤启动的⼀个进程,该进程负责运⾏任务,并且负责将数据存在内存或者磁盘上。每个应⽤都有各自独立的executor。
Task :被送到某个executor上的工作单元。
spark任务提交以及spark-shell使用
spark任务提交说明
一旦打包好,就可以使用bin/spark-submit脚本启动应用了. 这个脚本负责设置spark使用的classpath和依赖,支持不同类型的集群管理器和发布模式:
bin/spark-submit \
--class <main-class>
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
一些常用选项:
–class: 你的应用的启动类 (如 org.apache.spark.examples.SparkPi)
- –master: 集群的master URL (如 spark://node01:7077)
- –deploy-mode: 是否发布你的驱动到worker节点(cluster) 或者作为一个本地客户端 (client) (default: client)*
- –conf: 任意的Spark配置属性, 格式key=value. 如果值包含空格,可以加引号“key=value”. 缺省的Spark配置
- application-jar: 打包好的应用jar,包含依赖. 这个URL在集群中全局可见。 比如hdfs:// 共享存储系统, 如果是 file:// path, 那么所有的节点的path都包含同样的jar.
- application-arguments: 传给main()方法的参数
Master URL 可以是以下格式:
查看Spark-submit全部参数:

更多参数提交说明:
–master MASTER_URL
可以是spark://host:port, mesos://host:port, yarn, yarn-cluster,yarn-client, local
–deploy-mode DEPLOY_MODE
Driver程序运行的地方,client或者cluster
–class CLASS_NAME
主类名称,含包名
–name NAME
Application名称
–jars JARS
Driver依赖的第三方jar包
–py-files PY_FILES
用逗号隔开的放置在Python应用程序PYTHONPATH上的.zip, .egg, .py文件列表
–files FILES
用逗号隔开的要放置在每个executor工作目录的文件列表
–properties-file FILE
设置应用程序属性的文件路径,默认是conf/spark-defaults.conf
–driver-memory MEM
Driver程序使用内存大小
–driver-java-options
–driver-library-path
Driver程序的库路径
–driver-class-path
Driver程序的类路径
–executor-memory MEM
executor内存大小,默认1G
–driver-cores NUM
Driver程序的使用CPU个数,仅限于Spark Alone模式
–supervise
失败后是否重启Driver,仅限于Spark Alone模式
–total-executor-cores NUM
executor使用的总核数,仅限于Spark Alone、Spark on Mesos模式
–executor-cores NUM
每个executor使用的内核数,默认为1,仅限于Spark on Yarn模式
–queue QUEUE_NAME
提交应用程序给哪个YARN的队列,默认是default队列,仅限于Spark on Yarn模式
–num-executors NUM
启动的executor数量,默认是2个,仅限于Spark on Yarn模式
–archives ARCHIVES
仅限于Spark on Yarn模式
启动Spark Shell
运行spark-shell --master local[N] 读取本地文件
单机模式:通过本地N个线程跑任务,只运行一个SparkSubmit进程。
创建本地文件,使用spark程序实现单词计数统计
第一步:准备本地文件
node01服务器执行以下命令准备数据文件
mkdir -p /export/servers/sparkdatas
cd /export/servers/sparkdatas/
vim wordcount.txt
hello me
hello you
hello her
第二步:通 --master启动本地模式
node01执行以下命令进入spark-shell
bin/spark-shell --master local[2]
第三步:开发scala单词统计代码
使用这种方式
sc.textFile("file:///export/servers/sparkdatas/wordcount.txt").flatMap(x => x.split(" ")).map(x => (x,1)).reduceByKey((x,y) => x + y).collect
或者使用以下这种方式,通过下划线来进行替代
sc.textFile("file:///export/servers/sparkdatas/wordcount.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _).collect
代码说明:
sc:Spark-Shell中已经默认将SparkContext类初始化为对象sc。用户代码如果需要用到,则直接应用sc即可。
textFile:读取数据文件
flatMap:对文件中的每一行数据进行压平切分,这里按照空格分隔。
map:对出现的每一个单词记为1(word,1)
reduceByKey:对相同的单词出现的次数进行累加
collect:触发任务执行,收集结果数据。
运行spark-shell --master local[N] 读取hdfs上面的文件
第一步:将我们的数据文件上传hdfs
cd /export/servers/sparkdatas
hdfs dfs -mkdir -p /sparkwordcount
hdfs dfs -put wordcount.txt /sparkwordcountss
第二步:开发spark的程序
sc.textFile("hdfs://node01:8020/sparkwordcount/wordcount.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _).collect
运行spark-shell --master spark://node01:7077
我们可以通过 –master spark://node01:7077来进行提交我们的spark程序到spark集群上面去运行
退出之前运行的spark-shell,然后重新进入spark-shell并且指定我们的spark的主节点地址
第一步:重新进入spark-shell
退出之前的本地spark-shell模式:quit,然后执行以下命令重新进入spark-shell客户端
bin/spark-shell --master spark://node01:7077,node02:7077 \
--executor-memory 1g \
--total-executor-cores 2
第二步:开发spark程序
开发我们的spark程序,读取hdfs上面的数据,进行wordcount单词统计
sc.textFile("hdfs://node01:8020/sparkwordcount/wordcount.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _).collect
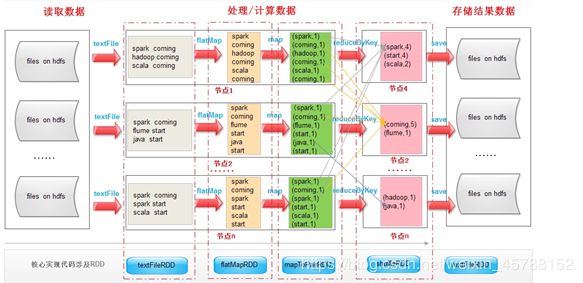
使用scala开发spark程序代码本地运行
第一步:创建maven工程并导入jar包
记得创建src/main/scala以及 src/test/scala文件夹
<properties>
<scala.version>2.11.8</scala.version>
<spark.version>2.2.0</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.5</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<!-- <verbal>true</verbal>-->
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass></mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
第二步:创建scala的object并开发scala代码
object SparkFirst {
def main(args: Array[String]): Unit = {
//定义我们的配置文件对象
val sparkConf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("sparkLocalCount")
//获取sparkContext对象,用于操作我们的数据
val sparkContext = new SparkContext(sparkConf)
//设置日志级别,避免打印太多日志
sparkContext.setLogLevel("WARN")
//读取本地文件
val file: RDD[String] = sparkContext.textFile("file:///F:\\scala与spark课件资料教案\\3、spark课程\\1、spark第一天\\wordcount\\wordcount.txt")
//每一行文件进行拆分
val flatMap: RDD[String] = file.flatMap( x => x.split(" "))
//拆分出来的每个单词记做1
val map: RDD[(String, Int)] = flatMap.map(x => (x,1))
//按照我们的单词进行划分,相同的单词划分到一起去
val key: RDD[(String, Int)] = map.reduceByKey((x,y) => x)
//按照单词出现的次数进行排序,false表示降序,默认是升序
val by: RDD[(String, Int)] = key.sortBy(x => x._2,false)
//调用collect收集我们的结果,然后通过println打印出来
val collect: Array[(String, Int)] = by.collect()
println(collect.toBuffer)
//将我们最终的结果保存到文件里面去
key.saveAsTextFile("file:///F:\\scala与spark课件资料教案\\3、spark课程\\1、spark第一天\\wordcount\\output2\\result.txt")
//关闭sparkContext
sparkContext.stop()
}
}
第三步:通过main方法本地运行
直接右键通过main方法进行本地运行
第四步:更改代码打包提交到spark集群运行
改造代码
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//设置spark的配置文件信息
// val sparkConf: SparkConf = new SparkConf().setAppName("WordCount").setMaster("local[2]")
val sparkConf: SparkConf = new SparkConf().setAppName("WordCount")
//构建sparkcontext上下文对象,它是程序的入口,所有计算的源头
val sc: SparkContext = new SparkContext(sparkConf)
//读取文件
//val file: RDD[String] = sc.textFile("file:///F:\\scala与spark课件资料教案\\spark课程\\1、spark第一天\\wordcount\\wordcount.txt")
val file: RDD[String] = sc.textFile(args(0))
//对文件中每一行单词进行压平切分
val words: RDD[String] = file.flatMap(_.split(" "))
//对每一个单词计数为1 转化为(单词,1)
val wordAndOne: RDD[(String, Int)] = words.map(x=>(x,1))
//相同的单词进行汇总 前一个下划线表示累加数据,后一个下划线表示新数据
val result: RDD[(String, Int)] = wordAndOne.reduceByKey(_+_)
//保存数据到HDFS
// result.saveAsTextFile("file:///F:\\scala与spark课件资料教案\\spark课程\\1、spark第一天\\wordcount\\wordcount")
result.saveAsTextFile(args(1))
sc.stop()
}
}
第五步:打包上传到linux集群
第六步:运行spark的jar包程序
通过spark-submit脚本来提交我们开发的jar包
bin/spark-submit \
--class cn.itcast.spark.wordcount.WordCount \
--master spark://node01:7077 \
--executor-memory 1g \
--total-executor-cores 2 \
/export/servers/original-day01-1.0-SNAPSHOT.jar \
hdfs://node01:8020/sparkwordcount/wordcount.txt \
hdfs://node01:8020/sparkwordcount_out