impala--将一列多行数据合并到一行一列中
工作中遇到一个需求,前端传入参数peopleid(s),根据这个(些)参数去hive中查询旅馆,需要返回一个success字段,代表这些参数中查询有结果的个数。问题在于如何确定哪个peopleid在哪个旅馆住过?
一、问题分析:
假设前端传入两个住宿人的peopleid,peopleidA和peopleidB,通过查询返回结果两个旅馆lgA和lgB,①peopleidA两个旅馆都住过,peopleidB都没住过,那么success就是1。②peopleidA住过lgA,peopleidB住过lgB,那么success就是2。如何确定哪个住宿人在哪个旅馆住过?
二、解决思路:
数据库返回每个旅馆的住宿人的peopleid,和前端参数逐一判断。
三、解决过程:
初始语句:
select
distinct a.zhusulvguan
from
table_lvguan a join table_people b on b.zhusulvguanId = a.zhusulvguanId
where
1=1 and (b.peopleid in '210602198109262019','330103199011200223') or b.peopleid2 in ('210602198109262019','330103199011200223'))
b的peopleid为住宿人,peopleid2为同住人 zhusulvguan为旅馆名称
该语句查询的只有去重后的旅馆名字:
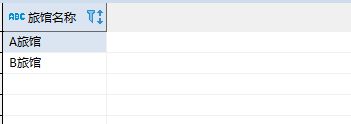
既然需要查询peopleid那么查询加上peopleid,但是问题来了,去重会失效:
select
distinct a.zhusulvguan,b.peopleid ,b.peopleid2
from
table_lvguan a join table_people b on b.zhusulvguanId = a.zhusulvguanId
where
1=1 and (b.peopleid in '210602198109262019','330103199011200223') or b.peopleid2 in ('210602198109262019','330103199011200223'))
加上peopleid后的结果:
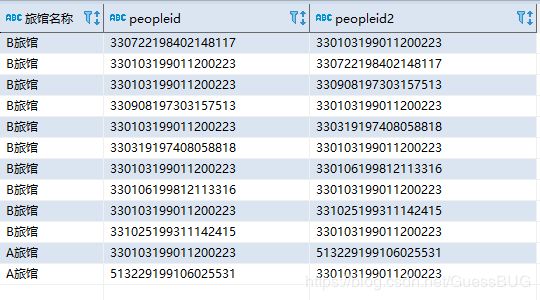
如果我能把同一个住宿旅馆的所有peopleid和peopleid2放到一个字段里peopleidall,那么问题就解决了。只需要在后端拿前端传入的ids参数和每个旅馆的peopleidall判断即可。在网上搜索到了impala的group_concat(column)方法,将某一个列的数据放到一起,需要配合group by使用。(同组的数据,通过group_concat(column)指定要放到一起的数据是哪列,然后列名去重;比如我目前需要通过住宿旅馆分组,然后把peopleid和peopleid2分别放到一起。)
修改后:
select
a.zhusulvguan,group_concat(b.peopleid,',') ,group_concat(b.peopleid2,',')
from
table_lvguan a join table_people b on b.zhusulvguanId = a.zhusulvguanId
where
1=1 and (b.peopleid in ('210602198109262019','330103199011200223') or b.peopleid2 in ('210602198109262019','330103199011200223'))
group by a.zhusulvguan
合并同列数据后的结果:
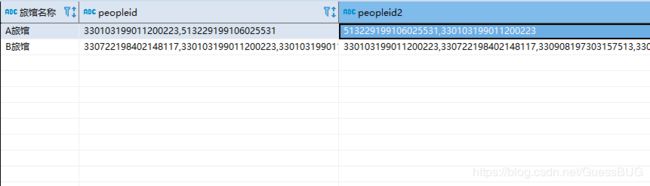
可以看出,很接近预期效果,同一个旅馆,把peopleid和peopleid2分别合并到一行中。但还差最后一步,把peopleid和peopleid2合并,就完全符合预期效果啦。可以使用concat()函数连接列的值:
select
a.zhusulvguan,concat(group_concat(b.peopleid,','),',',group_concat(b.peopleid2,',')) peopleidall
from
table_lvguan a join table_people b on b.zhusulvguanId = a.zhusulvguanId
where
1=1 and (b.peopleid in ('210602198109262019','330103199011200223') or b.peopleid2in ('210602198109262019','330103199011200223'))
group by a.zhusulvguan
最终效果:
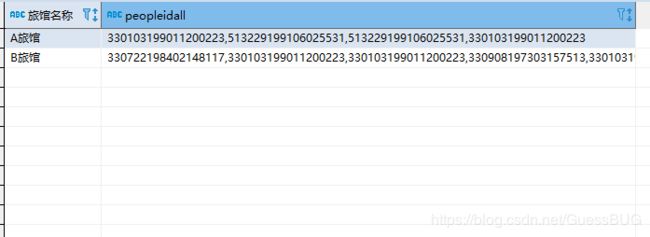
达到了预期的效果,剩下的就是结果返回到后端的操作了,不再多说。
四、总结:
①group_concat(column[,char])函数:把同组中指定的column放到一行中[通过char连接],并且去重(列名去重,值不去重)。
②既然是同组数据的操作,那么group_concat()就要配合group by使用。特别的,group by 分组依据并不强制要求和group_concat(column)指定的column相同(个数,字段名)。分组依据可以多于or不等于column。其他情况还没有试,有兴趣的小伙伴可以自己试一试。
③concat(column1,‘cahr’,column2):column1和column2的值通过cahr连接后合并