爬取抖音品牌热DOU榜数据
抖音品牌热DOU榜
- 第一步:fiddler抓包和分析
- 第二步:撸代码
抖音是当前很火的一款短视频分享软件,我身边就有很多人是严重的抖音迷,抖音带来的流量是巨大的,那么抖音运营也自然地应运而生了。抖音上有多种排行榜,有明星榜,热点榜呀还有好物榜,还有品牌热DOU榜反映了多种品牌在抖音上的热度,这些排行榜的数据爬取方法大同小异,本文就针对品牌热DOU榜的【‘汽车’,‘手机’,‘美妆’,‘奢侈品’,‘食品饮料’,‘家用电器’,‘服装鞋帽’】几十个周期的数据进行爬取:
品牌热DOU榜介绍: 抖音方面表示,品牌热DOU榜是基于抖音指数为品牌打造的榜单,旨在反映品牌在抖音上的传播声量,让品牌随时了解自身在抖音的热度影响力,以及大众对于品牌的敏感度,为品牌建立长效的品牌营销认知。目前,榜单涵盖汽车、美妆和手机,食品饮料、服饰、奢侈品、家电等多个行业。
不扯了~
进入正题
主要过程:这里使用fiddler抓抖音app的包,然后对关键字进行搜索,找到相关url,对url进行分析,找出每个分类和周期的url,然后就可以撸代码了。爬取抖音排行榜的数据比较简单,因为爬取过程没有什么反爬手段,每个分类几十个周期的数据量大约是1200-1650条,所以总共大约有一万条数据吧,数据量不多,很快就抓取完毕,存储在为7个excel表格当中。
第一步:fiddler抓包和分析
fiddler的安装和配置网上教程很多,这里就不赘述了~
首先打开fiddler和抖音app,抖音的‘品牌热DOU榜介绍’在这里跟我来:
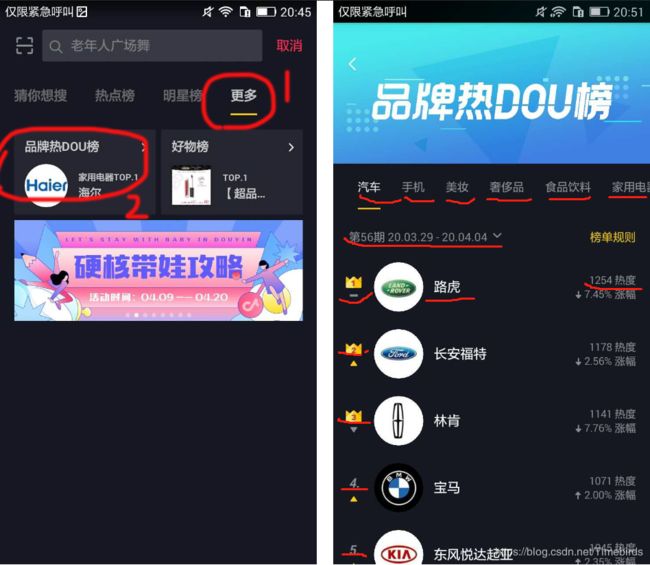
接下来看fiddler,ctrf+F搜索在上图中汽车类‘路虎’,在fiddler中找到了一条url,
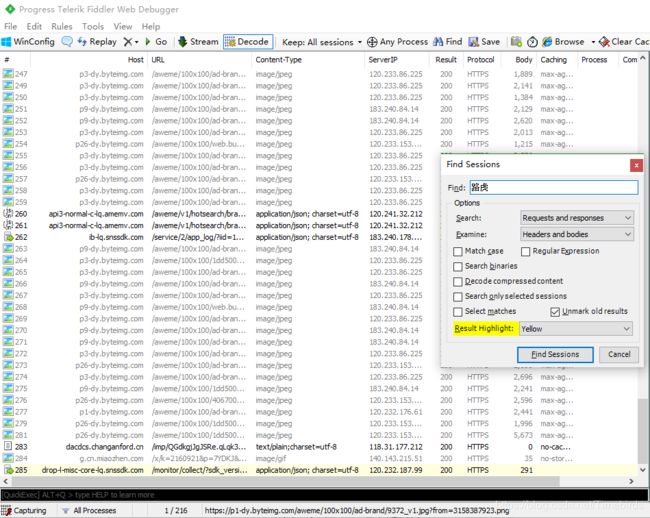
查看网页内容,证实了这条url就是汽车第56期排行榜:

接下来再继续分析其它周期的url,发现除了最新一期的url不同之外,其它url都是仅仅start_date不同(我这里就懒得搞了,舍弃最新一期的排行),那所有的start_date可能就藏在某个链接中,接下来在fiddler中查找日期start_date,果然找到了一个当中包含所有start_date的url:
https://api3-normal-c-lq.amemv.com/aweme/v1/hotsearch/brand/weekly/list/?request_tag_from=rn&category_id=1&openudid=582d0d342f5d6e54&version_name=10.1.0&cdid=9dbc4bc4-9aef-4df4-bc0b-8c22f1169e79&ts=1586695602&device_type=CHM-TL00H&ssmix=a&iid=106833430932&app_type=normal&os_api=19&device_id=11104415474&resolution=720*1280&device_brand=Honor&aid=1128&manifest_version_code=100101&app_name=aweme&_rticket=1586695605103&os_version=4.4.2&device_platform=android&version_code=100100&update_version_code=10109900&ac=wifi&dpi=320&uuid=868090023391404
网页内容:
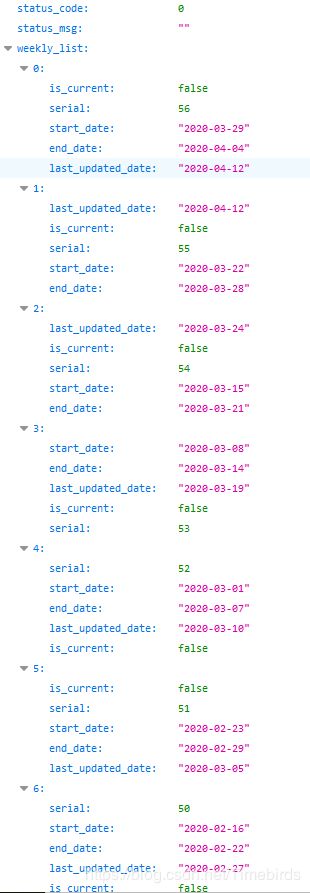
然后以此规律,分析分析分析其它类型总周期的url,发现区别仅仅在category_id:
第二步:撸代码
导入相关库
"""
获取每周期的唯一标识:api: https://api3-normal-c-lq.amemv.com/aweme/v1/hotsearch/brand/weekly/list/?request_tag_from=rn&category_id=6&openudid=582d0d342f5d6e54&version_name=10.1.0&cdid=9dbc4bc4-9aef-4df4-bc0b-8c22f1169e79&ts=1586695602&device_type=CHM-TL00H&ssmix=a&iid=106833430932&app_type=normal&os_api=19&device_id=11104415474&resolution=720*1280&device_brand=Honor&aid=1128&manifest_version_code=100101&app_name=aweme&_rticket=1586695605103&os_version=4.4.2&device_platform=android&version_code=100100&update_version_code=10109900&ac=wifi&dpi=320&uuid=868090023391404
每个分类的总周期数的url区别在category_id,分别为1-7
汽车api:'https://api3-normal-c-lq.amemv.com/aweme/v1/hotsearch/brand/billboard/?request_tag_from=rn&category_id=1&is_by_device=true&start_date={填入start_date}&openudid=582d0d342f5d6e54&version_name=10.1.0&cdid=9dbc4bc4-9aef-4df4-bc0b-8c22f1169e79&ts=1586697098&device_type=CHM-TL00H&ssmix=a&iid=106833430932&app_type=normal&os_api=19&device_id=11104415474&resolution=720*1280&device_brand=Honor&aid=1128&manifest_version_code=100101&app_name=aweme&_rticket=1586697101197&os_version=4.4.2&device_platform=android&version_code=100100&update_version_code=10109900&ac=wifi&dpi=320&uuid=868090023391404'
"""
import requests
import csv,codecs
传入id用于构造每期url链接
def weeks_url(id):
"""
id为每个分类的category_id
获取每周期的唯一标识,用于构建每一周期的url链接
"""
car_weeks_api='https://api3-normal-c-lq.amemv.com/aweme/v1/hotsearch/brand/weekly/list/?request_tag_from=rn&category_id={}&openudid=582d0d342f5d6e54&version_name=10.1.0&cdid=9dbc4bc4-9aef-4df4-bc0b-8c22f1169e79&ts=1586695602&device_type=CHM-TL00H&ssmix=a&iid=106833430932&app_type=normal&os_api=19&device_id=11104415474&resolution=720*1280&device_brand=Honor&aid=1128&manifest_version_code=100101&app_name=aweme&_rticket=1586695605103&os_version=4.4.2&device_platform=android&version_code=100100&update_version_code=10109900&ac=wifi&dpi=320&uuid=868090023391404'.format(id)
res=requests.get(car_weeks_api)
if res.status_code==200:
data=res.json()
data_list=data.get('weekly_list')
return data_list
获取每周排行的页面源代码
def week_ranking(id,start_date):
#获取每周排行的页面源代码
car_url='https://api3-normal-c-lq.amemv.com/aweme/v1/hotsearch/brand/billboard/?request_tag_from=rn&category_id={}&is_by_device=true&start_date={}&openudid=582d0d342f5d6e54&version_name=10.1.0&cdid=9dbc4bc4-9aef-4df4-bc0b-8c22f1169e79&ts=1586697098&device_type=CHM-TL00H&ssmix=a&iid=106833430932&app_type=normal&os_api=19&device_id=11104415474&resolution=720*1280&device_brand=Honor&aid=1128&manifest_version_code=100101&app_name=aweme&_rticket=1586697101197&os_version=4.4.2&device_platform=android&version_code=100100&update_version_code=10109900&ac=wifi&dpi=320&uuid=868090023391404'.format(id,start_date)
res=requests.get(car_url)
if res.status_code==200:
return res.json()
解析页面内容
def parse_detail(rank_data):
#解析提取内容
week_info=rank_data['weekly_info']
serial = week_info['serial'] # 第几期
date=week_info['start_date']+'至'+week_info['end_date'] #起始和终止日期
brand_list=rank_data['brand_list']
data=[]
for i in brand_list:
name=i['name'] #名字
heat=i['heat'] #热度
rank=i['rank'] #排行第几
data.append({
'name':name,
'heat':heat,
'rank':rank,
'week':serial,
'date':date
})
return data
定义下载函数
def download(data,type_name):
#写入excel文件中
with codecs.open(type_name+'.csv','a',encoding='utf_8_sig') as f:
f_csv=csv.writer(f,dialect='excel')
f_csv.writerow(['name','heat','rank','week','date'])
for i in data:
f_csv.writerow([i['name'],i['heat'],i['rank'],'第'+str(i['week'])+'期',i['date']])
def run():
types=['汽车','手机','美妆','奢侈品','食品饮料','家用电器','服装鞋帽']
for id in range(1,8):
data_list = weeks_url(id)[0:3]
for l in data_list:
try:
start_date = l['start_date']
rank_data = week_ranking(id,start_date)
data=parse_detail(rank_data)
download(data,types[id-1])
except:
print('下载失败')
最后运行一下,下载在7个csv文件中: