复习之路之JAVA基础知识概括
摘抄自公开的笔记,一部分做自我补充。
1. 面向对象和面向过程的区别
面向过程 : 面向过程性能比面向对象高。 因为类调用时需要实例化,开销比较大,比较消耗资源,所以当性能是最重要的考量因素的时候,比如单片机、嵌入式开发、Linux/Unix 等一般采用面向过程开发。但是,面向过程没有面向对象易维护、易复用、易扩展。
面向对象 :面向对象易维护、易复用、易扩展。 因为面向对象有封装、继承、多态性的特性,所以可以设计出低耦合的系统,使系统更加灵活、更加易于维护。但是,面向对象性能比面向过程低。
Java 是一种兼具编译和解释特性的语言,.java 文件会被编译成与平台无关的 .class 文件,但是 .class 字节码文件无法被计算机直接,仍然需要 JVM 进行翻译成机器语言。 所以严格意义上来说,Java 是一种半解释半编译型语言。这也是java比其他面向过程语言性能低的原因之一,面向过程语言大多都是直接编译成机械码在电脑上执行,并且其它一些面向过程的脚本语言性能也并不一定比 Java 好。
2.那你来说说什么是封装,继承,多态
封装是在抽象的基础上决定信息是否公开,以及公开等级,核心问题是以什么样的方式公开哪些信息。
抽象是要找到属性和行为的共性,属性是行为的基本生产资料,具有一定的敏感性,不能直接对外暴露,所以说封装的主要任务就是对属性,数据和部分敏感行为实现隐藏。对属性的访问和修改必须通过定义的公共接口来操作。
继承是面向对象的技术基础,允许创建具有逻辑体系结构的类体系,让软件在业务多变的客观条件下,某些基础模块可以被直接,间接,或者增强的复用。父类的能力通过继承赋予子类,继承为多态打下语法基础。
多态是根据运行时的实际运行对象,同一个方法产生不同的运行结果,使同一个行为具有不同的表现形式。
说到多态就 就关系到override和overload,前者是子类重写父类的方法或者实现 的接口方法,而后者是在同一个类时方法名称相同法具有不同参数或者返回值的形式。(但是不能只是以返回值不同来区分重载的方法),假如我们调用方法的时候,不接受他的结果,恐怕你自己也不知道执行的是哪个方法吧
JDK JVM JRE
Java 虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。
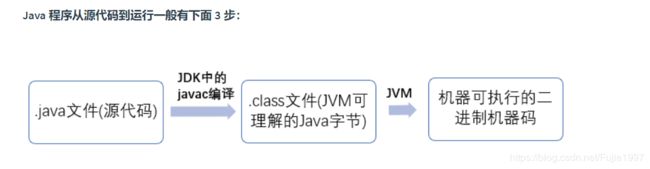
JDK 是 Java Development Kit,它是功能齐全的 Java SDK。它拥有 JRE 所拥有的一切,还有编译器(javac)和工具(如 javadoc 和 jdb)。它能够创建和编译程序
JRE Java Runtime Environment 是 Java 运行时环境。它是运行已编译 Java 程序所需的所有内容的集合,包括 Java 虚拟机(JVM),Java 类库,java 命令和其他的一些基础构件。但是,它不能用于创建新程序。
字符型常量Char和字符串String常量的区别?
形式上: 字符常量是单引号引起的一个字符; 字符串常量是双引号引起的若干个字符
含义上: 字符常量相当于一个整型值( ASCII 值),可以参加表达式运算; 字符串常量代表一个地址值(该字符串在内存中存放位置)
占内存大小 字符常量只占 2 个字节; 字符串常量占若干个字节 (注意: char 在 Java 中占两个字节)
那么JAVA有几种基本类型?
boolean(8位),byte(8位),char(16位),short(16位),int(32位),long(64),float(32),double(64).
在类中作为变量的时候都会 默认值。
除了浮点类型和boolean,他们都有缓存区间。
64位的数据理论上在32位JVM上不能保证原子性。
上面说的缓存区间又是什么啊?
上面说的缓存区间,是指他们的包装类有缓存区间。包装类可以完成基本数据类型不能做的事情。
比如:泛型参数,序列化,类型转换,缓存。
上面的基本类型的的缓存区间byte,short,int,long在【-128,127】char在【0,127】,浮点和boolean没有。
public class CacheTest(){
public static void main(String[] args){
Long a = 127L;
Long b = 127L;
(a == b);//true,二者在缓存池中,是复用的缓存池的现象
Long a1 = 128L;
Long b2 = 128L;
(a1 == b1);//false,不在缓存中,都是新生成的对象
}
}
String的缓存池
为什么String要单独说,他不是基本类型呀!String不是基本类型
创建字符串的三类方式:
1、String s=new String(“abc”);
2、直接指定:String s=“abc”;
3、用字符串生成新的字符串:String s=“ab”+c;
String对象创建的原理:
(1)、当使用任何一种方法创建一个字符串对象s时,java运行时会拿这个s在string池中找是否存在相同的内容的字符串对象,如果不存在,则在池中创建一个字符串s,否则,不在池中添加。
(2)、java中,只要使用new关键字来创建对象,则一定会创建一个新的对象。
(3)、使用直接指定或者使用纯字符串串联来创建String对象,但仅仅会维护string池中的字符串,池中没有就在池中创建一个,有则罢了,绝不会再堆栈区再去创建该String对象。
(4)、使用包含变量的表达式来创建String,则不仅会维护String池,而且还会在堆栈区创建一个String对象。
String StringBuffer 和 StringBuilder 的区别是什么? String 为什么是不可变的?
String,StriingBuffer是线程安全的,StringBuilder不是。
可变性
简单的来说:String 类中使用 final 关键字修饰字符数组来保存字符串,private final char value[],所以 String 对象是不可变的。
啥?
String str = "a" ;
str = "b";
str.sout();//我不是改变了吗?
其实不然,JDK8 String 通过char数组实现,通过final修饰,str = b的操作只是重新创建了一个对象然后将str的 指针指向b,原先的a还是没有被改变。(出门右转百度final的内存语义)
以下代码:
String sstr = "start";
for(int i = 0,i<100; i++){
str = str +"h";
}
内部实现是每次 循环都要new一个StringBuilder的对象,然后通过append操作,最后通过ToString返回,性能差,浪费资源。
对于三者使用的总结:
操作少量的数据: 适用 String
单线程操作字符串缓冲区下操作大量数据: 适用 StringBuilder
多线程操作字符串缓冲区下操作大量数据: 适用 StringBuffer
自动装箱与拆箱
装箱:将基本类型用它们对应的引用类型包装起来;
拆箱:将包装类型转换为基本数据类型;
为什么要搞这么多幺蛾子?
在JAVA中一切都是对象,但是基本数据类型他就不是对象。
List<Integer> list = new ArrayList<>();//行!Integer是对象
List<int>list = new ArrayList<>();//代码报错,int不是对象
在一个静态方法内调用一个非静态成员为什么是非法的?
类的静态成员(变量和方法)属于类本身,在类加载的时候就会分配内存,可以通过类名直接去访问;非静态成员(变量和方法)属于类的对象,所以只有在类的对象产生(创建类的实例)时才会分配内存,然后通过类的对象(实例)去访问。
所以:
Person{
public static String staticStr = "str";
public String str = "str";
public static void test(){
//这里访问不到str 报错
this.str =
}
public void test2(){
this.staticStr//能访问
}
}
为什么?你想想前面说的先后顺序,加载类值加载类的静态方法变量的时候实例化都还没有开始,他拿命去访问?
实例化完成自然可以访问到静态的。
在 Java 中定义一个不做事且没有参数的构造方法的作用
Java 程序在执行子类的构造方法之前,如果没有用 super()来调用父类特定的构造方法,则会调用父类中“没有参数的构造方法”。因此,如果父类中只定义了有参数的构造方法,而在子类的构造方法中又没有用 super()来调用父类中特定的构造方法,则编译时将发生错误,因为 Java 程序在父类中找不到没有参数的构造方法可供执行。解决办法是在父类里加上一个不做事且没有参数的构造方法。
接口和抽象类的区别是什么?
码处高效56页,57页。


成员变量与局部变量的区别有哪些?
从语法形式上看:成员变量是属于类的,而局部变量是在方法中定义的变量或是方法的参数;成员变量可以被 public,private,static 等修饰符所修饰,而局部变量不能被访问控制修饰符及 static 所修饰;但是,成员变量和局部变量都能被 final 所修饰。
从变量在内存中的存储方式来看:如果成员变量是使用static修饰的,那么这个成员变量是属于类的,如果没有使用static修饰,这个成员变量是属于实例的。而对象存在于堆内存,局部变量则存在于栈内存。
从变量在内存中的生存时间上看:成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动消失。
成员变量如果没有被赋初值:则会自动以类型的默认值而赋值(一种情况例外:被 final 修饰的成员变量也必须显式地赋值),而局部变量则不会自动赋值。
在调用子类构造方法之前会先调用父类没有参数的构造方法,其目的是?
帮助子类做初始化工作。
1.首先加载父类的静态字段或者静态语句块
2.子类的静态字段或静态语句块
3.父类普通变量以及语句块
4.父类构造方法被加载
5.子类变量或者语句块被加载
6.子类构造方法被加载
== 与 equals
== 比较的就是hashcode
hashcode 和equals用来标志对象,两个方法协同比较两个对象是否相等。
众所周知,不同对象hash可能会相同,hash相同再用equals比较他们的值,如果值不同才是真的不是同一个对象。如果hash都不同了,那么肯定不是形同的对象。
所以:
equals比较的值同的对象,hash必然相同
重写equals必须重写hashcode
加入你定义了这么一个类,
person p1 = new person("付有杰","身份证号码");
person p2 = new person("付有杰","身份证号码");
表面上看,明明想表达的就是全国唯一指定的付有杰,但是他们是同一个对象吗?不是,他们的地址都不一样。
如果你用p1做键存在set中,那么在你存入p2的时候,他必定会在新的位置。
set.add(p1);
set.add(p2);
set.size();//我们期望是1 但是却是2
所以我们还要重写hashcode,使p1,p2 得出hashcode是一样的。
其他的 多线程,IO,集合,异常体西,另开文章