概率数据结构---Bloom filter(布隆过滤器)
一、简介
When main-stream data structures like Lists, Maps, Sets, Trees etc. are mostly used for achieving certain results about whether the data exist or not, maybe along with their number of occurrences and such, Probabilistic data structures will give you memory-efficient, faster result with a cost of providing a ‘probable’ result instead of a ‘certain’ one.
译:当我们使用主流数据结构如 Lists, Maps, Sets, Trees等等时,我可以得到确切的结果(certain results),无论这个数据存在或是不存在。或许在数据出现次数得记录方面,概率数据结构(Probabilistic data structures)能够提供一种基于内存的,快速的查找出一种可能而非确切的结果。
这种概率数据结构就是布隆过滤器(Bloom filter)。
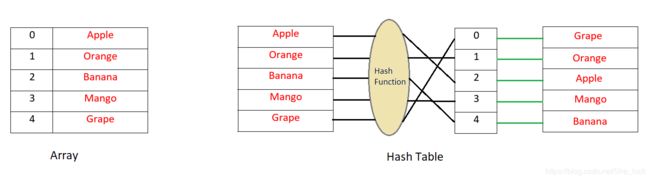
Do you know how hash tables work? When you insert a new data in a simple array or list, the index, where this data would be inserted, is not determined from the value to be inserted. That means there is no direct relationship between the ‘key(index)’ and the ‘value(data)’. As a result, if you need to search for a value in the array you have to search in all of the indexes. Now, in hash tables, you determine the ‘key’ or ‘index’ by hashing the ‘value’. Then you put this value in that index in the list. That means the ‘key’ is determined from the ‘value’ and every time you need to check if the value exists in the list you just hash the value and search on that key. It’s pretty fast and will require O(1) searching time in Big-O notation.
译:你们知道 hash 表吗?当你往 array 或者 list 中插入一条新的数据时,这个数据将要插入的index索引,不是由value决定的。这表明这个key(index)和我们插入的value(data)没有直接联系。也就是说,当你需要在这个array 或者 list 查找一个数据时,你不得不遍历所有的index索引,直到查到数据(时间复杂度为O(n))。现在,在hash 表中,这个key(index)是通过value(data)经过hash算法后得到的,然后将这个数据插入到这个index索引的list中。这表明你可以通过由value决定的这个key很容易查询出这个value在list中是否存在。时间复杂度为 O(1) 。
By definition, Bloom filter can check for if a value is ‘possibly in the set’ or ‘definitely not in the set’. The subtle difference between ‘possibly’ and ‘definitely not’ — is very crucial here. This ‘possibly in the set’ is exactly why it is called probabilistic. Using smart words it means that false positive is possible (there can be cases where it falsely thinks that the element is positive) but false negative is impossible.
译:根据定义,布隆过滤器可以检查值是“可能在集合中”还是“绝对不在集合中”。“可能”与“绝对不是”之间的细微差别在这里至关重要。错误的真值(false positive)是可能的,但是错误的假值( false negative)是不可能出现的。
二、Bloom过滤器
定义
Bloom过滤器实质上由长度为m的位向量或位列表(仅包含0或1位值的列表)组成,最初所有值均设置为0,如下所示:

在哈希表中,我们使用单个哈希函数,因此仅获得单个索引作为输出。
但是对于Bloom过滤器,我们将使用多个哈希函数,这将为我们提供多个索引。
插入操作

如上图,对于给定的输入“geeks”,我们的3个散列函数将提供3个不同的输出1、4和7。我们已对其进行了标记。

对于另一个输入“nerd”,哈希函数给我们3、4和5。您可能已经注意到,索引“ 4”已经被先前的“geeks”输入标记了。(你肯定又疑问,继续看)
查找
我们已经用两个输入填充了位向量,现在我们可以检查它是否存在。我们该怎么做?
我们将使用3个哈希函数对 要搜索的值 进行哈希处理,然后查看保留的结果是什么。
比如,搜索“cat”,我们的哈希函数这次给了我们1、3和7。如下图:

而且我们可以看到所有索引都已标记为1。这意味着我们可以说,“也许’cat’已经插入到我们的列表中了”。但事实并非如此。所以,出了什么问题?
实际上,没有错。问题是,“误报”(false positive)就是这种情况。
布隆过滤器告诉我们,似乎之前已经插入了“cat”,因为应该用“cat”标记的索引已经被标记了(尽管是由于其他不同的数据)。
那么,是的,它有什么帮助?
好吧,让我们考虑一下,如果“猫”给我们的输出是1,6,7而不是1,3,7。那会发生什么呢?我们可以看到,在3个索引中,有6个是“ 0”,这意味着它没有被任何先前的输入标记。这显然意味着以前从未插入过“cat”,如果是的话,则不可能有6成为“ 0”,对吧?这样,bloom过滤器可以“确定”地判断列表中是否没有数据。
简而言之:
- 如果我们搜索一个值,并且发现该值的任何哈希索引为“ 0”,那么该值肯定不在列表中。
- 如果所有散列索引均为“ 1”,则“也许”搜索到的值在列表中。
应用场景
1、检查用户输入的密码是否为弱密码(weak password ),比如123456这种被成为是弱密码。
可以在启动项目的时候,将弱密码库中的所有数据查出来放到Bloom filter中,
当校验是否为弱密码时,先去Bloom filter中校验,如果不存在,则表明为非弱密码,如果存在,由于会出现误报(false positive)情况,这个时候,可以去库里面查询是否真的存在然后返回结果。这样可以大大提供效率。
如下图表示如密码校验流程:

2、redis穿透解决方案
影响因素
综上,有两个变量会影响到Bloom filter的效率。
- hash表的长度,hash表很短的话,如果插入的值足够多,可能使得hash表中所有的值都变成了1。那么接下来再做查询使得所有的查询都会误报,即结果都会是存在。因此我们可以根据“误报错误率”将布隆过滤器调整为需要的精度。
- hash函数的个数,显然hash函数越多,准确率越高,但是同时也会拖慢查询效率。
如下图:
- k表示函数,函数越多,误报率越低。
- m表示hash表长度,hash表越长,误报率越低。

参考文档:
- https://hackernoon.com/probabilistic-data-structures-bloom-filter-5374112a7832
- https://www.jasondavies.com/bloomfilter/
实践
1、添加依赖:
com.google.guava
guava
22.0
2、redis伪代码:
String get(String key) {
String value = redis.get(key);
if (value == null) {
if(!bloomfilter.mightContain(key)){ //不存在则返回
return null;
}else{ //可能存在,则要查询数据库
value = db.get(key);
redis.set(key, value);
}
}
return value;
}