【机器学习笔记09】协同过滤算法 - ALS
参考资料
【1】《Spark MLlib 机器学习实践》
【2】http://blog.csdn.net/u011239443/article/details/51752904
【3】线性代数-同济大学
【4】基于矩阵分解的协同过滤算法 https://wenku.baidu.com/view/617482a8f8c75fbfc77db2aa.html
【5】机器学习的正则化 http://www.cnblogs.com/jianxinzhou/p/4083921.html
【6】正则化方法 http://blog.csdn.net/u012162613/article/details/44261657
1、协同过滤算法概念
协同过滤算法是一种基于群体用户或者物品的典型的推荐算法。考虑的推荐思路基于两类:
1)、基于用户的推荐:认为类似的用户应具备类似的爱好
2)、基于物品的推荐:认为用户会选择比较接近的物品
两类思路也存在相应的局限性:
1)、基于用户的推荐,无法准确找到物品热点,因此经常只反馈常用物品;
2)、基于物品的推荐,会导致返回相似物品,但用户往往不会购买已经选择过的类似商品;
2、相似度计算
假设存在用户和物品的评价矩阵如下:

1)、基于欧几里得距离的相似度计算
![]() ,以此公式可知用户1和用户2的相似度为:
,以此公式可知用户1和用户2的相似度为:![]()
2)、基于余弦角度的相似度计算
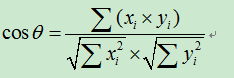 ,以此公式可知用户1和用户2的相似度为:
,以此公式可知用户1和用户2的相似度为: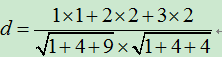
备注:2)相当于把欧几里得中的坐标点转换为向量,求向量的夹角
3、ALS(交替最小二乘法)的一些数学知识备注
1)可逆矩阵
对于矩阵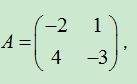 ,有矩阵
,有矩阵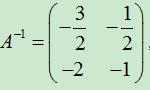 ,有
,有![]() 。
。
备注:已知对矩阵A实施一次初等行变换,相当于在矩阵的坐标乘以一个矩阵;对矩阵A实施一次初等列变换相当于在矩阵的右边乘以一个矩阵。
2)特征值
有矩阵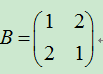 ,可计算该矩阵存在特征值3和5,分别对应特征向量
,可计算该矩阵存在特征值3和5,分别对应特征向量![]() 和
和![]() 。
。
特征值的几何意义在于该矩阵B乘以一个向量,相当于将这个向量在特征向量方向上做了一个特征值的拉升,其他都是旋转操作。
在上面的例子中,若给出向量(1,1)则被B左乘后拉升到了(3,3)。由于5这个特征值,特征向量是0,因此无法给出拉升的效果。
3)特征分解
对于可对角矩阵可以将矩阵分解称特征值和特征向量的乘积。即![]() ,其中
,其中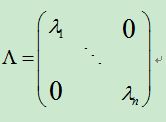
4)奇异值分解
对于大部分矩阵来说,特别是非方阵,无法进行特征分解,此时我们采用奇异值分解的方法。
![]() ,同时用前r大的奇异值来近似描述矩阵,因为奇异值递减的非常快,通常前1%~10%奇异值能够占到全部奇异值之和的99%,这也是协同过滤算法的数据基础。
,同时用前r大的奇异值来近似描述矩阵,因为奇异值递减的非常快,通常前1%~10%奇异值能够占到全部奇异值之和的99%,这也是协同过滤算法的数据基础。
4、ALS(交替最小二乘法)算法流程
在实际协同过滤算法中,并没有直接用奇异值分解,而是用ALS算法直接用低秩矩阵来逼近。![]()
当采用X来逼近矩阵R时,有Frobenius损失函数: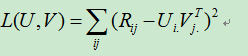 ,并增加正则化项
,并增加正则化项![]()
算法流程如下:
1、先固定矩阵U为全零
2、对L(U,V)求V的偏导,使其偏导数全为0,![]() ,得出所有的v向量
,得出所有的v向量
3、固定v向量,转而求u,同样使偏导数全为0,有公式![]() ,得到所有的u向量
,得到所有的u向量
4、重复步骤2,3,直到损失函数达到目标值。
4、ALS(交替最小二乘法)在Spark上的例子
package com.fredric.spark.als;
import org.apache.spark.mllib.recommendation.{Rating, ALS}
import org.apache.spark.{SparkContext, SparkConf}
/*-
* 协同过滤算法(ALS)
* 针对笔记《Spark-协同过滤算法-ALS》
* Fredric 2017
*/
object als {
def main(args:Array[String]): Unit ={
val conf = new SparkConf().setMaster("local").setAppName("als")
val sc = new SparkContext(conf)
val Array = new Array[Rating](5)
//new Rating(user: Int, product: Int, rating: Double)
Array(0) = new Rating(1,1,0.4)
Array(1) = new Rating(1,4,0.5)
Array(2) = new Rating(2,2,0.7)
Array(3) = new Rating(2,3,0.8)
Array(4) = new Rating(3,1,0.9)
Array(4) = new Rating(3,3,0.9)
val data = sc.makeRDD(Array)
val rank = 2 //隐语义因子的个数。
val numIterations = 5
val lambda = 0.01 //是ALS的正则化参数。
val model = ALS.train(data, rank, numIterations, lambda)
//为用户1推荐4款产品
val rs = model.recommendProducts(1, 4)
/*
输入如下:由于用户1与用户3共同爱好了产品1,因此用户3偏好的产品3也被推荐
Rating(1,4,0.4814649456978035)
Rating(1,3,0.3956308705617122)
Rating(1,1,0.38517196440752066)
Rating(1,2,0.21108557718205034)*/
rs.foreach(println)
}
}