用Python+小程序实现诗词大会的飞花令 !
写在前面
在2018年下半年的某一天,偶然观看了《中国诗词大会》节目的飞花令环节。当时作为语音行业一员对此十分感兴趣,想着能不能用程序实现一个,思考技术方案的时候发现最大难度就是数据,遂求助 码农交友社区(

https://github.com/),发现了开源库 chinese-poetry(https://github.com/chinese-poetry/chinese-poetry),然后结合免费的百度语音识别,整个项目就成了。
实现语音版飞花令仅作为兴趣爱好,之前本来是用 Django 完成的,在朋友的安利之下改用 Sanic 重写。实现的过程中都是站在程序猿的角度看待整个程序,同时程序运行的服务器性能不算好、语音匹配算法实现得很粗糙等等,所以整个程序仅仅处于可用的状态,离体验好还差18条街吧。
Python学习交流群:1004391443
但作为一个完整的应用,整个功能涉及到了Web后端常用的技术,供有一定Web基础的同学参考,特别是对于写过基本的Web后端程序然后想尝试异步编程的同学,本应用的技术栈为:
- 后端框架:Sanic + aioredis + aiomysql + aiohttp
- 数据库: mysql + redis
- 部署: nginx + docker + gunicorn
- 前端: 微信小程序
本文会简单地讲一下应用架构。
最后感谢 Crossin先生 在我完成此应用时提供的指导建议,也感谢合作开发者 自由爸爸 同学为飞花令在数据导入,查询优化方面做的工作。
文章最后会贴出小程序码供大家尝鲜,并将项目上传 github 供大家下载。
飞花令
整体架构如图所示
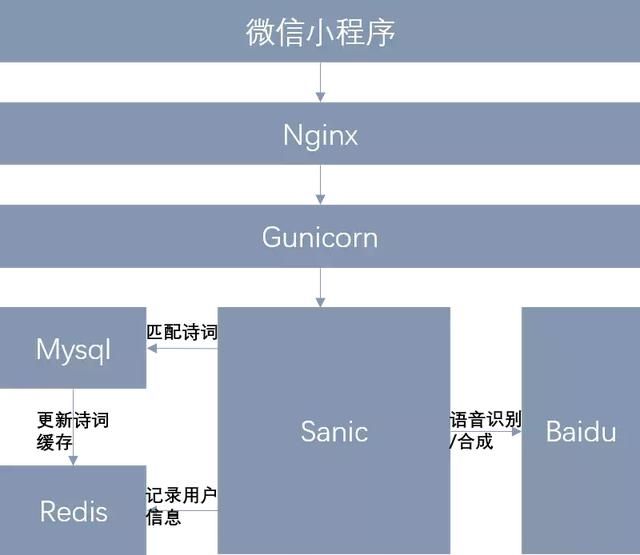
架构如上图所示,接下来分享部分技术细节。
Sanic
后端框架采用了 Sanic (https://github.com/huge-success/sanic),这是一个异步非阻塞网络框架,可以看做异步版本的 flask,sanic 比起 Django 轻量很多,简单几行就可以搭起一个接口
from sanic import Sanic
from sanic.response import json
app = Sanic()
@app.route('/')
async def test(request):
return json({'hello': 'world'})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8000)
结合 Python3.7 的 Asyncio (https://docs.python.org/3/library/asyncio.html) 模块,可以放弃多线程方案而使用性能更好的协程方案,比如同时请求多个网页:
import aiohttp
import asyncio
async def get_url(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
print(response.status)
async def main():
await asyncio.gather(
get_url("http://www.baidu.com"),
get_url("http://www.jd.com"),
get_url("http://www.taobao.com"))
if __name__ == "__main__":
asyncio.run(main())
总的来说,在写异步代码的过程中还是非常开心的,有兴趣的同学可以了解一下。
百度语音识别
实现飞花令的核心之一,语音合成和识别都是用的百度(http://ai.baidu.com/tech/speech)家的技术,无他,仅仅是因为这是免费接口。
百度提供了基于 requests 做的 python-sdk (https://github.com/Baidu-AIP/python-sdk),我这边为了适配异步框架重写了语音识别和语音合成部分的代码,将 requests 更换为了 aiohttp (https://github.com/aio-libs/aiohttp),简单的修改代码见 aiohttp-aip (https://github.com/Provinm/flyingflower_public/tree/master/flyingflower/aip)
修改后的代码可满足当前项目的需求。
中文繁体转换为简体
飞花令的数据全部来自于 chinese-poetry(https://github.com/chinese-poetry/chinese-poetry),但在使用过程中发现诗词是繁体版本,而百度语音给出的结果是中文简体,为了达到匹配的目的,需要将繁体转换为简体。
github 了一下,发现并没有人做这个事情,所以就自己动手写了一个脚本,实现了中文繁转简。为了造福大众,转换好的简体放在 chinese-poetry-simplified(https://github.com/Provinm/chinese-poetry-simplified),项目中包含已经转换好的中文版本的诗词文件,以及转换过程用到的脚本,有需要的同学可以自己修改生成所需的版本。
最后
以上是关于飞花令应用的总结,总的来说还是挺满意这次实践。其实整个应用还有很多需要完善的地方:
- 玩法单一,缺乏趣味
- 前端页面丑,交互体验差
- 后端从语音识别出结果到Mysql查询优化实现得很粗糙,仅仅使用了 Mysql 内置的 locate 语法,匹配算法其实还可以写的更好更精准
- 语音识别的准确率不够好
等等
虽然问题不少,但毕竟是我自己一个完整的线上项目,还是有点小小的成就感。
因为服务器带宽有限,文章中不直接放码了,怕挂。想体验的朋友,可以在公众号里回复关键字 诗词 获取小程序码。如果文章刚发出来时候访问速度慢,建议你过一会儿再回来

对代码感兴趣的同学可以 clone 我在 github 上的代码,按照 readme 进行部署。
有希望继续改进的同学可以在 github 上 fork 飞花令代码库进行二次开发。
最后,打开 github 页面的同学留下 star 吧(祈求脸)