交叉验证——sklearn.model_selection.KFold
最近使用python进行数据集的划分。使用到了交叉验证(Cross-validation),需要整理sklearn.model_selection.KFold函数的参数设定和使用实例。整理如下:
1、Cross-validation 交叉验证
附注:官方文档链接:https://scikit-learn.org/dev/modules/cross_validation.html#cross-validation
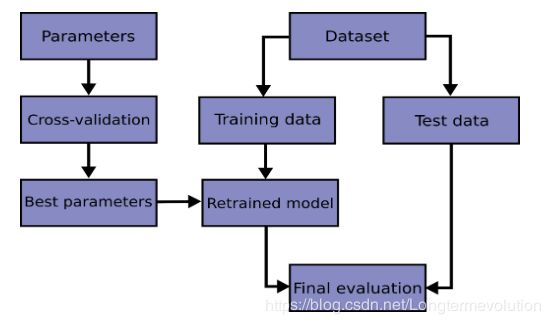
交叉验证的基本思想:把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set or test set),首先用训练集对模型进行训练(可以使用不同的机器学习训练方法),得到相应模型(如模型A)。再利用验证集来测试模型(A)的泛化误差。另外,现实中数据总是有限的,为了对数据形成重用,从而提出k-折叠交叉验证。下图为网上传播较多的5折交叉验证图示。
 5折交叉验证-图源网络
5折交叉验证-图源网络
对回归问题或者分类问题,经过k折交叉验证之后,计算k次求得的分类率的平均值,作为该模型或者假设函数的真实分类率。Cross-validation能有效的避免过学习以及欠学习状态的发生,结果也比较具有说服性。
2、sklearn.model_selection.StratifiedKFold 函数使用
官方文档链接:https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.StratifiedKFold.html
StratifiedKFold 函数。分层K-Folds交叉验证器,提供训练/测试索引以分割训练/测试集中的数据。此交叉验证对象是KFold的变体,可返回分层折叠。 通过保留每个类别的样本百分比来进行折叠。
1)参数:
n_splits:折叠数量,表示划分成几份。 必须至少2。版本0.20更改:n_splits默认值将在v0.22中从3更改为5。
shuffle:布尔值,可选。 是否在划分之前对每个类的样本进行洗牌。
①若为Falses时,其效果等同于random_state等于整数,每次划分的结果相同
②若为True时,每次划分的结果都不一样,表示经过洗牌,随机取样的
random_state:随即种子。int,RandomState实例或None,默认=无。
如果是int,则random_state是随机数生成器使用的种子; 如果是RandomState实例,则random_state是随机数生成器; 如果为None,则随机数生成器是np.random使用的RandomState实例。 在shuffle == True时使用。
2)工具函数
get_n_splits(self[, X, y, groups]) |
返回交叉验证器中的拆分迭代次数; |
split(self, X, y[, groups]) |
将数据拆分为训练和测试集,返回索引值。 |
X: 矩阵,(n_samples,n_features)。训练数据,其中n_samples是样本数,n_features是特征数。
注意,提供y足以生成分割,因此np.zeros(n_samples)可以用作X的占位符而不是实际训练数据。
y: 矩阵,(n_samples,)。监督学习问题的目标变量,标签值。
groups:对象。
3)以下为划分代码实例
eg1:划分之后不洗牌,shuffle=False,运行两次,结果相同。
调用形式为:StratifiedKFold(n_splits=3, shuffle=False, random_state=None)
import numpy as np
from sklearn.model_selection import StratifiedKFold
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([0, 0, 1, 1])
skf = StratifiedKFold(n_splits=2)
skf.get_n_splits(X, y)
print(skf)
for train_index, test_index in skf.split(X, y):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]运行结果如下,将X(4行2列,每一行的编号为0,1,2,3),进行2折划分,就是将数据集划分2次,每次将其分为小train和小test两部分。
第一次划分数据集结果为:1,3行为小train;0,2行为小test。
第二次划分数据集结果为:0,2行为小train;1,3行为小test。
#第一次运行程序结果
StratifiedKFold(n_splits=2, random_state=None, shuffle=False)
TRAIN: [1 3] TEST: [0 2]
TRAIN: [0 2] TEST: [1 3]
#第二次运行程序结果,因为未洗牌,所以结果相同
StratifiedKFold(n_splits=2, random_state=None, shuffle=False)
TRAIN: [1 3] TEST: [0 2]
TRAIN: [0 2] TEST: [1 3]
eg2:划分后洗牌,shuffle=True,运行两次,结果不同。
import numpy as np
from sklearn.model_selection import StratifiedKFold
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8],[9, 10], [11, 12],[13, 14], [15, 16]])
y = np.array([0, 0, 1, 1,0, 0, 1, 1])
# //K折划分,就是将数据集划分k次,每次将其分为小train和小test两部分。如果数据集行数可以被k整除,那么小test的行数就为被整除后的一份
skf = StratifiedKFold(n_splits=4,shuffle=True)
#获得划分的次数并且打印,就是n_splits
print(skf.get_n_splits(X, y))
print(skf)
for train_index, test_index in skf.split(X, y):
print("TRAIN:", train_index, "TEST:", test_index)
# 生成小train,小test。X为样本(行)+特征(列)矩阵,y为标签向量
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]结果
#第一次运行结果
4
StratifiedKFold(n_splits=4, random_state=None, shuffle=True)
TRAIN: [0 1 2 3 5 7] TEST: [4 6]
TRAIN: [0 2 4 5 6 7] TEST: [1 3]
TRAIN: [1 3 4 5 6 7] TEST: [0 2]
TRAIN: [0 1 2 3 4 6] TEST: [5 7]
#第二次运行结果,因为设置划分一次数据集之后进行洗牌,所以结果不一样
4
StratifiedKFold(n_splits=4, random_state=None, shuffle=True)
TRAIN: [1 2 4 5 6 7] TEST: [0 3]
TRAIN: [0 1 2 3 5 7] TEST: [4 6]
TRAIN: [0 3 4 5 6 7] TEST: [1 2]
TRAIN: [0 1 2 3 4 6] TEST: [5 7]