AWS学习笔记——Chapter8 Databases on AWS
前注:
学习书籍
由于是全英文书籍,所以笔记记录大部分为英文。
Index
- Databases on AWS
- 1. Understanding the Amazon Relational Database Service
- (1) 7 RDBMS engines
- (2) Scenario 1: Hosting the database in your data center on-premises
- (3) Scenario 2: Hosting the database on Amazon EC2 Servers
- (4) Scenario 3: Hosting the database using Amazon RDS
- (5) Benefits by running your database on RDS
- 2. Hosting a Database in Amazon EC2 vs Amazon RDS
- (1) You should choose RDS if
- (2) You should choose EC2 if
- 3. High Availability on Amazon RDS
- (1) Simplest Architecture: Single-AZ Deployment
- (2) High Availability: Multiple AZs
- 4. Scaling on Amazon RDS
- (1) Changing the instance type
- (2) Read Replica
- 5. Security on Amazon RDS
- (1) Amazon VPC and Amazon RDS
- (2) Data Encryption on Amazon RDS
- 6. Backups, Restores and Snapshots
- 7. Monitoring
- (1) Standard monitoring
- (2) Enhanced monitoring
- (3) Event notification
- (4) Performance Insights
- 8. Amazon Aurora
- 9. Amazon RedShift
- (1) Benefits
- (2) Architecture
- (3) Sizing Amazon RedShift Clusters
- (4) Networking for Amazon RedShift
- (5) Encryption
- (6) Security
- (7) Backup and Restore
- (8) Data Loading in Amazon Redshift
- (9) Data Distribution in Amazon RedShift
- 10.Amazon DynamoDB
- (1) Common Use Cases
- (2) Benefits
- (3) Amazon DynamoDB Terminology
- (4) Global Secondary Index
- (5) Consistency Model
- (6) Global Table
- (7) Amazon DynamoDB Streams
- (8) Amazon DynamoDB Accelerator
- (9) Encryption and Security
- 11.Amazon ElastiCache
Databases on AWS
1. Understanding the Amazon Relational Database Service
(1) 7 RDBMS engines
Aurora MySQL, Aurora PostgreSQL, Oracle, SQL Server, MySQL, PostgreSQL, MariaDB
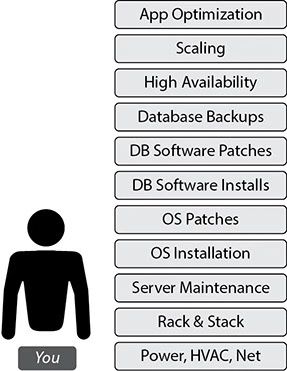
(2) Scenario 1: Hosting the database in your data center on-premises
Take care of everything
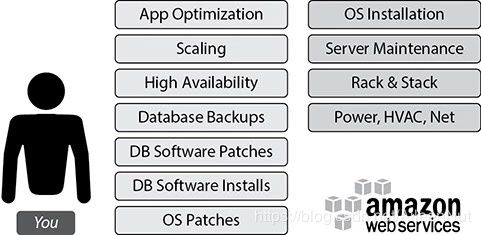
(3) Scenario 2: Hosting the database on Amazon EC2 Servers
You take care of the stuff on the left, AWS takes care of the stuff on the right.
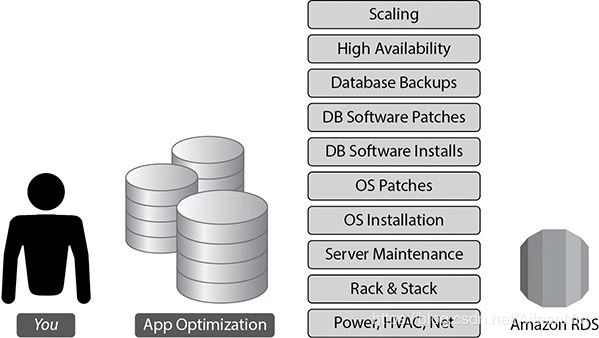
(4) Scenario 3: Hosting the database using Amazon RDS
You just need to focus on application optimization.
(5) Benefits by running your database on RDS
· No infrastructure management
· Instant provisioning
· Scaling
· Cost effective
· Application compatibility
· Highly available
· Security
2. Hosting a Database in Amazon EC2 vs Amazon RDS
RDS is a managed service. It takes a lot of burden off your hands, but you also don’t get access to the database host operating system, you have limited ability to modify the configuration that is normally managed on the host operating system, and generally you get no access to functions that rely on the configuration from the host operating system.
All of your storage on RDS is also managed. There are storage limits of 16TB with MySQL, SQL server, Maria DB, PostgreSQL and Oracle, and 64TB with Aurora.
(1) You should choose RDS if
· You want to focus on tasks that bring value to your business
· You don’t want to manage the database
· You want to focus on high-level tuning tasks and schema optimization
· You lack in-house expertise to manage databases
· You want push-button multi-AZ replication
· You want automated backup and recovery
(2) You should choose EC2 if
· You need full control over the database instances
· You need operating system access
· You need full control over backups, replication and clustering
· Your RDBMS engine features and options are not available in Amazon RDS
· You size and performance needs exceed the Amazon RDS offering
3. High Availability on Amazon RDS
Amazon RDS supports high availability (HA) architectures.
(1) Simplest Architecture: Single-AZ Deployment
The scenarios may live with downtime: some sort of proof of concept, deploy development environments, or deploy noncritical nonproduction environments.
Launch the Amazon RDS instance in a single AZ, with this you get a single RDS instance inside a VPC with the necessary attached storage.
(2) High Availability: Multiple AZs
The scenarios that must deploy the database in a multi-AZ architecture: run a mission-critical database, want to have an architecture where you can’t afford to lose data, have a tight recovery point objective, or can’t afford much downtime.
In a multi-AZ architecture, you can choose which AZ you want your primary database instance (/master database instance) to be in.
RDS will then choose to have a standby instance and storage in another AZ of the AWS region that you are operating in.
The standby instance will be of the same type, the same configuration and size as your primary instance.
The master database handles all the traffic, the standby database doesn’t remain open when it acts as a standby database, so you can’t direct the traffic to the primary and standby databases at the same time.
In the multi-AZ architecture, the application connects to the database server using a DNS endpoint that is mapped to the master and standby instances, so you don’t have to repoint or change anything from the application side.
4. Scaling on Amazon RDS
(1) Changing the instance type
The simplest way to scale up or down is to change the instance type.
You can change from one class of instance to another class of move up and down between the same classes of instance.
Apply the change immediately: could be some downtime since it is changed.
Don’t apply the change immediately: the change will be scheduled to occur during the preferred maintenance window.
RDS is not integrated with Auto Scaling, but you can achieve this by writing a Lambda function. You can also automate the scale-up of the instance based on certain events (may be using a combination of Lambda, CloudWatch and SNS).
(2) Read Replica
A read replica is a read-only of your master database that is kept in sync with your master database.
You can have up to 15 read replicas in RDS depending on the RDBMS engine.
Benefits:
· Can offload read-only traffic to the read replica and let the master database run critical transaction-related queries.
· If you have users from different locations, you can create a read replica in a different region and serve the read-only traffic via the read replica.
· The read replica can also be promoted to a master database when the master database
goes down.
Configuration:
· Master-standby configuration
The replication of data is always synchronous, no data loss when the standby is promoted to master.
· Master and read replica configuration
The replication is asynchronous, could be some data loss when a read replica is promoted to master.
· Master, standby and read replica configuration
The cases that you can’t afford data loss and need read replicas.
Regions:
· An intra-region allows you to create additional read replicas within the same AWS region, but in the same or different availability zones from your master database. Supported by MySQL, MariaDB, PostgreSQL, Aurora MySQL and Aurora PostgreSQL.
· Cross-regional replication allows you to deploy the read replica into an AWS region that is different from the region that your master is located in. Supported by MySQL, MariaDB, PostgreSQL, Aurora MySQL and Aurora PostgreSQL.
Notes:
CurrentlybRDS doesn’t support read replicas for Oracle and SQL Server. You can achieve this by using Oracle Golden Gate or some of the AWS partner products such as Attunity and SnapLogic to replicate data between two RDS instances of Oracle or SQL Server.
5. Security on Amazon RDS
(1) Amazon VPC and Amazon RDS
It is recommended that you create the database in the private subnet.
Multiple ways of connecting the database runs in VPC:
· Create a VPN connection from your corporate data center into the VPC.
· Use Direct Connect to link your data center to an AWS region.
· Peer two different VPCs together, allowing applications in one VPC to access your database in your VPC.
· Grant public access to your database by attaching an Internet Gateway to your VPC.
· Use route table that you attach to each of the subnets in your VPC to control the routing of your VPC.
Can create security groups within RDS and control the flow of traffic.
This gives you the flexibility to have a multitier architecture where you grant connections only from the parts of the tier that actually need to access the database.
(2) Data Encryption on Amazon RDS
RDS provides the ability to encrypt the data at rest.
RDS-encrypted instances provide an additional layer of data protection by securing your data from unauthorized access to the underlying storage.
AWS-provided encryption will encrypt the following:
· The database instance storage
· Automated backups
· Read replicas associated with the master database
· Standby databases associated with the master database
· Snapshots that you generate of the database
You can also use Oracle or SQL Server’s native encryption like Transparent Database Encryption (TDE) in RDS, but you should use only one mode of encryption (either RDS or TDE).
When you create an RDS instance and enable encryption, a default key for RDS is created in the Key Management Service (KMS) that will be used to encrypt and decrypt the data in your RDS instance.
KMS is a managed service that provides you with the ability to create and manage encryption keys and then encrypt and decrypt your data with those keys.
You can also use your own key for managing the encryption. If you create your own master key within KMS and then reference that key while creating your RDS instance, you have much more control over the use of that key such as when it is enabled or disabled, when the key is rotated and what the access policies are for the key.
A two-tiered key hierarchy using encryption:
· The unique data key encrypts customer data inside the RDS
· The AWS KMS master keys encrypt data keys
You get centralized access and audit of key activity via CloudTrail so that you can see every time a key is accessed and used from your KMS configuration.
Using RDS you can encrypt the traffic to and from your database using SSL. This takes care of encrypting the data in transit.
Notes from the examination’s point of view:
· You can encrypt only during database creation. If you already have a database that is up and running and you want to enable encryption on it, the only way to achieve this is to create a new encrypted database and copy the data from the existing database to the new one.
· Once you encrypt a database, you can’t remove it. If you choose to encrypt an RDS instance, it cannot be turned off. If you no longer need the encryption, you need to create a new database instance that does not have encryption enabled and copy the data to the new database.
· The master and read replicas must be encrypted. When you create a read replica, using RDS, the data in the master and read replicas is going to be encrypted. The data needs to be encrypted with the same key. Similarly, when you have a master and standby configuration, both are going to be encrypted.
· You cannot copy those snapshots of an encrypted database to another AWS region, as you can do with normal snapshots. KMS is a regional service, so you currently cannot copy things encrypted with KMS to another region.
· You can migrate an encrypted database from MySQL to Aurora MySQL.
6. Backups, Restores and Snapshots
For all the Amazon RDS engines, except Amazon Aurora (MySQL and PostgreSQL), MySQL, PostgreSQL, MariaDB, Oracle and SQL Server, the database backup is scheduled for every day.
The backup includes the entire database, transaction logs and change logs.
By default, the backup are retained for 35 days, which can be extended by a support ticket.
In the case of Aurora, everything is automatically backed up continuously to the S3 bucket, but you can also take a manual backup.
When you restore a database from the backup, you create a new exact copy of the database or a clone of a database, and you have the ability to restore the database to any class of server, and it doesn’t have to be the same type of instance where the main database is running.
Creating a snapshot is another way of backing up your database.
Snapshots are not automatically scheduled, you need to take is manually.
Whennyou take the snapshot of a database, there is a temporary I/O suspension that can last from a few seconds to a few minutes.
The snapshots are created in S3 and can be used to restore a database.
Ifnyou use the snapshot of an encrypted database to restore, the resulting database will also be an encrypted database.
Cases for using snapshots:
· Use a snapshot to create multiple nonproduction databases from the snapshot of the production database to test a bug
· Copy the database across multiple accounts
· Create a disaster recovery database
· Keep the data before you delete the database
7. Monitoring
RDS sends all the metrics information to Amazon CloudWatch.
(1) Standard monitoring
Can access 15 to 18 metrics depending on the RDBMS engine.
Get metrics at one-minute intervals.
Common metrics are CPU utilization, storage, memory, swap usage, database connections, I/O (read and write), latency (read and write), throughput (read and write), replica lag and so on.
(2) Enhanced monitoring
Use for fine granular metrics. Can access additional 37 more metrics in addition to standard monitoring, making a total of more than 50 metrics.
Get metrics as low as a one-second interval.
(3) Event notification
Get notifications via SNS when certain events occur in RDS.
17 different categories of events including: availability, backup, configuration change, creation, deletion, failure, failover, maintenance, recovery, restoration…
(4) Performance Insights
Expand on existing Amazon RDS monitoring features to illustrate your database’s performance and helps you analyze any issues that impact it.
You can visualize the database load and filter the load by waits, SQL statements, hosts or users.
Performance Insights is on by default for the Postgres-compatible edition of Aurora database engine.
If you have more than one database on the database instance, performance data for all of the database is aggregated for the database instance.
Database performance data is kept for 35 days.
By default, the Performance Insights dashboard shows data for the last 15 minutes, but can be modified for the last 60 minutes.
8. Amazon Aurora
Amazon Aurora is a cloud-optimized, MySQL- and PostgreSQL-compatible, relational database.
For the code, applications, drivers and tools you already use with your MySQL or PostgreSQL databases can be used with Amazon Aurora with little or no change.
The storage of Aurora is a bit different compared to regular RDS. There is a separate storage layer that is automatically replicated across 6 different storage nodes in 3 different AZs.
All the data mirroring happens synchronously, there is no data loss.
All the data is also continuously backed up to S3 to ensure durability and availability.
Aurora supports up to 15 copies of read replica and the data replication happens at the storage level in a synchronous manner.
In Aurora, there is no concept of standby database, and the read replica is promoted to a master or primary database node when it goes down.
9. Amazon RedShift
A managed data warehouse solution.
A data warehouse is a database designed to enable business intelligence activities, used for query and analysis rather than for transaction processing. It usually contains historical data derived from transaction data but can include data from other sources.
Data warehouses are also known as online analytical processing (OLAP) system.
The data for a data warehouse system can come from various sources, such as online transaction processing (OLTP) systems, enterprise resource planning (ERP) systems such as SAP, internally developed systems, purchased applications, third-party data syndicators and more.
(1) Benefits
· Fast
· Cheap
· Good compression
· Managed service
· Scalable
· Secure
· Zone map functionality: minimize unnecessary IO
(2) Architecture
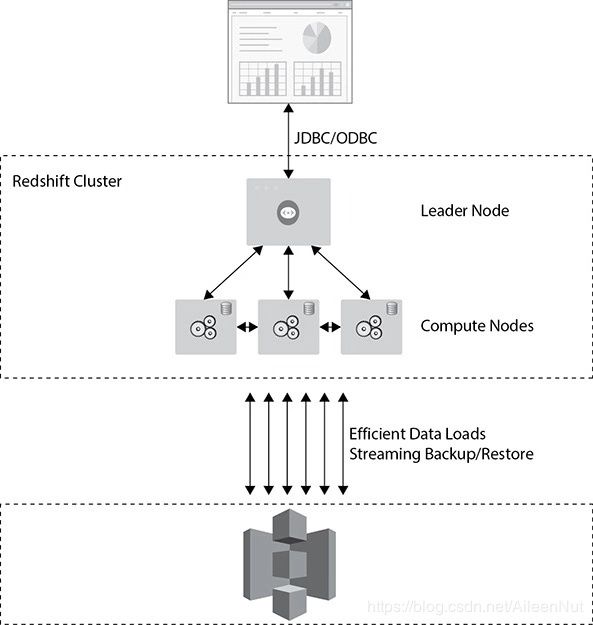
· Types of nodes
An Amazon Redshift cluster consists of a leader node and compute nodes. In a cluster, there is only one leader node, but could be serval compute nodes.
The leader node performs a few roles.
The leader node acts as a SQL endpoint for the applications and performs database functions and coordinates the parallel SQL processing.
All the Postgres catalog tables and some additional metadata tables specific to RedShift also exist in the leader node. (RedShift is built on Postgres)
You can use JDBC and ODBC to connect to your driver through leader node.
You can have up to 128 compute nodes.
The leader node communicates with the compute nodes for processing any query. The compute nodes also communicate with each other while processing a query.
The leader node does the database functions, such as encrypting the data, compressing the data, running the routing jobs like vacuum, backing up, restoring and so on.
All the compute nodes are connected via a high-speed interconnected network. The end client (application) can’t communicate with the compute directly.
The compute node can talk with services such as S3. The data is ingested directly from the S3 to the compute nodes, and Amazon constantly backs up the cluster to S3.
A compute node is further divided or partitioned into multiple slices. A slice is allocated a portion of a node’s CPU, memory and storage.
When the leader node distributes the job, it actually distributes it to the slices, and each slice processes the job independently.
· Types of clusters
Single-node clusters
There is only one node that performs the tasks of both the leader and compute nodes.
If the node goes down, everything goes down, and you need to restore the cluster from the snapshot.
It can be used for test/development environments.
Multi-node clusters
The leader node is separate from the compute node.
Only one leader node per cluster, you can specify the number of compute nodes you need.
The data is automatically replicated among the compute nodes for data redundancy.
When a compute node fails, it is replaced automatically and the cluster automatically take cares of redistributing the data.
It should be used for running production workloads.
· Types of instance in the clusters
RedShift uses an EC2 instance for both the cluster types.
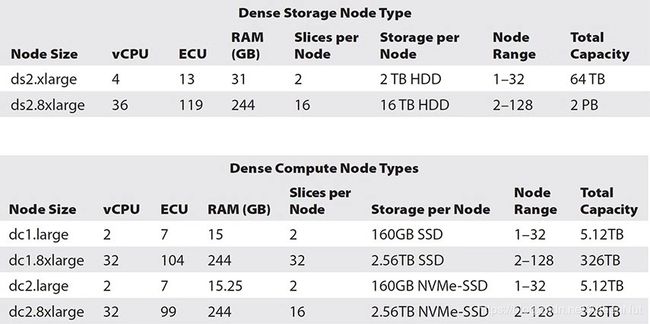
Dense compute (DC)
A dense compute has the SSD drives.
Used for faster performance and compute.
Dense Storage (DS)
A dense storage has the magnetic hard drives.
Used for a large workload and would like to use a magnetic hard drive.
(3) Sizing Amazon RedShift Clusters
First you need to decide what type of cluster you need, dense storage or dense compute.
Then you need to decide how much data you have, including the predicted data growth. You may also want to consider compression. On average, customers get about a three to four times compression ratio.
You don’t have to account for additional storage for mirroring, since the data mirroring is already included.
(4) Networking for Amazon RedShift
When you launch a RedShift cluster, either the EC2-VPC platform is available or the EC-classic platform is available.
A VPC is mandatory for all new cluster installations, and by using a VPC, the cluster remains isolated from other customers.
When you choose it in the public subnet, you can either provide your own public IP address (which is EIP) or have the RedShift cluster provide an EIP for you.
When you run it in a private subnet, it is not accessible from the Internet.
The public or private subnet is applicable only for the leader node. The compute node is created in a separate VPC, and you don’t have any access to it.
Enhanced VPC routing:
Choose it, all the traffic for commands such as COPY unload between your cluster and your data repositories are routed through your Amazon VPC.
Don’t choose it, RedShift routes traffic through the Internet, including traffic to other services within the AWS network.
(5) Encryption
Encryption is not mandatory.
When you launch the cluster with the encryption option, it is immutable.
For data in transit, you can use SSL to encrypt the connection between a client and the cluster.
For data at rest, RedShift uses AES-256 hardware-accelerated encryption keys to encrypt the data blocks and system metadata for the cluster.
You can manage the encryption using the AWS KMS, using the AWS CloudHSM, or using your on-premise HSM.
If the RedShift cluster is encrypted, all the snapshots will also be encrypted.
All RedShift cluster communications are secured by default. RedShift always uses SSL to access other AWS services (S3, DynamoDB, EMR for data load).
(6) Security
For RedShift, you need to create database users who will have superuser or user permissions with them.
To use the RedShift service, you can create IAM policies on IAM users, roles or groups.
(7) Backup and Restore
Amazon RedShift takes automatic backups in the form of snapshots of your cluster and saves them to Amazon S3.
The frequency of the snapshot is eight hours or 5GB of block changes.
In addition, you can configure cross-region snapshots, and by doing so, the snapshots can be automatically replicated to an alternate region.
If you want to restore the RedShift cluster to a different region, the quickest way would be to enable a cross-region snapshot and restore the cluster from the snapshot.
When you restore the entire database from a snapshot, it results in a new cluster of the original size and instance type.
During the restore, your cluster is provisioned in about ten minutes.
Data is automatically streamed from the S3 snapshot.
You can also do a table-level restore from a snapshot.
(8) Data Loading in Amazon Redshift
· File-based loading
Load CSV, JSON and AVRO files data directly from S3.
· Use Kinesis Firehouse
Load streaming data or batch data directly to RedShift.
· Via leader node or compute nodes
You can load the data via the leader node or directly from the compute nodes.
If you are going to insert the data, insert multiple values, update the data or delete the data, you can do it by using a client from the leader node.
If you run CTAS (create table as select), you can run it from the compute node. The compute node also supports loading the data from DynamoDB, from EMR and via SSH commands.
· COPY command
The COPY command is the recommended method to load data into Amazon RedShift since it can be used to load the data in bulk. It appends new data to existing rows in the table.
The mandatory parameters are table names, data source and credentials. Other parameters you can specify are compression, encryption, transformation, error handling, data format and so on.
While loading the data using the COPY command, since each slice in the cluster loads one file at a time, you should use multiple input files to maximize throughput and load data in parallel.
· UPLOAD command
Itnis the reverse of COPY. It exports the data out of the RedShift cluster.
It can write output only to S3.
It can run in parallel on all compute nodes.
It can generate more than one file per slice for all compute nodes.
The UNLOAD command supports encryption and compression.
· VACUUM command
Run the VACUUM command whenever you load the data in the RedShift cluster using the COPY command to reorganize the data and reclaim the space after the deletion.
· ANALYZE command
Run the ANALYZE command whenever you’ve made a nontrivial number of changes to your data to ensure your table statistics are current.
(9) Data Distribution in Amazon RedShift
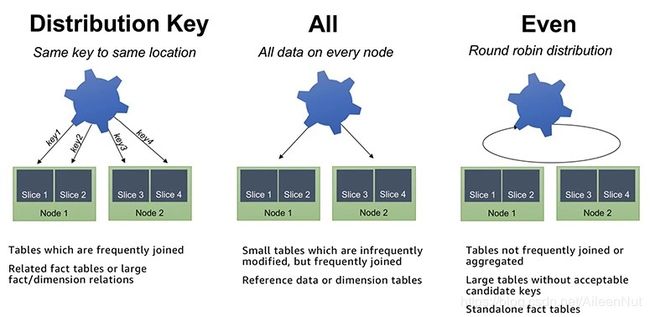
In RedShift, you have three options to distribute data among the nodes in your cluster: EVEN, KEY and ALL.
· KEY
The slice is chosen based on a distribution key that is a hash of the defined column.
· ALL
Distribute a copy of the entire table to the first slice on each node.
The ALL distribution helps to optimize joins, but it increases the amount of storage, which means the operations such as LOAD, UPDATE, and INSERT can run slower than other distribution styles.
It is good for smaller dimension tables that are frequently joined with large fact tables in the center of your star schemas and for tables that you don’t need to update frequently.
· EVEN
Data is evenly distributed across all slices using a round-robin distribution.
Use it when there is no clear choice between the KEY and ALL styles.
It is also recommended for small dimension tables, tables without JOIN or GROUP BY clauses and tables that are not used in aggregate queries.
When you create a table, you can define one or more of its columns as sort keys. Information about sort key columns is passed to the query planner, and the planner uses the information to construct plans that exploit the way the data is stored. It is implemented via zone maps, stored in each block header. It increases the performance of MERGE JOIN because of a much faster sort.
10.Amazon DynamoDB
A fully managed NoSQL database service.
Average service-side latencies are typically in single-digit milliseconds.
Amazon DynamoDB supports both document and key-value data structures.
A document store provides support for storing, querying and updating items in a document format such as JSON, XML and HTML.
A key-value store provides support for storing, querying and updating collections of objects that are identified using a key and values that contain the actual content being stored.
To use DynamoDB, you simply create a database table, set your throughput and let the service handle the rest.
If you throughput requirements change, simply update your table’s request capacity using the AWS Management Console or the Amazon DynamoDB APIs. Amazon DynamoDB manages all the scaling behind the scenes, and you are still able to achieve your prior throughput levels while scaling is underway.
(1) Common Use Cases
· Advertising for capturing browser cookie state
· Mobile applications for storing application data and session state
· Gaming applications for storing user preferences and application state and for storing players’ game state
· Consumer “voting” applications for reality TV contests
· Super Bowl commercials
· Large-scale websites for keeping session state or for personalization or access control
· Application monitoring for storing application log and event data or JSON data
· IoT devices for storing sensor data and log ingestion
(2) Benefits
· Scalable
Integrate with Auto Scaling.
Amazon takes care of scaling up or down as per throughput consumption monitored via CloudWatch alarms.
Auto Scaling take cares of increasing or decreasing the throughput as per the application behavior.
· Managed service
Amazon take cares of all the heavy lifting behind the scenes such as hardware or software provisioning, software patching, firmware updates, database management or partitioning data over multiple instances as you scale.
DynamoDB provides point-in-time recovery, backup and restore for all your tables.
· Fast, consistent performance
Use SSD technologies, the average service-side latencies are typically in single-digit milliseconds.
· Fine-grained access control
Integrate with IAM, provide fine-grained access control.
· Cost-effective
· Integration with other AWS services
Integrate with AWS Lambda, can create triggers.
(3) Amazon DynamoDB Terminology
A DynamoDB table consists of items just like a table in a relational database is a collection of rows.
Each table can have infinite number of data items.
An item is composed of a primary key that uniquely identifies it and key-value pairs called attributes.
Amazon DynamoDB is schemaless, in that the data items in a table need not have the same attributes or even the same number of attributes. (DynamoDB是无模式的,表中的数据项不必具有相同的属性,甚至不必具有相同数量的属性。)
Each table must have a primary key. The primary key can be a single attribute key or a “composite” attribute key that combines two attributes.
Each item in the table can be expressed as a tuple containing an arbitrary (任意) number of elements, up to a maximum size of 400KB.
Tables and items are created, updated and deleted through the DynamoDB API. Manipulation of data in DynamoDB is done programmatically through object-oriented code.
DynamoDB supports four scalar data type: Number, String, Binary and Boolean; supports these collection data types: Number Set, String Set, Binary Set, heterogeneous List and heterogeneous Map. It also supports NULL values.
DynamoDB supports two different kinds of primary keys:
· Partition key (分区键)
由一个名为partition key属性构成的简单主键(simple primary key)。
DynamoDB使用分区键的值作为内部散列函数的输入。来自散列函数的输出决定了item将存储到的分区(DynamoDB内部的物理存储)。
在只有分区键的表中,任何两个item都不能有相同的分区键值。
· Partition key and sort key (分区键和排序键)
也称复合主键(composite primary key),其由两个属性组成,一个是分区键,一个是排序键。
DynamoDB使用分区键的值作为内部散列函数的输入。来自散列函数的输出决定了item将存储到的分区。具有相同分区键值的所有item按排序键值的排序顺序存储在一起。
在具有分区键和排序键的表中,两个item可能具有相同的分区键值,但其排序键值必须不同。
分区键也被称为哈希属性(hash attribute),该词源自DynamoDB中使用的内部哈希函数,以基于data item的分区键值实现跨多个分区的item平均分布。
排序键也被称为范围属性(range attribute),该词源自DynamoDB存储item的方式,它按照排序键值有序地将具有相同分区键的item存储在相互紧邻的物理位置。
每个主键属性必须为标量 (表示它只能具有一个值)。主键属性唯一允许的数据类型是字符串、数字和二进制。对于其他非键属性没有任何此类限制。
During the table creation, you need to provide the table’s desired read and write capacity. DynamoDB configures the table’s partition based on the information.
A unit of write capacity enables you to perform one write per second for items of up to 1KB in size.
A unit of read capacity enables you to perform one strongly consistent read per second (or two eventually consistent reads per second) of items up to 4KB in size.
Units of capacity required for writes = Number of item writes per second × Item size in 1KB blocks
Units of capacity required for reads = Number of item reads per second × Item size in 4KB blocks
(4) Global Secondary Index
Global secondary indexes are indexes that contain a partition or partition-sort keys that can be different from the table’s primary key.
Amazon DynamoDB supports two types of secondary indexes:
· A local secondary index
An index that has the same partition key as the table but a different sort key.
A local secondary index is “local” in the sense that every partition of a local secondary index is scoped to a table partition that has the same partition key.
· A global secondary index
An index with a partition or a partition-sort key that can be different from those on the table.
A global secondary index is considered global because queries on the index can span all items in a table, across all partitions.
(5) Consistency Model
DynamoDB stores three geographically distributed replicas of each table to enable high availability
and data durability.
Read consistency represents the manner and timing in which the successful write or
update of a data item is reflected in a subsequent read operation of that same
item. (读一致性表示成功写入或更新数据项后,反映在对该数据项后续读操作时的表现和时间)
DynamoDB supports two consistency models:
· Eventually consistent reads
Default behavior. It maximizes your read throughput.
An eventually consistent read might not reflect the results of a recently completed write.
Consistency across all copies of data is usually reached within a second.
Repeating a read after a short time should return the updated data.
· Strongly consistent reads
A strongly consistent read returns a result that reflects all writes that received a successful response prior to the read.
(6) Global Table
Global tables build on Amazon DynamoDB’s global footprint to provide you with a fully managed, multi-region and multi-master database that provides fast, local, read and write performance for massively scaled, global applications.
Global tables replicate your DynamoDB tables automatically across your choice of AWS regions.
Global tables provide cross-region replication, data access locality and disaster recovery for business-critical database workloads.
Applications can now perform low-latency reads and writes to DynamoDB around the world, with a time-ordered sequence of changes propagated efficiently to every AWS region where a table resides.
With DynamoDB global tables, you get built-in support for multi-master writes, automatic resolution of concurrency conflicts and CloudWatch monitoring.
(7) Amazon DynamoDB Streams
Using the Amazon DynamoDB Streams APIs, developers can consume updates and receive the item-level data before and after items are changed.
This can be used to build creative extensions to your applications on top of DynamoDB.
(8) Amazon DynamoDB Accelerator
Amazon DynamoDB Accelerator (DAX) is a fully managed, highly available, in-memory cache for DynamoDB that delivers up to a ten times performance improvement (from milliseconds to microseconds) even at millions of requests per second.
DAX does all the heavy lifting required to add in-memory acceleration to your DynamoDB tables, without requiring developers to manage cache invalidation, data population or cluster management.
(9) Encryption and Security
DynamoDB supports encryption at rest by using AWS managed encryption keys stored in the AWS KMS.
DynamoDB also offers VPC endpoints with which you can secure the access to DynamoDB.
Amazon VPC endpoints for DynamoDB enable Amazon EC2 instances in your VPC to use their private IP addresses to access DynamoDB with no exposure to the public Internet.
11.Amazon ElastiCache
Using ElastiCache, you can add an in-memory caching layer to your application in a matter of minutes with a few API calls.
Amazon ElastiCache integrates with other Amazon web services such as EC2 and RDS, as well as deployment management solutions such as AWS CloudFormation, AWS Elastic Beanstalk and AWS OpsWorks.
It is a managed service, you no longer need to perform management tasks such as hardware provisioning, software patching, setup, configuration, monitoring, failure recovery and backups.
Depending on your performance needs, it can scale out and scale in to meet the demands of your application.
The memory scaling is supported with sharding (分片)。
You can also create multiple replicas to provide the read scaling.
The in-memory caching provided by ElastiCache improves application performance by storing critical pieces of data in memory for fast access.
Cached information can include the results of database queries, computationally intensive calculations or even remote API calls.
Amazon ElastiCache currently supports two different in-memory key-value engines: Memcached and Redis.
ElastiCache manages Redis more as a relational database, because of its replication and persistence features.
Redis ElastiCache clusters are managed as stateful entities that include failover, similar to how Amazon RDS manages database failover.
When you deploy an ElastiCache Memcached cluster, it sits in your application as a separate tier alongside your database.
Amazon ElastiCache doesn’t directly communicate with your database tier or indeed have any particular knowledge of your database.