Spark | SparkSQL架构
目录
SparkSQL
DataFrame API
DataFrame & DataSet & RDD 三者区别
SparkSQL 组成
SparkSQL Catalyst Optimizer
Tree
TreeNode
QueryPlan
Expression
Rule
RuleExecutor
Catalyst大致流程
References
spark.version = 2.4.4
站在上帝角度学习下SparkSQL架构相关内容
SparkSQL
SparkSQL 是一个用于处理结构化数据的Spark组件,结构化数据既可以来自外部结构化数据源,也可以通过向已有RDD增加Schema方式得到。
DataFrame API
通俗点理解也可以说SparkSQL主要完成SQL解析相关工作,将一个SQL语句解析为DataFrame或者RDD任务。
如下图可以看到实际上Spark的Dataframe API底层也是基于Spark的RDD。
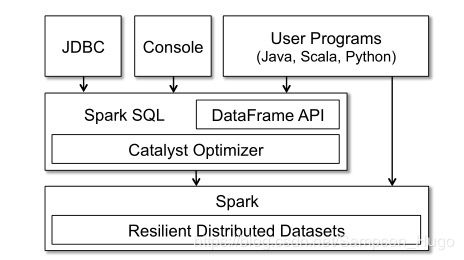
DataFrame 是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。它也支持各种关系操作优化执行,与RDD不同的是,DataFrame带有Schema元数据,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。由于无法知道RDD数据集内部数据结构类型,Spark作业执行只能在调度阶段层面进行简单通用的优化,而对于DataFrame带有数据集内部的结构,可以根据这些信息进行针对性的优化,最终实现优化运行效率。通俗的说SparkSQL能自动优化任务执行过程。
DataFrame & DataSet & RDD 三者区别
RDD 是一个不可变的分布式对象集合,是 Spark 对数据的核心抽象。每个 RDD 都被分为多个分区,每个分区就是一个数据集片段,这些分区运行在集群中的不同节点上。RDD 提供了一种高度受限的内存共享模型,即 RDD 是只读的,只能基于稳定的物理储存中的数据集来创建 RDD 或对已有的 RDD 进行转换操作来得到新的 RDD。
DataFrame 是用在 Spark SQL 中的一种存放 Row 对象的特殊 RDD,是 Spark SQL中的数据抽象,它是一种结构化的数据集,每一条数据都由几个命名字段组成(类似与传统数据库中的表),DataFrame 能够利用结构信息更加高效的存储数据。同时, SparkSQL 为 DataFrame 提供了非常好用的 API,而且还能注册成表使用 SQL 来操作。DataFrame 可以从外部数据源创建,也可以从查询结果或已有的 RDD 创建。
Dataset 是 Spark1.6 开始提供的 API,是 Spark SQL 最新的数据抽象。它把 RDD 的优势(强类型,可以使用 lambda 表达式函数)和 Spark SQL 的优化执行引擎结合到了一起。Dataset 可以从 JVM 对象创建得到,而且可以像 DataFrame 一样使用 API 或 sql 来操作。
三者的关系:RDD + Schema = DataFrame = Dataset[Row]
注:RDD 是 Spark 的核心,DataFrame/Dataset 是 Spark SQL 的核心,RDD 不支持 SQL 操作。
接下来通过简单示例&源码看下三者怎样转换的?
val df:DataFrame = spark.sql(sqlText)
df.printSchema()
val rdd = df.rdd.map(...)
import spark.implicits._
val a = rdd.toDF()
// 首先执行spark.sql()将返回一个DataFrame
def sql(sqlText: String): DataFrame = {
Dataset.ofRows(self, sessionState.sqlParser.parsePlan(sqlText))
}
// 将DataFrame转换为RDD
lazy val rdd: RDD[T] = {
val objectType = exprEnc.deserializer.dataType
rddQueryExecution.toRdd.mapPartitions { rows =>
rows.map(_.get(0, objectType).asInstanceOf[T])
}
}
// 将RDD转换为DataFrame
def toDF(): DataFrame = new Dataset[Row](sparkSession, queryExecution, RowEncoder(schema))
package object sql {
/**
* Converts a logical plan into zero or more SparkPlans. This API is exposed for experimenting
* with the query planner and is not designed to be stable across spark releases. Developers
* writing libraries should instead consider using the stable APIs provided in
* [[org.apache.spark.sql.sources]]
*/
@DeveloperApi
@InterfaceStability.Unstable
type Strategy = SparkStrategy
type DataFrame = Dataset[Row]
}
SparkSQL 组成
SparkSQL由Core、Catalyst、Hive和Hive-Thriftserver这四部分组成。
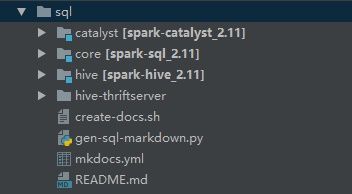
其中:
Catalyst:SparkSQL中的优化器,负责处理查询语句的整个处理过程,包括解析、绑定、优化、物理计划等;
Hive:兼容Hive,支持对Hive数据的处理;
Core:负责处理数据的输入/输出,从不同的数据源获取数据(JSON、RDD、Parquet、CSV)然后将查询结果输出为DataFrame;
Hive-ThriftServer:提供CLI和JDBC/ODBC等;
SparkSQL Catalyst Optimizer
SparkSQL基于Scala函数式编程结构设计了一个可扩展优化器,即Catalyst。这也是SparkSQL中较为核心的内容。
Catalyst支持基于规则和基于成本的优化。
在这个基础上,构建了专门用于关系查询处理的库和若干规则集来处理查询执行不同阶段:分析、逻辑优化、物理规划等。
其次Catalyst核心部分包含一个用于表示树和规则来操作它们。
接下来在讲解SparkSQL运行原理前将简单学习下Tree&Rule这两个重要概念,以及Catalyst大致流程是怎样的。
Tree
Catalyst中的主要数据类型是由节点对象组成的树,是Catalyst执行计划表示的数据结构。
TreeNode
新的节点类型在Scala中定义为TreeNode类的子类,
而Tree的具体操作是通过TreeNode来实现的,LogicalPlans,Expressions和Pysical Operators都可以使用Tree来表示。
Tree具备一些Scala Collection的操作能力和树遍历能力。
在SparkSQL中会根据语法生成一棵树,该树一直在内存里维护,不会保存到磁盘以某种格式的文件存在,且无论是Analyzer分析过的逻辑计划还是Optimizer优化过的逻辑计划,树的修改都是以替换已有节点的方式进行的。这些对象是不可变的,但可以使用函数转换进行操作。
每个节点都有一个节点类型和零个或多个子节点。Tree内部定义了一个children: Seq[BaseType]方法,可以返回一系列孩子节点。
abstract class TreeNode[BaseType <: TreeNode[BaseType]] extends Product {
// scalastyle:on
self: BaseType =>
val origin: Origin = CurrentOrigin.get
/**
* Returns a Seq of the children of this node.
* Children should not change. Immutability required for containsChild optimization
*/
def children: Seq[BaseType]
lazy val containsChild: Set[TreeNode[_]] = children.toSet
......而对Tree的遍历操作,主要是借助各个Tree之间的关系,使用transformDown、transformUp将Rule应用到给定的树段,并匹配节点实施变化的方法。其中transform默认调用transformDown(前序遍历)。
/**
* Returns a copy of this node where `rule` has been recursively applied to the tree.
* When `rule` does not apply to a given node it is left unchanged.
* Users should not expect a specific directionality. If a specific directionality is needed,
* transformDown or transformUp should be used.
*
* @param rule the function use to transform this nodes children
*/
def transform(rule: PartialFunction[BaseType, BaseType]): BaseType = {
transformDown(rule)
}
/**
* Returns a copy of this node where `rule` has been recursively applied to it and all of its
* children (pre-order). When `rule` does not apply to a given node it is left unchanged.
*
* @param rule the function used to transform this nodes children
*/
def transformDown(rule: PartialFunction[BaseType, BaseType]): BaseType = {
val afterRule = CurrentOrigin.withOrigin(origin) {
rule.applyOrElse(this, identity[BaseType])
}
// Check if unchanged and then possibly return old copy to avoid gc churn.
if (this fastEquals afterRule) {
mapChildren(_.transformDown(rule))
} else {
afterRule.mapChildren(_.transformDown(rule))
}
}
/**
* Returns a copy of this node where `rule` has been recursively applied first to all of its
* children and then itself (post-order). When `rule` does not apply to a given node, it is left
* unchanged.
*
* @param rule the function use to transform this nodes children
*/
def transformUp(rule: PartialFunction[BaseType, BaseType]): BaseType = {
val afterRuleOnChildren = mapChildren(_.transformUp(rule))
if (this fastEquals afterRuleOnChildren) {
CurrentOrigin.withOrigin(origin) {
rule.applyOrElse(this, identity[BaseType])
}
} else {
CurrentOrigin.withOrigin(origin) {
rule.applyOrElse(afterRuleOnChildren, identity[BaseType])
}
}
}接下来再来看下TreeNode类的继承体系,如下:
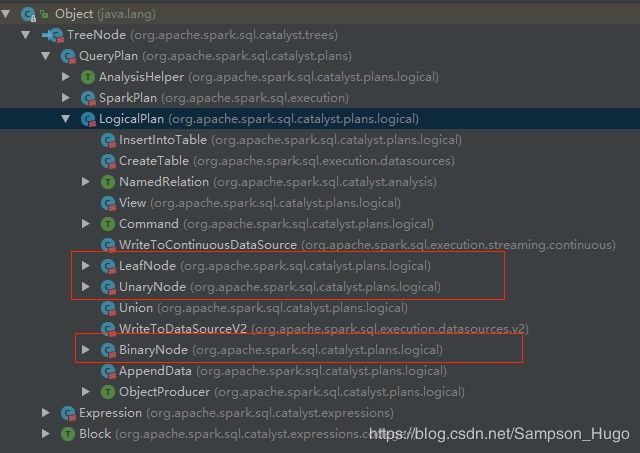
可以看到TreeNode下有两个重要的子类集成体系,分别是:QueryPlan & Expression
QueryPlan
abstract class QueryPlan[PlanType <: QueryPlan[PlanType]] extends TreeNode[PlanType] {
self: PlanType =>
/**
* The active config object within the current scope.
* See [[SQLConf.get]] for more information.
*/
def conf: SQLConf = SQLConf.get
def output: Seq[Attribute]
/**
* Returns the set of attributes that are output by this node.
*/
def outputSet: AttributeSet = AttributeSet(output)
/**
* All Attributes that appear in expressions from this operator. Note that this set does not
* include attributes that are implicitly referenced by being passed through to the output tuple.
*/
def references: AttributeSet = AttributeSet(expressions.flatMap(_.references))
/**
* The set of all attributes that are input to this operator by its children.
*/
def inputSet: AttributeSet =
AttributeSet(children.flatMap(_.asInstanceOf[QueryPlan[PlanType]].output))
/**
* The set of all attributes that are produced by this node.
*/
def producedAttributes: AttributeSet = AttributeSet.empty
/**
* Attributes that are referenced by expressions but not provided by this node's children.
* Subclasses should override this method if they produce attributes internally as it is used by
* assertions designed to prevent the construction of invalid plans.
*/
def missingInput: AttributeSet = references -- inputSet -- producedAttributes
/**
* Runs [[transformExpressionsDown]] with `rule` on all expressions present
* in this query operator.
* Users should not expect a specific directionality. If a specific directionality is needed,
* transformExpressionsDown or transformExpressionsUp should be used.
*
* @param rule the rule to be applied to every expression in this operator.
*/
def transformExpressions(rule: PartialFunction[Expression, Expression]): this.type = {
transformExpressionsDown(rule)
}
/**
* Runs [[transformDown]] with `rule` on all expressions present in this query operator.
*
* @param rule the rule to be applied to every expression in this operator.
*/
def transformExpressionsDown(rule: PartialFunction[Expression, Expression]): this.type = {
mapExpressions(_.transformDown(rule))
}
/**
* Runs [[transformUp]] with `rule` on all expressions present in this query operator.
*
* @param rule the rule to be applied to every expression in this operator.
* @return
*/
def transformExpressionsUp(rule: PartialFunction[Expression, Expression]): this.type = {
mapExpressions(_.transformUp(rule))
}
/**
* Apply a map function to each expression present in this query operator, and return a new
* query operator based on the mapped expressions.
*/
def mapExpressions(f: Expression => Expression): this.type = {
var changed = false
@inline def transformExpression(e: Expression): Expression = {
val newE = CurrentOrigin.withOrigin(e.origin) {
f(e)
}
if (newE.fastEquals(e)) {
e
} else {
changed = true
newE
}
}
def recursiveTransform(arg: Any): AnyRef = arg match {
case e: Expression => transformExpression(e)
case Some(value) => Some(recursiveTransform(value))
case m: Map[_, _] => m
case d: DataType => d // Avoid unpacking Structs
case stream: Stream[_] => stream.map(recursiveTransform).force
case seq: Traversable[_] => seq.map(recursiveTransform)
case other: AnyRef => other
case null => null
}
val newArgs = mapProductIterator(recursiveTransform)
if (changed) makeCopy(newArgs).asInstanceOf[this.type] else this
}
/**
* Returns the result of running [[transformExpressions]] on this node
* and all its children.
*/
def transformAllExpressions(rule: PartialFunction[Expression, Expression]): this.type = {
transform {
case q: QueryPlan[_] => q.transformExpressions(rule).asInstanceOf[PlanType]
}.asInstanceOf[this.type]
}
/** Returns all of the expressions present in this query plan operator. */
final def expressions: Seq[Expression] = {
// Recursively find all expressions from a traversable.
def seqToExpressions(seq: Traversable[Any]): Traversable[Expression] = seq.flatMap {
case e: Expression => e :: Nil
case s: Traversable[_] => seqToExpressions(s)
case other => Nil
}
productIterator.flatMap {
case e: Expression => e :: Nil
case s: Some[_] => seqToExpressions(s.toSeq)
case seq: Traversable[_] => seqToExpressions(seq)
case other => Nil
}.toSeq
}
...... // 其它代码省略 QueryPlan下也有两个重要子类,分别是LogicalPlan(逻辑执行计划) & SparkPlan(物理执行计划)。
LogicalPlan(逻辑执行计划)
LogicalPlan内部提供了resolve(nameParts: Seq[String],resolver: Resolver): Option[NamedExpression]方法,用于分析生成对应的NamedExpression。
abstract class LogicalPlan
extends QueryPlan[LogicalPlan]
with AnalysisHelper
with LogicalPlanStats
with QueryPlanConstraints
with Logging {
/**
* Optionally resolves the given strings to a [[NamedExpression]] based on the output of this
* LogicalPlan. The attribute is expressed as string in the following form:
* `[scope].AttributeName.[nested].[fields]...`.
*/
def resolve(
nameParts: Seq[String],
resolver: Resolver): Option[NamedExpression] =
outputAttributes.resolve(nameParts, resolver)其次LogicalPlan也有许多具体子类,包括UnaryNode、BinaryNode、LeafNode三种特质(trait),如下:
UnaryNode:一元节点,即只有一个子节点;
BinaryNode:二元节点,即有左右子节点的二叉节点;
LeafNode:叶子节点,没有子节点的节点;
针对不同的Node,Tree提供了不同的操作方法。例如UnaryNode可以进行limit和filter等;对BinaryNode可以进行join和union等操作;对LeafNode主要是用户命令类操作,如set和command等。
SparkPlan(物理执行计划)
abstract class SparkPlan extends QueryPlan[SparkPlan] with Logging with Serializable {
/**
* A handle to the SQL Context that was used to create this plan. Since many operators need
* access to the sqlContext for RDD operations or configuration this field is automatically
* populated by the query planning infrastructure.
*/
@transient final val sqlContext = SparkSession.getActiveSession.map(_.sqlContext).orNullExpression
/**
* An expression in Catalyst.
*
* If an expression wants to be exposed in the function registry (so users can call it with
* "name(arguments...)", the concrete implementation must be a case class whose constructor
* arguments are all Expressions types. See [[Substring]] for an example.
*
* There are a few important traits:
*
* - [[Nondeterministic]]: an expression that is not deterministic.
* - [[Unevaluable]]: an expression that is not supposed to be evaluated.
* - [[CodegenFallback]]: an expression that does not have code gen implemented and falls back to
* interpreted mode.
*
* - [[LeafExpression]]: an expression that has no child.
* - [[UnaryExpression]]: an expression that has one child.
* - [[BinaryExpression]]: an expression that has two children.
* - [[TernaryExpression]]: an expression that has three children.
* - [[BinaryOperator]]: a special case of [[BinaryExpression]] that requires two children to have
* the same output data type.
*
*/
abstract class Expression extends TreeNode[Expression] {Expression是表达式体系,是指不需要执行引擎计算,而可以直接计算或处理的节点,包括Cast操作、Projection操作、四则运算和逻辑操作符运算等。
Rule
先看下Rule的定义
abstract class Rule[TreeType <: TreeNode[_]] extends Logging {
/** Name for this rule, automatically inferred based on class name. */
val ruleName: String = {
val className = getClass.getName
if (className endsWith "$") className.dropRight(1) else className
}
def apply(plan: TreeType): TreeType
}
Rule是一个抽象类,子类需要复写apply方法来制定处理逻辑。
RuleExecutor
对于Rule的具体实现是通过RuleExecutor来完成的,凡是需要处理执行计划树进行实施规则匹配和节点处理的,都需要继承RuleExecutor抽象类。
abstract class RuleExecutor[TreeType <: TreeNode[_]] extends Logging {
/**
* An execution strategy for rules that indicates the maximum number of executions. If the
* execution reaches fix point (i.e. converge) before maxIterations, it will stop.
*/
abstract class Strategy { def maxIterations: Int }
/** A strategy that only runs once. */
case object Once extends Strategy { val maxIterations = 1 }
/** A strategy that runs until fix point or maxIterations times, whichever comes first. */
case class FixedPoint(maxIterations: Int) extends Strategy
/** A batch of rules. */
protected case class Batch(name: String, strategy: Strategy, rules: Rule[TreeType]*)
/** Defines a sequence of rule batches, to be overridden by the implementation. */
protected def batches: Seq[Batch]
/**
* Defines a check function that checks for structural integrity of the plan after the execution
* of each rule. For example, we can check whether a plan is still resolved after each rule in
* `Optimizer`, so we can catch rules that return invalid plans. The check function returns
* `false` if the given plan doesn't pass the structural integrity check.
*/
protected def isPlanIntegral(plan: TreeType): Boolean = true
/**
* Executes the batches of rules defined by the subclass. The batches are executed serially
* using the defined execution strategy. Within each batch, rules are also executed serially.
*/
def execute(plan: TreeType): TreeType = {
var curPlan = plan
val queryExecutionMetrics = RuleExecutor.queryExecutionMeter
batches.foreach { batch =>
val batchStartPlan = curPlan
var iteration = 1
var lastPlan = curPlan
var continue = true
// Run until fix point (or the max number of iterations as specified in the strategy.
while (continue) {
curPlan = batch.rules.foldLeft(curPlan) {
case (plan, rule) =>
val startTime = System.nanoTime()
val result = rule(plan)
val runTime = System.nanoTime() - startTime
if (!result.fastEquals(plan)) {
queryExecutionMetrics.incNumEffectiveExecution(rule.ruleName)
queryExecutionMetrics.incTimeEffectiveExecutionBy(rule.ruleName, runTime)
logTrace(
s"""
|=== Applying Rule ${rule.ruleName} ===
|${sideBySide(plan.treeString, result.treeString).mkString("\n")}
""".stripMargin)
}
queryExecutionMetrics.incExecutionTimeBy(rule.ruleName, runTime)
queryExecutionMetrics.incNumExecution(rule.ruleName)
// Run the structural integrity checker against the plan after each rule.
if (!isPlanIntegral(result)) {
val message = s"After applying rule ${rule.ruleName} in batch ${batch.name}, " +
"the structural integrity of the plan is broken."
throw new TreeNodeException(result, message, null)
}
result
}
iteration += 1
if (iteration > batch.strategy.maxIterations) {
// Only log if this is a rule that is supposed to run more than once.
if (iteration != 2) {
val message = s"Max iterations (${iteration - 1}) reached for batch ${batch.name}"
if (Utils.isTesting) {
throw new TreeNodeException(curPlan, message, null)
} else {
logWarning(message)
}
}
continue = false
}
if (curPlan.fastEquals(lastPlan)) {
logTrace(
s"Fixed point reached for batch ${batch.name} after ${iteration - 1} iterations.")
continue = false
}
lastPlan = curPlan
}
if (!batchStartPlan.fastEquals(curPlan)) {
logDebug(
s"""
|=== Result of Batch ${batch.name} ===
|${sideBySide(batchStartPlan.treeString, curPlan.treeString).mkString("\n")}
""".stripMargin)
} else {
logTrace(s"Batch ${batch.name} has no effect.")
}
}
curPlan
}
}在RuleExecutor类继承体系中,也有两个重要的实现子类,分别是Analyzer & Optimizer。
这两个类中都会定义Batch、Once和FixedPoint。其中每个Batch代表着一套规则,这样可以简便地、模块化地对Tree进行Transform操作。Onec和FixedPoint是配备的策略,相对应的是对Tree进行一次操作或多次的迭代操作。(如对某些Tree进行多次迭代操作时,达到FixedPoint次数或达到前后两次的树结构没变化才停止操作)。
RuleExecutor内部有一个Seq[Batch]属性,定义的是该RuleExecutor的处理逻辑,具体的处理逻辑由具体的Rule子类实现。
RuleExecutor中的apply方法会按照Batch顺序和Batch内的Rules顺序,对传入的节点进行迭代操作。
在Analyzer过程中处理由解析器(SqlParser)生成的未绑定逻辑计划Tree时,就定义了多种Rules应用到该Unresolved逻辑计划Tree上。Analyzer过程中使用了自身定义的多个Batch,如MultiInstanceRelations,Resolution,CheckAnalysis和AnalysisOperators.
每个Batch又由不同的Rules构成,每个Rule又有自己相对应的处理函数。注意,不同Rule的使用次数不同(Once FixedPoint)。
Catalyst大致流程
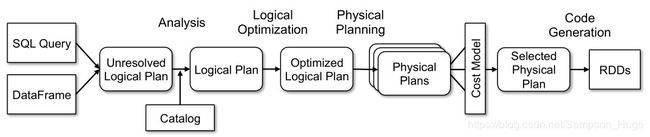
1、将SQL语句通过词法和语法解析生成未绑定的逻辑执行计划(Unresolved LogicalPlan),包含Unresolved Relation、Unresolved Function和Unresolved Attribute,然后在后续步骤中使用不同的Rule应用到该逻辑计划上
2、Analyzer使用Analysis Rules,配合元数据(如SessionCatalog 或是 Hive Metastore等)完善未绑定的逻辑计划的属性而转换成绑定的逻辑计划。具体流程是县实例化一个Simple Analyzer,然后遍历预定义好的Batch,通过父类Rule Executor的执行方法运行Batch里的Rules,每个Rule会对未绑定的逻辑计划进行处理,有些可以通过一次解析处理,有些需要多次迭代,迭代直到达到FixedPoint次数或前后两次的树结构没变化才停止操作。
3、Optimizer使用Optimization Rules,将绑定的逻辑计划进行合并、列裁剪和过滤器下推等优化工作后生成优化的逻辑计划。
4、Planner使用Planning Strategies,对优化的逻辑计划进行转换(Transform)生成可以执行的物理计划。根据过去的性能统计数据,选择最佳的物理执行计划CostModel,最后生成可以执行的物理执行计划树,得到SparkPlan。
5、在最终真正执行物理执行计划之前,还要进行preparations规则处理,最后调用SparkPlan的execute执行计算RDD。
References
Spark SQL:Relational Data Processing in Spark