数据结构与算法设计 知识归纳
数据结构与算法设计
- 基础数据结构
- 算法方面
- 算法竞赛入门
- 基础算法
- 1. 将给定的少数整数进行排序
- 2. 计算数组中所有正数,或者所有负数的和
- 3. 求数组中奇数或者偶数元素的个数
- 4. 求两数之间的所有整数的和,不包括两个端点
- 5. 返回整数a的“倒数”
- 6. 找出1至1000以内的质数
- 6. 求出小于等于整数a的所有质数和
- 7. 计算并返回一组整数的最大值
- 8. 根据四个正整数,组成互不相同三位数
- 9. 打印实心三角形
- 排序
- 1. 冒泡排序
- 2. 选择排序
- 矩阵中算法
- 1. 将一个ndarray类型的数组顺时针旋转90度。
- 模块应用
- 1. Algorithm模板中的Min/Max应用
- 2. 模板函数sort对学生成绩进行排序
- 应用算法
- 1. 统计一段英文文章(a)中单词的个数
- 2. 实现词频统计和排序输出
基础数据结构
算法方面
Expansion:算法竞赛:培养杰出程序员的捷径。
- 杰出的程序员往往具备:
- 掌握多种编程语言
- 代码量大
- 算法知识丰富
- 数学强
- 做过很多项目
- 有团队精神
- 有创新意识
- 会选择行业方向
- etc…
算法竞赛入门
- 竞赛语言和训练平台
- 判题和基本的输入输出
- 测试
- 编码速度
- 模板
- 题目分类
- 代码规范
- 代理网站 列出了著名OJ

- NOI的OJ:高中NOI信息学竞赛
CCF的OJ;洛谷
大视野:网上简称bzoj
Notice:其中“洛谷试炼场”题目分类比较全,是很好的基础学习平台。
- OJ的判题
-
OJ由机器自动判题,但机器并没有看懂代码的智能;即使是人工判题,人也很难短时间看懂程序。
-
OJ判题是一种黑盒测试,它并不关心程序的内容,而是用测试数据来验证。
- OJ的判题结果

- 打表
- 由于OJ不看程序内容,只关心程序的输入和输出,因此,在程序中不写详细过程,而是用printf或cout直接打印结果,也是允许的,这种方法叫“打表”。
- 另外,程序可能需要预处理数据,这个做法也称为“打表”。
- 输入输出函数
-
C++:输入函数cin,输出函数cout。
-
C语言:输入函数scanf,输出函数printf。
- 标准输入输出
Description:OJ默认使用stdin和stdout,所以在提交程序时,并不用管OJ是怎么进行数据测试的。
Notice:如果用到其它方法,会特别说明。
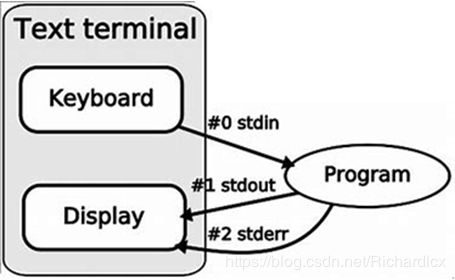
- 输入的结束(以C语言为例)
- 默认结束(结束条件为无内容输入)
int main(void){
int a, b; // 输入a、b
while (scanf("%d %d", &a, &b) != EOF){
// 等价于while(~scanf("%d %d", &a, &b)){
// ...... ;
}
return 0;
}
// 推荐用 while (~scanf("%d %d", &a, &b))
- 在输入数据中指定数据个数
eg:hdu 1090题
int main(){
int n, a, b;
scanf("%d", &n);
while (n--){
scanf("%d %d", &a, &b);
printf("%d\n", a + b);
}
return 0;
}
- 以特定元素作为结束符。
eg:以0作为结束符,输入读到0时,就退出:
while(~scanf("%d", &n) && n);
- 输入输出的效率
cin和cout效率低:与scanf、printf相比,cin、cout的效率很低,速度很慢。
如果题目中有大量测试数据,由于cin、cout输入输出慢,可能导致TLE。在这种情况下,应使用scanf、printf。
- 测试
Explain:一个队伍中,安排一个队员负责构造测试数据。
把构造出的输入数据放在文件test.in里,程序的结果输出到文件test.out里。
输出文件test.out可以不要:直接在屏幕上看输出结果。
Notice:c++中创建.in文件,c++调用.in文件
测试的两种方法:
- 在程序中加入测试代码
#define mytest // 定义一个预处理宏
#ifdef mytest // 判断某个宏是否被定义,若已定义,执行随后的语句
freopen(“test.in”, “r”, stdin); // 读数据文件标准输入
freopen(“test.out”, “w”, stdout); // 将结果标准写入到输出文件
#endif // #if, #ifdef, #ifndef这些条件命令的结束标志
- 在行命令中重定向
Description:不用在程序中加任何代码。例如生成的的可执行程序是abc,在windows或linux的行命令中,这样输入和输出到文件:
abc .in >test.out
基础算法
1. 将给定的少数整数进行排序
- Java 代码
package mysterious;
// -*- coding: utf-8 -*-
// @ Date : 2019/5/20 13:14
// @ Author : RichardLau_Cx
// @ file : Richard.Java
// @ IDE : Educoder
public class Richard_Sort {
public static void main(String[] args) {
// TODO Auto-generated method stub
/*
* 定义三个整数x,y,z,将这三个整数由小到大排序并输出。
* 例如定义 int x = 9; int y = 10; int z = 8; -- > x的值改成8 y的值改成9 z的值改成10
*
* 实现思路:通过if语句对x y z 的值进行匹配,比如x大于y则x和y进行数据交换
* */
java.util.Scanner sc = new java.util.Scanner(System.in);
//获取平台分配的x的值
int x = sc.nextInt();
//获取平台分配的y的值
int y = sc.nextInt();;
//获取平台分配的z的值
int z = sc.nextInt();;
int temp;
// method one
if (x > y)
{
if (x > z)
{
temp = x;
x = z;
z = x;
}
else
{
temp = x;
x = y;
y = temp;
}
}
else if (y > x)
{
if (y > z)
{
temp = y;
y = z;
z = temp;
}
else
{
;
}
}
// method two (同级排序)-- 常用方法
if (x > y)
{
temp = x;
x = y;
y = temp;
}
if (y > z)
{
temp = y;
y = z;
z = temp;
}
if (x > y)
{
temp = x;
x = y;
y = temp;
}
// method three(从大到小排序,阶梯式排序)
if (x > y)
{
if (x > z)
{
if (y > z)
{
System.out.printf("%d,%d,%d\n", x, y, z);
}
else
{
System.out.printf("%d,%d,%d\n", x, z, y);
}
}
else
{
System.out.printf("%d,%d,%d\n", z, x, y);
}
}
else
{
if (y > z)
{
if (x > z)
{
System.out.printf("%d,%d,%d\n", y, x, z);
}
else
{
System.out.printf("%d,%d,%d\n", y, z, x);
}
}
else
{
System.out.printf("%d,%d,%d\n", z, y, x);
}
}
// System.out.print("x:"+x+" y:"+y+" z:"+z);
}
}
- Python 代码
def func_sort_three(x, y, z):
"""
排序三个数的大小(升序)
:param x:
:param y:
:param z:
:return: x, y, z (x < y < y)
"""
x, y = func_sort_two(x, y)
y, z = func_sort_two(y, z)
x, y = func_sort_two(x, y)
return x, y, z
def func_sort_two(x, y):
"""
排序两个数大小(升序)
:param x:
:param y:
:return: x, y (x < y)
"""
if x > y:
temp = x
x = y
y = temp
return x, y
if __name__ == '__main__':
a = int(input())
b = int(input())
c = int(input())
# print(func_sort_two(a, b)) # 输出两个数排序后
print(func_sort_three(a, b, c)) # 输出三个数排序后
2. 计算数组中所有正数,或者所有负数的和
Definition:
正数是数学术语,比0大的数叫正数(positive number),0本身不算正数,也不算负数。正数与负数表示意义相反的量。正数前面常有一个符号“+”,通常可以省略不写,负数是数学术语,比0小的数叫做负数,负数与正数表示意义相反的量。负数用负号(Minus Sign,即相当于减号)“-”和一个正数标记,如−2,代表的就是2的相反数。于是,任何正数前加上负号便成了负数。一个负数是其绝对值的相反数。在数轴线上,负数都在0的左侧,最早记载负数的是我国古代的数学著作《九章算术》。在算筹中规定"正算赤,负算黑",就是用红色算筹表示正数,黑色的表示负数。
Description:如果b为正数,计算a中所有正数的和;如果b是负数,计算a中所有负数的和;
- JavaScript 代码
function mainJs(a,b) {
a = a.split(","); // 将字符串转化为数组
for(var i = 0,length = a.length;i < length;i++) {
a[i] = parseInt(a[i]); // 将字符串数组整数化
}
var sum = 0;
for(var i = 0,length = a.length;i < length;i++)
{
// tedious
if (b > 0)
{
if (a[i] < 0)
continue;
}
if (b < 0)
{
if (a[i] > 0)
continue;
}
// simple
if (b > 0 && a[i] < 0)
continue;
if (b < 0 && a[i] > 0)
continue;
sum += a[i];
}
return sum;
}
Notice:两个负数比较大小,绝对值大的反而小。
3. 求数组中奇数或者偶数元素的个数
Definition:整数可以分成奇数和偶数两大类。能被2整除的数叫做偶数,不能被2整除的数叫做奇数。偶数通常可以用2k(k为整数)表示,奇数则可以用2k+1(k为整数)表示。特别注意:因为0能被2整除,所以0是偶数。
- JavaScript 代码
//求数组中奇数元素的个数
function getOddNumber(a)
{
var result = 0;
for(var i = 0;i < a.length;i++)
{
if(a[i]%2 != 0) // <---
{result++;}
}
return result;
}
//求数组中偶数元素的个数
function getEvenNumber(a)
{
var result = 0;
for(var i = 0;i < a.length;i++)
{
if(a[i]%2 == 0) // <---
{result++;}
}
return result;
Notice:关键在于此数是否能被2整除。
4. 求两数之间的所有整数的和,不包括两个端点
Reference:JavaScript中判断整数的方法
Definition:整数的全体构成整数集,整数集是一个数环。在整数系中,零和正整数统称为自然数。-1、-2、-3、…、-n、…(n为非零自然数)为负整数。则正整数、零与负整数构成整数系。整数不包括小数、分数。
function sum_integer(a,b) {
a = parseInt(a); // 此处已经转换过啦
b = parseInt(b);
// Question:如果两参数不是整数
var i = parseInt(a)+1; // 其实第一步已经变成整数啦
var sum = 0;
if (b-a <= 1)
return 0;
do
{
// method one
if (typeof(i) === 'number' && i%1 == 0)
{ // 先判断是否为数字类型,任何整数都能被一整除
sum += i; // 注意看题目要求!!!
}
// method two
if (Math.floor(i) == i)
{ // Math.floor返回一个小于或等于参数i的最大整数
sum += i;
}
// method three
if (parseInt(i, 10) == i)
{ // 以十进制返回整数
sum += i;
}
// method four
if (i | 0 === i)
{ // 通过位运算实现
sum += i;
}
// method five
if (Number.isInteger(i))
{ // ES6 提供的整数判断方法
sum += i;
}
i++;
} while (i < b);
return (sum);
}
Notice:任何整数都能被一整除。
5. 返回整数a的“倒数”
Definition:定义“倒数”如下:把一个数的各位的顺序颠倒,如1234的“倒数”是4321。
- JavaScript 代码
function num_transpose(a){
a = parseInt(a);
var string_a = a.toString();
//请在此处编写代码
/********** Begin **********/
// method one 转化数组法
var array_num = string_a.split("");
var temp;
var aLength = array_num.length;
for (var i=0; i < parseInt(aLength/2); i++)
{
temp = array_num[i];
array_num[i] = array_num[aLength-i-1];
array_num[aLength-i-1] = temp;
}
array_num = array_num.join("");
return (array_num);
// method two 字符串拼接法
var aLength = string_a.length; // 没有C语言当中的"/0"占位置
var string_total = "";
for (var i=0; i < aLength; i++)
{
string = string_a.slice(i, i+1);
string_total = string + string_total;
}
return (string_total);
// method three 数字倒序叠加法
var aLength = string_a.length; // 没有C语言当中的"/0"占位置
var sum = 0;
var base = 1;
for (var i=0; i < aLength; i++)
{
var num = string_a.slice(i, i+1);
sum = sum + num*base;
base *= 10;
}
return (sum);
}
6. 找出1至1000以内的质数
Definition: 质数:只能被1和它本身整除的数,比如10以内的质数: 2 3 5 7,任何的偶数(除2以外)都是非质数以及奇数1不属于质数(且必须为正数)。
- Java 代码
public static void main(String[] args) {
/*
打印输出质数的时候务必按照如下格式:System.out.print(质数+" ");
使用print进行打印同时被打印输出的质数后加上一个空格,
以便于与平台提供的结果格式保持一致!
*/
int j;
for (int i=0; i < 1000; i++)
{
for (j=2; j < i; j++)
{
if (i%j == 0)
{
break;
}
}
if (i == j)
{
System.out.printf("%d ", i);
}
}
}
6. 求出小于等于整数a的所有质数和
Definition:质数是指在大于1的自然数中,除了1和它本身以外不再有其他因数的自然数。
- JavaScript 代码
function mainJs(a) {
a = parseInt(a);
var num = 3; // 小于a的数,从3开始
var sum_prime = 2; // 质数和,默认含有2
// method one 不把2考虑进循环去
if (a <= 1)
return (0);
else if (a == 2)
return (2);
else
{
while (num <= a)
{
for (var i=2; i < num; i++)
{
if (num % i == 0)
break;
}
if (i == num)
{
sum_prime += num;
}
num++;
}
}
// method two while 和 for 的嵌套使用
var num = 2; // 小于a的数,从2开始,不包括1
var sum_prime = 0; // 质数和
if (a <= 1)
return (0);
else
{
while (num <= a)
{
for (var i=2; i < num; i++)
{
if (num % i == 0)
break;
}
if (i == num)
{
sum_prime += num;
}
num++;
}
}
// method three 单纯的while方法实现
var sum_prime = 0; // a以内质数和
var num = 2; // 从2开始判断
if (a <= 1)
{ // 质数需大于1的自然数
return (0);
}
while (num <= a)
{
var i = 2;
while (i < num)
{
if (num % i == 0)
{ // 如果可以整除,则有其他因数,不是质数
break;
}
i++; // 进一步测试是否为质数
}
if (i == num)
{ // 此期间除了1和本身找不到其他因数
sum_prime += num; // 是质数则加起来
}
num++; // 继续判断下一个数
}
return (sum_prime);
}
7. 计算并返回一组整数的最大值
Definition:最大值,即为已知的数据中的最大的一个值,在数学中,常常会求函数的最大值,一般求解方法有换元法、判别式求法、函数单调性求法、数形结合法和求导方法。
- JavaScript 代码
function getMax()
{
// method one
var aLength = arguments.length;
var max = 0; // 必须初始化对应的数据类型才能合理进行
for (var i=0; i < aLength; i++)
{
if (arguments[i] > max)
{
max = arguments[i];
}
}
// method two
var aLength = arguments.length;
var max = 0; // 必须初始化对应的数据类型才能合理进行
for (var i=0; i < aLength; i++)
{
arguments[i] > max ? max=arguments[i]: null; // null 人为重置为空对象
}
return (max);
// method three
var aLength = arguments.length;
if (aLength == 0) // 注意看题目的每一项要求,此处为第四点
return 0;
var max; // 必须初始化对应的数据类型才能合理进行
// max = Math.max.apply(null, arguments); // ES5
max = Math.max(...arguments); // ES6 最简洁的方法
return (max);
}
function mainJs(a) {
a = parseInt(a);
switch(a) {
case 1:return getMax(23,21,56,34,89,34,32,11,66,3,9,55,123);
case 2:return getMax(23,21,56,34,89,34,32);
case 3:return getMax(23,21,56,34);
case 4:return getMax(23,21,56,34,89,34,32,11,66,3,9,55,123,8888);
case 5:return getMax();
default:break;
}
}
Notice:可以近似的将参数类型相当于数组类型来理解,但实际上并不是。
8. 根据四个正整数,组成互不相同三位数
Description:根据平台提供的四个小于10的正整数,将这些正整数组成互不相同三位数,将满足条件的三位数进行输出!
Thinking:
- 可以通过三层循环的方式,第一层循环用于控制百位数的变化,第二层循环用于控制十位数的变化,第三层循环用于控制个位数的变化。
- 由于题目要求百位数、十位数、个位数互不重复,因此可以在第三层循环中进行判断: 如果 i不等于j并且 j不等于k并且 i不等于k则进行数据的拼装并打印;
- Java 代码
public static void main(String[] args) {
/*
* 假设平台分配的四个整数为 1 2 3 4
* 那么百位有可能是 1 2 3 4 十位:有可能是 1 2 3 4 个位:有可能是 1 2 3 4,
* 要求是 百位 十位 各位上的数字不能重复
* 比如:123 124 132 134 等都满足条件
* 比如:122 131 121 232 等都不满足条件
*
* */
//定义长度为4的int数组
int[] array = new int[4];
// char[] array = new char[4];
//创建Scanner对象获取平台输入的信息
java.util.Scanner sc = new java.util.Scanner(System.in);
//获取平台给定的输入值并填充至数组中
for(int i=0;i<array.length;i++){
array[i] = sc.nextInt();
}
//通过第一层循环控制百位的数字 array[i]表示百位的值
for (int i=0; i < array.length; i++) {
//通过第二层循环控制十位的数字 array[j]表示十位的值
for (int j=0; j < array.length; j++) {
//通过第三层循环控制个位的数字 array[k]表示个位的值
for(int k=0; k < array.length; k++) {
/**********begin**********/
if (array[i]==array[j] || array[j]==array[k] || array[i]==array[k])
{continue;}
// method one
String hundreds = String.valueOf(array[i]);
String decade = String.valueOf(array[j]);
String units = String.valueOf(array[k]);
// method two
// String hundreds = array[i].toString(); // 此方法需建立在数据为对象时才可
// String decade = array[j].toString();
// String units = array[k].toString();
// method three
// String hundreds = String.valueOf(array, i, 1); // 数据为字符数组时使用
// String decade = String.valueOf(array, j, 1);
// String units = String.valueOf(array, k, 1);
System.out.println(hundreds + decade + units);
/**********end**********/
}
}
}
}
9. 打印实心三角形
- Description:编写一个利用for循环打印实心三角形的小程序。
- As shown in the figure:

- Java 代码
public static void main(String[] args)
{
//创建Scanner对象用于获取平台给定的输入信息
java.util.Scanner sc = new java.util.Scanner(System.in);
//定义需要打印的总行数
int lineNum = sc.nextInt();
/*
i(行号) 空格数量(lineNum-i) 星星数量 (2*i -1)
1 5 1
2 4 3
3 3 5
4 2 7
5 1 9
6 0 11
*/
//通过外循环控制需要打印的行数
for(int i=1; i<=lineNum; i++)
{
/**********begin**********/
for (int j=1; j <= lineNum-i; j++)
//通过内循环(1)控制需要打印的空格
{
System.out.print(" ");
}
//通过内循环(2)控制需要打印的星星的数量
for (int k=1; k <= 2*i -1; k++)
{
System.out.print('*');
}
//当前行中的空格以及星星打印完成之后进行换行操作 \n表示换行
System.out.print("\n");
}
}
排序
1. 冒泡排序
- 一趟冒泡排序(针对数值)
先介绍一趟冒泡排序的过程。
以升序为例,从第一个元素开始,将第一个元素与第二个元素比较,如果第一个元素大于第二个元素,交换这两者。
如下图所示,9比5大,交换两者的位置后,9就到后面去了。

然后第二个元素与第三个元素比较,将大的移动到后面;第三个元素与第四个元素比较……,这样一直进行下去,直到倒数第二个元素和最后一个元素进行比较,称为一趟冒泡排序,结束后最大的元素已经移到了索引最大处。下面的图展示了每一次比较并交换后的数组:

可以看到,一趟冒泡排序结束后,最大的元素9移到了索引最大处。
- 冒泡排序全过程
接下来对除了最后一个元素的数组进行第二趟冒泡排序,结果是第二大的元素到了索引第二大的地方。这样一直进行下去,直到整个数组有序或者某一趟排序的时候不存在元素的交换。

第四趟冒泡过程中,未发生元素的交换,结束。
因为排序的原理是不断的把大的数据往上浮动,故而命名为冒泡排序。
- JavaScript 代码
var arr = [5, 2, 0, 1, 3, 1, 4];
var aLength = arr.length;
var temp;
var flag = 0; // 元素交换的标志位
for(var i = 1;i < aLength;i++)
{ // 共进行n-1次冒泡
flag = 0;
for(var j = 0;j < aLength-i;j++)
{ // 一次冒泡
if(arr[j]>arr[j+1])
{ // 交换元素
temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
flag = 1;
}
}
if(flag == 0) break; // 本次冒泡没有元素交换
}
console.log(arr); // 控制台输出排序后的数组
冒泡排序关键在于这两个循环的控制,外层循环控制冒泡的次数,一般是n-1次,n表示数组长度。
内循环j的初值为0,因为不论是第几趟冒泡,都是从arr[0]开始遍历数组,j的上限设置为arr.length-i,因为随着冒泡的进行,越往后需要比较的数组的索引上限越小。
2. 选择排序
-
一趟选择排序(针对下标)
原理:遍历数组,记录下最大元素的索引值,将最大的元素与数组最后一个元素交换,这样最大的元素到了索引值最大的地方,称为一趟选择排序。与冒泡不同的是,只会发生一次交换。

可以看到9移到了索引最大处。 -
选择排序全过程
第二趟选择排序是在除了最后一个元素的数组中选择最大的元素,将它与索引值第二大的元素交换,结束后第二大的元素也到了最终的位置上。这样一直进行下去,一共n-1趟选择排序。

-
动态过程
-
JavaScript 代码
var arr = [9, 5, 8, 0, 2, 6];
var aLength = arr.length;
var temp;
var max = arr[0];
var maxIndex = 0;
for(var i = 0;i < aLength-1;i++)
{ // 共进行n-1次选择
for(var j = 1;j < aLength-i;j++)
{ // 一次选择
if(arr[j] > max)
{
max = arr[j];
maxIndex = j;
}
}
// 将本次选出的最大元素移动到最终的位置上
temp = arr[aLength-i-1];
arr[aLength-i-1] = arr[maxIndex];
arr[maxIndex] = temp;
var max = arr[0];
var maxIndex = 0;
}
console.log(arr); // 控制台输出排序后的数组
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
//动态创建数组
int[] arr = new int[sc.nextInt()];
for(int i = 0 ; i< arr.length ; i++){
arr[i] = sc.nextInt();
}
/********** Begin **********/
// method one
for (int i=0; i < arr.length-1; i++)
{ // 比较趟数
int min = arr[0];
int minIndex = 0;
int temp;
for (int k=1; k < arr.length-i; k++)
{ // 每趟比较次数
if (arr[k] < min)
{
min = arr[k]; // 如果需要此趟最小值,可从这里拿
minIndex = k;
}
}
temp = arr[arr.length-1-i];
arr[arr.length-1-i] = arr[minIndex];
arr[minIndex] = temp;
}
// method two
for (int i=0; i < arr.length-1; i++)
{
for (int j=i; j < arr.length-1; j++)
{
if (arr[i] < arr[j+1])
{ // 相当于从左往右排
int temp = arr[j+1];
arr[j+1] = arr[i];
arr[i] = temp;
}
}
}
System.out.println(Arrays.toString(arr));
}
这里也有两个大循环,第一个循环控制总的排序趟数,第二个循环求本次选择出的最大元素的索引值,第二个循环结束后将本次的最大值与最终位置上的元素交换。
Application:返回选择排序进行过程中,在每一趟交换前,待排序子数组的最大元素的位置组成的数组。
Explain:比如对于上面相关知识中的数组[9,5,8,0,2,6],第一次交换前,最大的元素9的索引是0,第二次交换前,最大元素8的索引是2,第三次交换前最大元素6的索引是0,第四次交换前最大元素5的索引是1,第五次交换前最大元素2的索引是1,第六次交换前最大元素0的索引是0。索引需要返回的数组是[0,2,0,1,1,0];
- JavaScript 代码
function mainJs(a) {
var arr = a.split(","); // 以CSV形式输入,转化为数据数组
for(var i = 0;i < arr.length;i++) {
arr[i] = parseInt(arr[i]);
}
var aLength = arr.length;
// var max = arr[0];
var temp;
var arr_rank = new Array();
for (var i=0; i < aLength-1; i++)
{ // 最外层循环控制总的排序趟数(总数据-1次)
var max = arr[0];
var maxIndex = 0;
for (var j=1; j < aLength-i; j++)
{ // 比较需要从第二个开始至位置排好之前
if (arr[j] > max)
{
max = arr[j];
maxIndex = j; // 选出最大元素的索引坐标
}
}
temp = arr[aLength-i-1]; // 腾出来位置
arr[aLength-i-1] = arr[maxIndex];
arr[maxIndex] = temp;
arr_rank.push(maxIndex);
}
return (arr_rank);
}
矩阵中算法
1. 将一个ndarray类型的数组顺时针旋转90度。
Tip:
-
建议使用外部循环;
-
np.vstack()可以将两个数组竖直堆叠成为新的数组。
-
Python 代码
'''传入的参数为ndarray类型数组'''
def rotate_array(arr):
arr = arr[:: -1]
b = []
for x in np.nditer(arr, flags=['external_loop'], order='F'):
b.append(x)
b = tuple(b)
result = np.vstack(b)
# method two
# flag = 0
# result = []
# for x in np.nditer(arr, flags=['external_loop'], order='F'):
# x = x[:: -1]
# if (flag == 0):
# result = x
# else:
# result = np.vstack((result, x)) # 相当于一层一层往下落
# flag+=1
return result
def main():
arr = eval(input())
print(rotate_array(arr))
if __name__ == '__main__':
main()
模块应用
1. Algorithm模板中的Min/Max应用
- Algorithm模板函数min
在Algorithm模板函数中,关于min的用法主要有两个:基础数据类型的最小值函数和自定义数据类型的最小值函数。基础数据类型指整型int,单精度浮点型float,双精度浮点型double,字符类型char,字符串指针类型char*,字符串对象类型string等数据类型,而自定义的数据类型通常为结构体数据类型。其函数原型如下:
default (1): // 默认的基础数据类型最小值函数
template <class T> const T& min (const T& a, const T& b);
custom (2): // 自定义的数据类型最小值函数
template <class T, class Compare>
const T& min (const T& a, const T& b, Compare comp);
- 介绍默认的基础类型最小值函数及其实战
使用示例如下:
#include - Algorithm模板函数max
最大值函数与最小值函数类似,使用方法也是一样的,也包含两个主要的用法。其函数原型如下:
default (1):
template <class T> const T& max (const T& a, const T& b);
custom (2):
template <class T, class Compare>
const T& max (const T& a, const T& b, Compare comp);
- Algorithm模板函数minmax
特别的,在Algorithm模板函数中还包含一个特殊的函数:最小值最大值函数,它以数据对pair的形式返回两个值:最小值和最大值。同样的,该函数也能处理基础数据类型和自定义数据类型,其函数原型如下:
default (1):
template <class T>
pair <const T&,const T&> minmax (const T& a, const T& b);
custom (2):
template <class T, class Compare>
pair <const T&,const T&> minmax (const T& a, const T& b, Compare comp);
因为minmax的返回值的使用方式比较特殊,通过.first和.second来分别获取最小值和最大值,一个示例如下:
// minmax example
#include - min函数在自定义数据类型下的应用
模板函数min在处理自定义数据类型的时候,需要依据该数据类型的比较规则定义一个比较函数,该比较函数返回比较的真值。比如两个整数a和b:
bool comp(int a, int b){ return a<b;}
int c = min(a, b, comp);
模板函数min处理自定义数据类型的函数原型如下:
template <class T, class Compare>
bool comp(const T& a, const T& b);// 按定义的比较规则返回a
const T& min (const T& a, const T& b, Compare comp);
2. 模板函数sort对学生成绩进行排序
- 自定义数据类型下的排序模板函数sort
Algorithm中的排序函数是基于快速排序算法实现的,复杂度为O(N*logN)。快速排序算法在1962年由C. A. R. Hoare提出,其基本思想是:通过一趟排序将待排序的数据分割成独立的两部分,左边部分的所有数据比右边部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,最后达到整个数据变成有序序列。
模板函数sort具有两种模式,一种是数据之间已有排序规则,比如整型数据、浮点数据,它们的大小比较是确定的;另一种是数据之间没有现成的排序规则,需要自定义排序规则,这类适用于自定义数据类型。它们函数原型如下:
default (1):
template <class RandomAccessIterator>
void sort (RandomAccessIterator first, RandomAccessIterator last);
custom (2):
template <class RandomAccessIterator, class Compare>
void sort (RandomAccessIterator first, RandomAccessIterator last, Compare comp);
- 存储有N个学生信息的结构体数组进行排序,一般有两种方式:
在结构体中重载小于比较符<,因为sort函数默认使用<比较符,只要返回this.score>S.score的比较真值,那么使用sort排序将得到成绩从高到低的排序结果。由此,最后直接调用sort函数对结构体数组进行排序即可:
struct Student{
int numberID;
char name[20];
int score;
bool operator < (const Student &S)const{
//完成结构体比较规则:Student this VS. Student S
//先比较成绩,若成绩相同,则比较学号
}
}
Student student[10];
sort(student, student+10); // 输入取地址范围
实现一个结构体比较函数,然后作为参数传入sort函数完成排序中的结构体间的大小比较:
bool max_cmp(Student S1, Student S2){
//完成结构体比较规则:Student S1 VS. Student S2
//先比较成绩,若成绩相同,则比较学号
}
Student student[10];
sort(student, student+10, max_cmp);
应用算法
1. 统计一段英文文章(a)中单词的个数
Description:一般简单的英文文章当中,只包含“,” 和“ ”。其中逗号分隔句子;而空格则分隔单词。
- JavaScript代码
function statistical_word(a)
{
var array_str1 = a.split(',');
var array_str2 = a.split(" ");
return (array_str1.length + array_str2.length -1);
}
- Example:
// 句子:hello js,js is a domain language is front
['hello js', 'js is a domain language is front'] // amount:2
['hello', 'js,js', 'is', 'a', 'domain', 'language', 'is', 'front'] // amount:8
// 单词数:9
// 句子:If you miss the train I'm on,You will know that I am gone,You can hear the whistle blow
["If you miss the train I'm on", 'You will know that I am gone', 'You can hear the whistle blow'] // amount:3
['If', 'you', 'miss', 'the', 'train', "I'm", 'on,You', 'will', 'know', 'that', 'I', 'am', 'gone,You', 'can', 'hear', 'the', 'whistle', 'blow'] // amount:18
// 单词数:20
// 句子:a,b,c,d,e
['a', 'b', 'c', 'd', 'e'] // amount:5
['a,b,c,d,e'] // amount:1
// 单词数:5
// 句子:This a way,this a way,This a way,this a way,Lord,I can't go home this a way
['This a way', 'this a way', 'This a way', 'this a way', 'Lord', "I can't go home this a way"] // amount:6
['This', 'a', 'way,this', 'a', 'way,This', 'a', 'way,this', 'a', 'way,Lord,I', "can't", 'go', 'home', 'this', 'a', 'way'] // amount:15
// 单词数:20
- 代码解读
-
以逗号分隔为主体,空格分隔为补充。则前者缺少的单词数可以从后者对应找到,只不过前者中每一项的最后一个元素,和下一项的第一个元素在后者中会合并为一项,这个刚好把前者输出的个数没有重复统计,但是,前者第一项的第一个元素(单词),再后者的统计中会多出来这一个,所以最后结果需要减一。
映射关系:

-
以空格分隔为主体,逗号分隔为补充。则前者缺少的单词数可以从后者对应找到,相当于后者单词数的基础上面,有混有逗号的项,需要根据逗号的个数来确定缺少的单词数,一个逗号会对应一个单词,但是句子数刚好比逗号数(单词数)多一,所以,最后结果需要减一。
映射关系:

2. 实现词频统计和排序输出
- 统计相同单词的次数
//使用map集合进行存储
String s="Day by Day";
Map<String,Integer> map=new HashMap<String,Integer>();
StringTokenizer tokenizer=new StringTokenizer(s);
int count;//记录次数
String word;//单个单词
while(tokenizer.hasMoreTokens()){
word=tokenizer.nextToken(" ");
if(map.containsKey(word)){
//拿到之前存在map集合中该单词的次数
count=map.get(word);
map.put(word, count+1);
}else{
map.put(word, 1);
}
}
Set<Entry<String, Integer>> entrySet = map.entrySet();
for (Entry<String, Integer> entry : entrySet) {
System.out.println(entry.getKey()+"-"+entry.getValue());
}
输出:
by-1
Day-2
- 如何进行排序
Introduction:使用Collections包装类。它包含有各种有关集合操作的静态多态方法。
//可根据指定比较器产生的顺序对指定列表进行排序。
Collections.sort(List<T> list, Comparator<? super T> c)
示例如下:
//以上实例中的map集合为例 将map集合的每一项添加进list集合中
List<Map.Entry<String, Integer>> infos = new ArrayList<Map.Entry<String, Integer>>(map.entrySet());
Collections.sort(infos, new Comparator<Map.Entry<String, Integer>>() {
public int compare(Map.Entry<String, Integer> o1,
Map.Entry<String, Integer> o2) {
//前者-后者 升序 后者-前者 降序
return (o2.getValue() - o1.getValue());
}
});
输出:
Day-2
by-1