sklearn_onehot编码与pandas中的onehot编码处理方式
一、One-Hot Encoding
One-Hot
编码,又称为一位有效编码,主要是采用 位状态寄存器来对个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
位状态寄存器来对个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
位状态寄存器来对个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
离散特征的编码分为两种情况:
1、离散特征的取值之间没有大小的意义,比如color:[red,blue],那么就使用one-hot编码
2、离散特征的取值有大小的意义,比如size:[X,XL,XXL],那么就使用数值的映射{X:1,XL:2,XXL:3}
在实际的机器学习的应用任务中,特征有时候并不总是连续值,有可能是一些分类值,如性别可分为“
male
”和“
female
”。在机器学习任务中,对于这样的特征,通常我们需要对其进行特征数字化,如下面的例子:
有如下三个特征属性:
- 性别:["male","female"] # 所有可能取值,0,1 两种情况
- 地区:["Europe","US","Asia"] #0,1,2 三种情况
- 浏览器:["Firefox","Chrome","Safari","Internet Explorer"] #0,1,2,3四种情况
- 所以样本的第一维只能是0或者1,第二维是0,1,2三种情况中的一种,第三维,是0,1,2,3四种情况中的一种。
二、One-Hot Encoding的处理方法
对于上述的问题,性别的属性是二维的,同理,地区是三维的,浏览器则是思维的,这样,我们可以采用One-Hot编码的方式对上述的样本“["male","US","Internet Explorer"]”编码,“male”则对应着[1,0],同理“US”对应着[0,1,0],“Internet Explorer”对应着[0,0,0,1]。则完整的特征数字化的结果为:[1,0,0,1,0,0,0,0,1]。这样导致的一个结果就是数据会变得非常的稀疏。
三、实际的Python代码
from sklearn import preprocessing
enc = preprocessing.OneHotEncoder()
enc.fit([[0,0,3],[1,1,0],[0,2,1],[1,0,2]]) #列表中代表四个样本
array = enc.transform([[0,1,3]]).toarray()
print(array) 理解: 也就是每一维有多少种情况就编码成0到 多少减一的数
[[0,0,3],[1,1,0],[0,2,1],[1,0,2]][0,0,3] #表示是该样本是,male Europe Internet Explorer
[1,1,0] #表示是 female,us Firefox
[0,2,1]#表示是 male Asia Chrome
[1,0,2] #表示是 female Europe Safari
摘自:https://blog.csdn.net/google19890102/article/details/44039761
具体参考:http://scikit-learn.org/stable/modules/preprocessing.html#encoding-categorical-features
此外也可以直接使用pandas 对数据进行onehot编码:
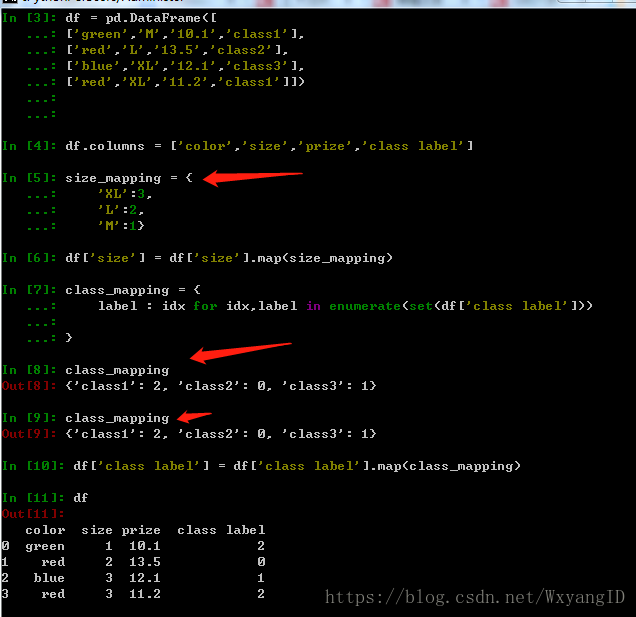
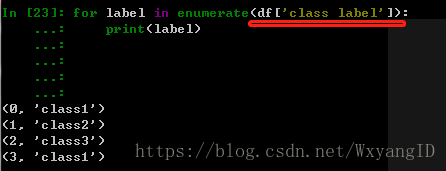
class_mapping中必须是set 否则就会对每一个属性编码,包括重复的属性。
如果直接使用get_dummies(df)则会为每一个唯一的属性值创建一列
