etcd源码阅读笔记(二)backend
1. 简介
etcd的backend模块对于底层存储引擎进行了抽象,默认使用上一篇文章中介绍的BoltDB。
etcd将键值对的每一个版本都存储在BoltDB中,并在内存中构建BTree keyIndex索引。
- 在BoltDB中存储数据的key是revision,revision包含两个id:main revision和sub revision;main revision每个事务加1,sub revision事务中的每次操作加1;
- keyIndex索引的key是键值对的key,value是revision。
通过这种存储模型,etcd很自然的支持了MVCC、历史数据查询和watcher。
2. backend
2.1 Backend和backend
Backend接口和backend结构体定义如下:
type Backend interface {
// 创建一个只读事务
ReadTx() ReadTx
// 创建一个批量事务
BatchTx() BatchTx
// 创建一个无阻塞并发读事务
ConcurrentReadTx() ReadTx
// 创建一个快照
Snapshot() Snapshot
Hash(ignores map[IgnoreKey]struct{}) (uint32, error)
// 返回存储引擎已分配的物理空间大小
Size() int64
// 返回存储引擎已使用的空间大小
SizeInUse() int64
// 返回打开的只读事务数量
OpenReadTxN() int64
// 碎片整理
Defrag() error
// 提交批量读写事务
ForceCommit()
Close() error
}
type backend struct {
// 已分配的字节数
size int64
// 实际使用的字节数
sizeInUse int64
// 提交次数
commits int64
// 已打开的读事务数量
openReadTxN int64
// 锁
mu sync.RWMutex
// BoltDB指针
db *bolt.DB
...
}
2.2 只读事务
只读事务定义了如下接口:
type ReadTx interface {
Lock()
Unlock()
RLock()
RUnlock()
// 在指定bucket中范围搜索
UnsafeRange(bucketName []byte, key, endKey []byte, limit int64) (keys [][]byte, vals [][]byte)
// 在遍历指定bucket,并执行回调方法
UnsafeForEach(bucketName []byte, visitor func(k, v []byte) error) error
}
type readTx struct {
// 读写锁,控制对于 txReadBuffer 读缓存的访问
mu sync.RWMutex
// 读缓存
buf txReadBuffer
// 事务读写锁,范围搜索时,控制对于bucket的访问
txMu sync.RWMutex
// 底层引擎的事务
tx *bolt.Tx
// 底层引擎的bucket的指针的map,key为bucketName
buckets map[string]*bolt.Bucket
...
}
范围搜索的具体实现如下:
func (rt *readTx) UnsafeRange(bucketName, key, endKey []byte, limit int64) ([][]byte, [][]byte) {
// endKey为nil,表示查一个键值对
if endKey == nil {
limit = 1
}
if limit <= 0 {
limit = math.MaxInt64
}
if limit > 1 && !bytes.Equal(bucketName, safeRangeBucket) {
panic("do not use unsafeRange on non-keys bucket")
}
// 在txReadBuffer中范围搜索
keys, vals := rt.buf.Range(bucketName, key, endKey, limit)
if int64(len(keys)) == limit {
return keys, vals
}
// 如果没有在txReadBuffer找到
// 则搜索并缓存bucket
bn := string(bucketName)
// txMu读锁保护下,读取bucket指针
rt.txMu.RLock()
bucket, ok := rt.buckets[bn]
rt.txMu.RUnlock()
if !ok {
// 如果没有取到,则可能其他进程写锁正在修改
// txMu读锁保护下,读取bucket指针
rt.txMu.Lock()
bucket = rt.tx.Bucket(bucketName)
rt.buckets[bn] = bucket
rt.txMu.Unlock()
}
if bucket == nil {
return keys, vals
}
// txMu读锁保护下,获取bucket游标
rt.txMu.Lock()
c := bucket.Cursor()
rt.txMu.Unlock()
// 使用游标范围搜索bucket
k2, v2 := unsafeRange(c, key, endKey, limit-int64(len(keys)))
return append(k2, keys...), append(v2, vals...)
}
2.3 并发读事务
// concurrentReadTx定义
type concurrentReadTx struct {
buf txReadBuffer
txMu *sync.RWMutex
tx *bolt.Tx
buckets map[string]*bolt.Bucket
txWg *sync.WaitGroup
}
func (b *backend) ConcurrentReadTx() ReadTx {
// 申请读锁
b.readTx.RLock()
// defer 释放读锁
defer b.readTx.RUnlock()
// WaitGroup计数器置为1
b.readTx.txWg.Add(1)
// 创建concurrentReadTx
return &concurrentReadTx{
buf: b.readTx.buf.unsafeCopy(),
tx: b.readTx.tx,
txMu: &b.readTx.txMu,
buckets: b.readTx.buckets,
txWg: b.readTx.txWg,
}
}
ConcurrentReadTx的创建过程其实就是从backend的readTx克隆一份新的buf缓冲区,tx、txMu、buckets、txWg均指向readTx。
read_tx.go
func (rt *concurrentReadTx) Lock() {}
func (rt *concurrentReadTx) Unlock() {}
func (rt *concurrentReadTx) RLock() {}
func (rt *concurrentReadTx) RUnlock() { rt.txWg.Done() }
ConcurrentReadTx的申请锁、释放锁实现如上,Lock、Unlock、RLock时,不做任何操作,仅在RUnlock时将WaitGroup计数器减一。
2.4 批量事务
批量事务提供批量读写数据库的能力。
batch_tx.go
type BatchTx interface {
ReadTx
UnsafeCreateBucket(name []byte)
UnsafePut(bucketName []byte, key []byte, value []byte)
UnsafeSeqPut(bucketName []byte, key []byte, value []byte)
UnsafeDelete(bucketName []byte, key []byte)
// 提交事务,并开始一个新事务
Commit()
// 提交事务,但不开始一个新事务
CommitAndStop()
}
type batchTx struct {
// 互斥锁
sync.Mutex
// BoltDB事务实例
tx *bolt.Tx
// 关联的backend实例
backend *backend
// 待提交的指令数量
pending int
}
同样的,BatchTx定义了一系列不安全的读写方法,需要调用方自行控制并发。
util.go
func WriteKV(be backend.Backend, kv mvccpb.KeyValue) {
// 创建BoltDB中的key
ibytes := newRevBytes()
revToBytes(revision{main: kv.ModRevision}, ibytes)
// 键值对组织成byte数组
d, err := kv.Marshal()
if err != nil {
panic(fmt.Errorf("cannot marshal event: %v", err))
}
// 加锁
be.BatchTx().Lock()
// 写BoltDB,key为revision,value为键值对
be.BatchTx().UnsafePut(keyBucketName, ibytes, d)
// 释放锁
be.BatchTx().Unlock()
}
3. KeyIndex内存索引
index.go
type treeIndex struct {
sync.RWMutex
tree *btree.BTree
lg *zap.Logger
}
treeIndex主要由一个读写锁、一个BTree和一个日志工具组成,BTree使用的是google开源项目。
key_index.go
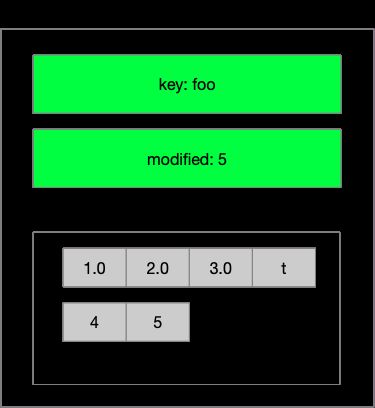
type keyIndex struct {
// 调用方传入的键值对的key
key []byte
// 最后一次修改的main revison
modified revision
// 该key对应的每代的版本信息
generations []generation
}
keyIndex是BTree上的一个键值对的值的数据结构。其中generations []generation中存储着每次编辑的对应的main revision 和 sub revision。
type generation struct {
ver int64
created revision
// 记录了多次修改的revision
revs []revision
}
每个generation实例记录了多次修改的revision,知道调用tombstone,终止一个generation
func (ki *keyIndex) tombstone(lg *zap.Logger, main int64, sub int64) error {
if ki.isEmpty() {
lg.Panic(
"'tombstone' got an unexpected empty keyIndex",
zap.String("key", string(ki.key)),
)
}
// 判断最后一个generation是否合法
if ki.generations[len(ki.generations)-1].isEmpty() {
return ErrRevisionNotFound
}
ki.put(lg, main, sub)
// generations最后追加一个tombstone,其实就是个空的generation实例
ki.generations = append(ki.generations, generation{})
keysGauge.Dec()
return nil
}
4. 总结
综上所述,etcd的backend模块,基于BoltDB和内存BTree索引,在读多写少的场景下表现优异。
5. 引用
etcd源代码
BTree