python使用selenium+geckodriver完美爬取使用Ajax技术异步加载的拉勾网(附带selenium爬取BOSS直聘代码)
文章目录
- 前言
- 一、页面分析
- 二、下载浏览器驱动
- 三、详细代码
- 四、selenium爬取BOSS直聘代码
前言
拉勾网的反爬虫做的很好,导致我们使用requests库进行爬取的时候,经常会被发爬虫,包括或返回空数据。同时,这个网站采用Ajax技术进行异步加载,我们在请求列表网页时,并不会获取到职位列表的相关信息,因此,使用selenium+geckodriver的方式,模拟Firefox浏览器完美爬取拉勾网和BOSS直聘的岗位列表及岗位详情。
一、页面分析
进入拉勾网搜索职位网址:https://www.lagou.com/jobs/list_?labelWords=&fromSearch=true&suginput=,然后进入审查元素模式

在右下方response中,我们并不能找到职位相关信息。
然后,我们查看一个名为positionAjax.json?px=new&needAddtionalResult=false的文件,可以找到相关信息。
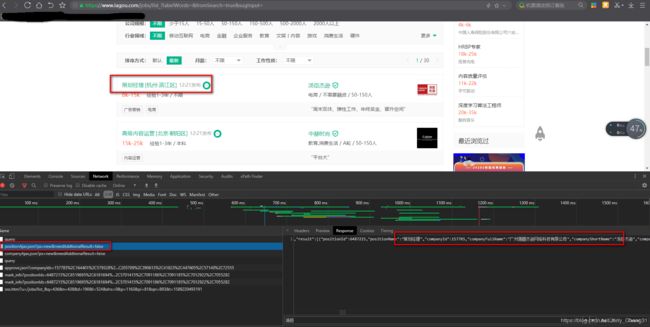
这说明此网站是通过Ajax技术进行异步加载。
二、下载浏览器驱动
因为我用的是Firefox浏览器,因此需要下载Firefox浏览器驱动 geckodriver 。若是使用其他浏览器,需要下载其他浏览器相应的驱动。下载后,将该驱动程序最好放在一个不需要权限的全英文路径的文件夹中,以防后面出错。

三、详细代码
通过定义类及类方法的方式完成爬虫。以下为具体代码:
# 导入相关库
from selenium import webdriver
from lxml import etree
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import csv
# 创建类
class lagouspider(object):
# 指定驱动程序位置
driver_path = r"D:\geckodriver\geckodriver.exe"
def __init__(self):
# 创建驱动器
self.driver = webdriver.Firefox(executable_path = lagouspider.driver_path)
# 指定初始URL
self.url = "https://www.lagou.com/jobs/list_/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput="
# 创建一个空列表,用于保存爬取下来的信息
self.positions = []
# i和j是为了在爬虫时打印信息,无实际意义
self.i = 0
self.j = 1
# 定义run方法
def run(self):
print("开始解析第1页")
self.driver.get(self.url)
while True:
# 获取职位列表网页
source = self.driver.page_source
# 传入到parse_list_page函数解析职位列表页
self.parse_list_page(source)
# 找到“下一页”按钮
next_botn = self.driver.find_element_by_xpath("//div[@class='pager_container']/span[last()]")
# 当下一页不能点击时,停止爬取
if "pager_next pager_next_disabled" in next_botn.get_attribute("class"):
break
else:
# 当下一页还能点击时,点击下一页,继续爬取下一页
next_botn.click()
self.j += 1
print("开始解析第{}页".format(self.j))
time.sleep(1)
# 定义解析职位列表页函数
def parse_list_page(self,source):
html = etree.HTML(source)
# 获取职位详情页的URL
links = html.xpath("//a[@class='position_link']/@href")
for link in links:
self.i += 1
print("解析第{}条数据{}".format(self.i,link))
# 传入request_detial_page函数请求职位详情页
self.request_detial_page(link)
time.sleep(1)
def request_detial_page(self,url):
# !!!注意:需要打开一个新窗口来打开详情页列表,否则会覆盖到职位列表页,导致无法点击下一页
self.driver.execute_script("window.open('%s')"%url)
# !!!注意:需要切换到新的窗口来获取信息
self.driver.switch_to.window(self.driver.window_handles[1])
# 使用WebDriverWait和expected_conditions进行等待操作,确保需要的元素加载完毕,否则可能会因为元素未加载完而导致获取不到相应元素,从而报错
WebDriverWait(self.driver,timeout=10).until(EC.presence_of_element_located((By.XPATH,"//div[@class='job-name']/h1[@class='name']")))
source = self.driver.page_source
self.parse_detial_page(source)
time.sleep(1)
# !!!注意:关闭当前页面(即职位详情页),确保最多只有职位列表页和职位详情页两个页面,否则会导致以后进行窗口切换很麻烦。
self.driver.close()
# !!!注意:必须切换到职位列表页,然后在上面的run方法中点击下一页按钮,否则会报错找不到下一页按钮
self.driver.switch_to.window(self.driver.window_handles[0])
# 解析职位详情页
def parse_detial_page(self,source):
html = etree.HTML(source)
title = html.xpath("//div[@class='job-name']/@title")[0].strip()
company = html.xpath("//div[@class='job_company_content']//em[@class='fl-cn']//text()")[0].strip()
salary = html.xpath("//dd[@class='job_request']/h3//text()")[1].strip()
location = html.xpath("//dd[@class='job_request']/h3//text()")[3].strip()
times = html.xpath("//p[@class='publish_time']//text()")[0].strip()
education = html.xpath("//dd[@class='job_request']/h3//text()")[7].strip()
experience = html.xpath("//dd[@class='job_request']/h3//text()")[5].strip()
contents = html.xpath("//div[@class='job-detail']//text()")
contents = list(map(lambda content: content.strip(), contents))
contents = "".join(contents)
position = {
"title": title,
"company": company,
"salary": salary,
"location": location,
"times": times,
"education": education,
"experience": experience,
"contents": contents
}
self.positions.append(position)
self.save_files(self.positions)
# 保存爬取下来的信息
def save_files(self,positions):
headers = ['title', 'company', 'salary', 'location', 'times', 'education', 'experience', 'contents']
with open("lagou_spider.csv", 'w', encoding='utf-8', newline='') as f:
writer = csv.DictWriter(f, headers)
writer.writeheader()
for position in positions:
writer.writerow(position)
f.close()
if __name__ == '__main__':
spider = lagouspider()
spider.run()
以上就是具体的代码,请注意代码中注释部分的 “!!!注意:”
四、selenium爬取BOSS直聘代码
基本流程和方法和上面类似,只是通过定义函数方式爬取
from selenium import webdriver
from lxml import etree
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import csv
import time
driver_path = r"D:\geckodriver\geckodriver.exe"
driver = webdriver.Firefox(executable_path=driver_path)
start_url = r"https://www.zhipin.com/job_detail/?ka=header-job"
positions = []
i = 1
j = 1
def get_urls():
global i
global j
print("开始解析第%d页!"%i)
driver.get(start_url)
while True:
WebDriverWait(driver,timeout=10).until(EC.presence_of_element_located((By.XPATH,"//div[@class='job-title']/span[@class='job-name']/a")))
source = driver.page_source
html = etree.HTML(source)
urls = html.xpath("//div[@class='job-title']/span[@class='job-name']/a/@href")
urls = list(map(lambda url:"https://www.zhipin.com"+url,urls))
for url in urls:
print("正在解析第{}页,第{}条数据:{}".format(i,j,url))
j += 1
request_detail_url(url)
time.sleep(1.5)
next_btn = driver.find_element_by_xpath("//div[@class='page']/a[last()]")
if "next disabled" in next_btn.get_attribute("class"):
break
else:
next_btn.click()
i +=1
print("开始解析第%d页!"%i)
time.sleep(1.5)
def request_detail_url(url):
driver.execute_script("window.open('%s')"%url)
driver.switch_to.window(driver.window_handles[1])
WebDriverWait(driver, timeout=10).until(EC.presence_of_element_located((By.XPATH, "//div[@class='job-detail']")))
detail_source = driver.page_source
parse_detail_page(detail_source)
driver.close()
driver.switch_to.window(driver.window_handles[0])
def parse_detail_page(detail_source):
detail_html = etree.HTML(detail_source)
title = detail_html.xpath("//div[@class='name']/h1/text()")[0].strip()
company = detail_html.xpath("//a[@ka='job-detail-company_custompage']/text()")[0].strip()
salary = detail_html.xpath("//div[@class='name']/span[@class='badge']/text()")[0].strip()
location = detail_html.xpath("//div[@class='info-primary']/p//text()")[0].strip()
times = detail_html.xpath("//div[@class='sider-company']//p[@class='gray']/text()")[0].strip()
education = detail_html.xpath("//div[@class='info-primary']/p//text()")[2].strip()
experience = detail_html.xpath("//div[@class='info-primary']/p//text()")[1].strip()
contents = detail_html.xpath("//div[@class='job-sec']//div[@class='text']//text()")
contents = list(map(lambda content:content.strip(),contents))
contents = "".join(contents)
position = {
"title":title,
"company":company,
"salary":salary,
"location":location,
"times":times,
"education":education,
"experience":experience,
"contents":contents
}
positions.append(position)
save_files(positions)
def save_files(positions):
global z
head = ['title','company','salary','location','times','education','experience','contents']
with open("boss_spider.csv",'w',encoding='utf-8',newline='') as f:
writer = csv.DictWriter(f,head)
writer.writeheader()
for position in positions:
writer.writerow(position)
f.close()
if __name__ == '__main__':
get_urls()