redis zset 的实现,基于链表的二分查找 -- 跳跃表源码解析
1. 引言
二分查找是一个非常简单而实用的算法,其算法基本思想是在一个有序数组中查找某个元素时,通过对比数组中间位置元素与目标元素来淘汰数组中一半的元素,达到高效查找元素的算法目标。
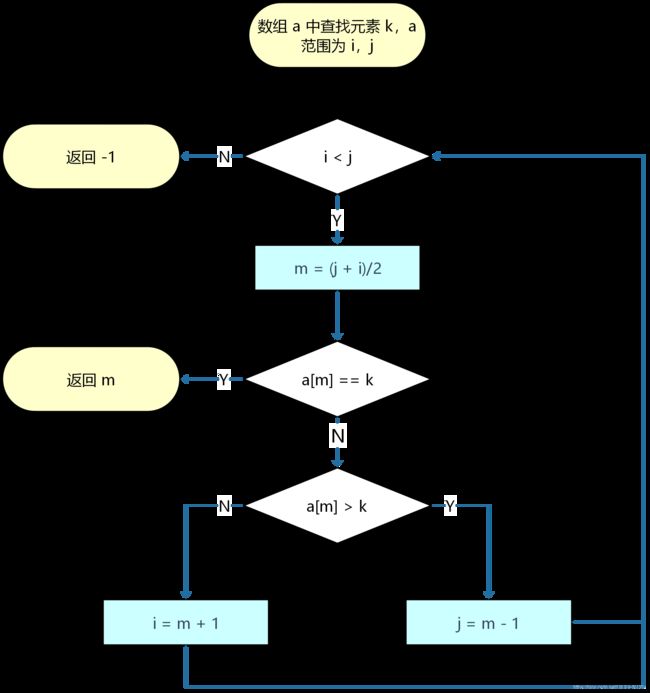
但是,二分查找是一个基于数组存储结构的算法,众所周知,数组是一个随机访问的性能卓越,但随机插入、删除元素的性能就比较差,只有 O(n) 时间复杂度,因此上述二分查找算法也存在原始数据不易增删的问题。
为了解决这个问题,通常采用将数组改为树结构的方案,因为换个角度来看,有序数组正是二叉查找树的中序遍历结果,例如自平衡的二叉查找树 – AVL 树、接近平衡的红黑树。
由于 AVL 树的算法复杂度过高,所以在实际的使用中,通常都使用红黑树作为存储结构,但红黑树的实现复杂度毕竟仍然较高 ,而解决数组随机插入、删除效率低下问题最为简单的方式是通过将数组改为链表结构,那么,是否有办法直接基于链表来实现一套二分查找的算法呢?办法当然是有的,redis 就通过一个新的数据结构 – 跳跃表,巧妙地实现了基于链表的二分查找算法,本文我们就来详细介绍一下跳跃表的结构和算法。
2. 跳跃表结构与基本算法
2.1. 跳跃表结构
假设我们有一组数字:3、7、11、19、22、26、37,从小到大排列存储在链表中:
![]()
此时,如果我们要查找某个元素,必须从第一个元素开始,顺次遍历链表,直到找到首个大于等于该元素的位置,这个查找算法的时间复杂度是 O(n) 的。
接下来,我们在偶数位置上的节点中额外增加一个指针:

此时,当我们需要查找某个元素时,只需要沿着新增的指针遍历就可以实现时间复杂度 O(n/2) 的查找算法。
那么,如果将链表数据结构进一步改变:

此时,我们可以通过每次淘汰一半数据的方式折半查找,这正是二分查找的算法。
2.2. 优势与不足
2.2.1. 优点
上述算法的优点是显而易见的,那就是解决了数组随机插入、删除元素的低效问题。
而相比于 AVL 树与红黑树,跳跃表算法的实现可谓是非常简单的。
同时,由于跳跃表本身链表数据结构的优势,进行范围查询是一件非常容易的事,而树结构需要在查询基础上额外进行中序遍历。
2.2.2. 不足
但算法的不足也同样是非常明显的,那就是如果插入新的数据或删除已有数据时,会导致现有结构不满足二分查找的要求,如果需要严格调整到如上图的结构,那么其算法复杂度仍然是比较高的,而时间复杂度也至少是 O(n)
为了解决上述算法存在的不足,redis 引入了随机化的方法,每个节点的指针数是随机的,这样就避免了每次插入或删除元素后的结构调整,而由于随机化的引入,整个结构上进行查找的期望仍然是 O(logn) 的,最坏情况下,基于随机的跳跃表退化成了普通的链表结构,查找算法的时间复杂度也因此退化为 O(n)
下图展示了 redis 跳跃表插入数据的算法执行过程:
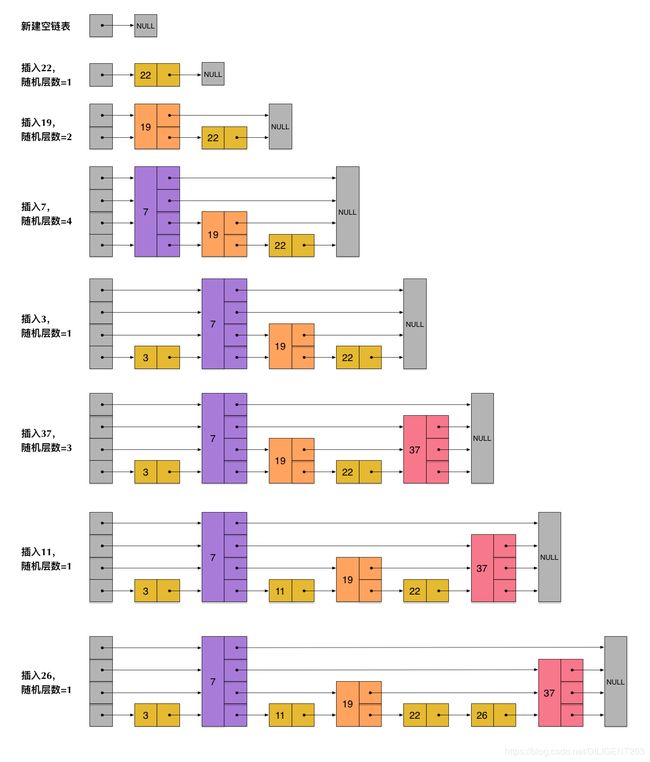
3. 跳跃表数据结构
3.1. 链表基本结构
typedef struct zskiplist {
struct zskiplistNode *header, *tail; // 跳跃表头尾节点
unsigned long length; // 跳跃表节点数量
int level; // 跳跃表最大层数
} zskiplist;
在跳跃表基本的结构体中,有两个指针,分别指向链表首节点和尾节点,分别用来正向和逆向查找元素或遍历链表。
length 字段用来存储跳跃表中的节点数。
level 字段用来存储最大层数,即所有节点中指针数量的最大值,用来预先获取二分查找的最大迭代次数。
3.2. 链表节点数据结构
typedef struct zskiplistNode {
sds ele; // 节点实际存储元素
double score; // 用于排序的分值/优先级
struct zskiplistNode *backward; // 指向前驱节点
struct zskiplistLevel {
struct zskiplistNode *forward; // 后继指针
unsigned long span; // 跨度
} level[];
} zskiplistNode;
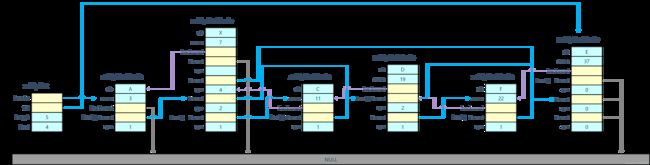
链表节点存储了实际的元素数据以及用于排序的元素分值。
对于上面已经介绍过的跳跃表结构来说,跳跃表中的节点最为重要的就是后继指针列表了,基于跳跃表的二分查找正是通过这个列表来实现的,列表中的每个元素都拥有一个后继指针和指针跨度两个字段。
同时,为了实现反向迭代,节点还拥有一个前驱指针。
3.3. 跳跃表结构示意图
4. 跳跃表算法源码解析
我们接下来看看在跳跃表上如何进行增删改查操作。
事实上,由于整个跳跃表是有序的,所以在元素插入过程中,首先需要进行的就是对待插入元素的定位,这实际上正是元素查询操作。
考虑到元素删除仅仅是对被删除元素前后的指针进行操作和相应内存的释放,难度并不大,所以此处我们只介绍一下元素插入的整体函数算法。
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned int rank[ZSKIPLIST_MAXLEVEL]; // 用于计算跨度 span 的辅助数组
int i, level;
serverAssert(!isnan(score));
// 依次遍历各层查找新节点插入位置
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
// 如果 i 不是 zsl->level-1 层, 那么 i 层的起始rank值为 i+1 层的rank值
// 各层 rank 值累积,最终 rank[0] + 1 就是新节点的前置节点的排位
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
// 沿后继指针遍历跳跃表
while (x->level[i].forward &&
// 对比节点分值
(x->level[i].forward->score < score ||
// 分值相同情况下对比节点元素
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
// 累加 rank 值,记录跨越的节点数,即 span 值
rank[i] += x->level[i].span;
// 移动指针
x = x->level[i].forward;
}
// 存储待插入节点的所有后继
update[i] = x;
}
/* we assume the element is not already inside, since we allow duplicated
* scores, reinserting the same element should never happen since the
* caller of zslInsert() should test in the hash table if the element is
* already inside or not. */
// 获取随机的节点层数值
level = zslRandomLevel();
if (level > zsl->level) {
// 如果待插入节点层数大于当前跳跃表最大层数,说明将有未使用层
// 初始化未使用层
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
// 更新跳跃表最大层数值
zsl->level = level;
}
// 分配内存,创建新节点
x = zslCreateNode(level,score,ele);
for (i = 0; i < level; i++) {
// 设置新增节点的后继
x->level[i].forward = update[i]->level[i].forward;
// 打断已有指针,指向新节点,从而实现节点插入
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
// 计算新节点的跨越节点数
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
// 更新已有节点的跨越节点数
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* increment span for untouched levels */
// 如果当前节点层数小于跳跃表最大层数,说明其外层有节点
// 需要让外层所有节点的跨越节点数 + 1
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
// 设置新增节点前驱指针
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
// 跳跃表节点数加 1
zsl->length++;
return x;
}
上面的代码中已经加入了详细的注释,其算法思想也非常容易理解。
5. 微信公众号
欢迎关注微信公众号,以技术为主,涉及历史、人文等多领域的学习与感悟,每周三到七篇推文,只有全部原创,只有干货没有鸡汤。

6. 参考资料
https://github.com/zeyu203/redis_source_commend/tree/techlog。
https://blog.csdn.net/weixin_38008100/article/details/94629753。