写一个夸夸机器人
前段时间夸夸群火热,试着用几种不同方式写一个夸夸机器人。
项目地址https://github.com/xiaopangxia/kuakua_robot。
语料
做聊天机器人需要训练语料,事实上笔者本想潜伏在一些夸夸群里收集,后拉发现这些夸夸群日渐不活跃了,语料的质量也比较差,于是还是去爬了豆瓣表扬小组的数据,收集的语料地址https://github.com/xiaopangxia/kuakua_corpus。
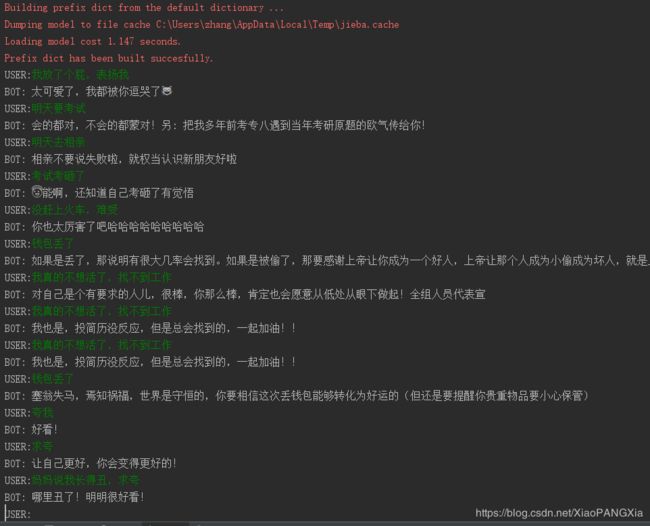
基于文本相似度
相似度用的是传统离散词袋,采用TF-IDF、LSI、LDA模型等,搜索top4相似话题的回复,从中随机返回表扬语句,效果还不错,能够有一定针对性地夸人。
import random
from zhcnSegment import zhcnSeg
from sentenceSimilarity import SentenceSimilarity
class kuakuaChat():
def __init__(self):
"""
初始化夸夸话题回复表
"""
self.qa_dict = {}
self.q_list = []
with open('./douban_kuakua_topic.txt', 'r', encoding='utf8') as in_file:
for line in in_file.readlines():
que = line.split('<######>')[0].strip()
ans_list = []
for ans in line.split('<######>')[-1].split('<$$$$$$>'):
if len(ans) > 2:
ans_list.append(ans)
if len(que)>5:
self.q_list.append(que)
self.qa_dict[que] = ans_list
zhcn_seg = zhcnSeg()
self.sent_sim = SentenceSimilarity(zhcn_seg)
self.sent_sim.set_sentences(self.q_list)
# 默认用tfidf
self.sent_sim.TfidfModel()
def answer_question(self, question_str):
"""
返回与输入问句最相似的问句的固定回答
:param question_str:
:return:
"""
most_sim_questions = self.sent_sim.similarity_top_k(question_str, 4)
answer_list = []
for item in most_sim_questions:
answer = self.qa_dict[item[0]]
answer_list += answer
return answer_list
if __name__ == '__main__':
test_bot = kuakuaChat()
while True:
try:
user_input = input('USER:')
answer_list = test_bot.answer_question(user_input)
response = random.choice(answer_list)
print('BOT:', response)
# 直到按ctrl-c 或者 ctrl-d 才会退出
except (KeyboardInterrupt, EOFError, SystemExit):
break
尝试用chatterbot
做聊天机器人有一些现成的库可以用,任务型机器人可能考虑用aiml然后写模板,闲聊机器人有一个比较流行的chatterbot的库,拿它来训练一个机器人看看。
from chatterbot import ChatBot
from chatterbot.trainers import ChatterBotCorpusTrainer
import json
class kuakuaChat():
@classmethod
def corpus_convert(cls):
"""
格式转化,将夸夸语料转成chatterbot训练语料
:return:
"""
dialog_list = []
with open('douban_kuakua_qa.txt', 'r', encoding='utf8') as in_file:
que = None
ans = None
for line in in_file.readlines():
if 'Q:\t' in line:
que = line.strip().split('\t')[-1]
elif 'A:\t' in line:
ans = line.strip().split('\t')[-1]
if len(que) > 5 and ans is not None and len(ans) > 2:
dialog_list.append([que, ans])
que = None
ans = None
chatterbot_corpus = {"conversations": dialog_list}
out_file = open('kuakua_corpus.json', 'a', encoding='utf8')
json.dump(chatterbot_corpus, out_file, ensure_ascii=False)
@classmethod
def create_chatterbot(cls):
"""
用语料训练一个chatbot
:return:
"""
cn_chatter = ChatBot("National Lib Chatter",
storage_adapter='chatterbot.storage.SQLStorageAdapter',
input_adapter='chatterbot.input.TerminalAdapter',
output_adapter='chatterbot.output.TerminalAdapter',
logic_adapters=[
'chatterbot.logic.BestMatch',
'chatterbot.logic.MathematicalEvaluation',
],
database='./db.sqlite3'
)
trainer = ChatterBotCorpusTrainer(cn_chatter)
trainer.train('./kuakua_corpus.json')
# trainer.export_for_training('./my_export.json')
return cn_chatter
@classmethod
def load_chatterbot(cls):
"""
加载训练好的bot
:return:
"""
cn_chatterbot = ChatBot('National Lib Chatter',
storage_adapter='chatterbot.storage.SQLStorageAdapter',
input_adapter = 'chatterbot.input.TerminalAdapter',
output_adapter = 'chatterbot.output.TerminalAdapter',
logic_adapters = [
'chatterbot.logic.BestMatch',
'chatterbot.logic.MathematicalEvaluation',
],
database = './db.sqlite3'
)
return cn_chatterbot
if __name__ == '__main__':
# kuakuaChat.corpus_convert()
# test_chatter = kuakuaChat.create_chatterbot()
test_chatter = kuakuaChat.load_chatterbot()
while True:
try:
user_input = input('USER:')
response = test_chatter.get_response(user_input)
print('BOT:', response)
# 直到按ctrl-c 或者 ctrl-d 才会退出
except (KeyboardInterrupt, EOFError, SystemExit):
break

效果很不好,chatterbot本身适用于闲聊,任务性差,对语料的方法性好像也不太敏感 。有篇博客专门比较了一下开源聊天机器人的性能,也表示chatterbot对于闲聊型问题还可以回答正确几个(准确率也不高),但是对于任务型、知识型问题一窍不通,这应该是开源项目里没有设置相应的模块、语料库资源过少,也不能够主动上网查询。