Python面试系列之--垃圾回收机制(GC)
在使用python中很少遇到内存溢出的问题,也不关心内存的管理问题,这是高级语言自带的处理机制,将内部的垃圾空间清除。
要清楚是怎么回收垃圾的,那我们应该先明白什么情况下产生垃圾,就涉及到python内部的对象管理方法。
对于int类型的变量在[5, 257)范围内是共用对象常驻内存,不在此范围内的话一个变量建立一个对象。
单个字符是常驻内存共用对象,字符串是引用计数机制(相同的值指向同一个对象)
a = 256
a1 = 256
b = 257
b1 = 257
id(a) == id(a1)
Out[6]: True
id(b) == id(b1)
Out[7]: False
c1 = 'a'
c = 'a'
d = 'sdsds4'
d1 = 'sdsds4'
id(c) == id(c1)
Out[12]: True
id(d) == id(d1)
Out[13]: True
首先在对象管理上已经做到了最小化的内存开销,并不是一个变量一个对象,而是多种方案结合。
那再看垃圾回收的机制,与C/C++有别的是python内部实现了自动的垃圾回收,而无需用户考虑什么时候销毁一个对象或变量。python的垃圾回收机制是以引用计数机制为主,标记-清除和分代收集两种机制为辅的综合方案。
引用计数机制
上面说的字符串内存管理就是引用计数,当创建一个字符串a=‘test’,之后再创建一个b = ‘test‘,其实变量a/b指向的是一个对象’test’,这个对象被引用的次数是2,但是当我们改变b='test1‘,这个时候b新建了一个对象’test1’并且引用计数为1,相应的a引用计数也变为了1,这就是引用计数。
那么怎么通过引用计数回收垃圾对象呢?还是上面那个案例,此时再把变量a赋值a=‘test2’,那么又新建了一个对象’test2’并且引用计数为1,此时之前的’test’引用计数变为0,就意味没有任何变量使用了该对象,那这个对象就是垃圾对象被销毁。
引用计数简单方便但是也有弊端:计数占用内存、在相互引用的对象中计数永远不会变为0,所以还引入了标记-清除和分代收集。
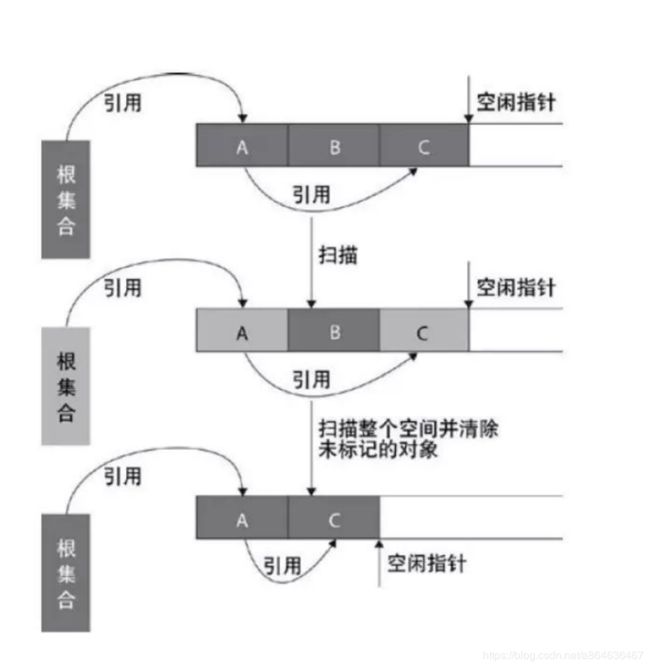
标记-清除
标记清除的概念类似于引用计数,只是不同的是当引用计数为0的时候就给这个对象打上一个标签”可清除“,但是不会立马清除,而是会等到系统给程序分配的内存要用完之时,停下来将可清除标签的对象销毁然后继续。
分代回收
首先看上面说的引用计数的弊端在两个变量循环引用中,计数永远不可能是0.
b = [3,4]
a = [1,2]
a.append(b)
b.append(a)
a
Out[25]: [1, 2, [3, 4, [...]]]
b
Out[26]: [3, 4, [1, 2, [...]]]
del a
b
Out[29]: [3, 4, [1, 2, [...]]]
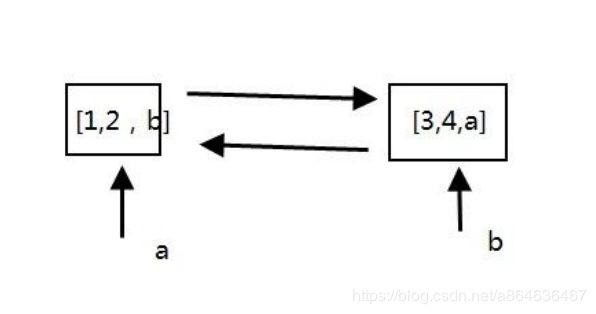
当删除a/b变量时对应的内存对象应用计数还是1是无法删除的,此时分代回收就发挥了他的作用,当创建一个对象是将它向上面对象一个放在一个抽象的链条上,这条链条就是零代链条。
然后当零代链条上对象数达到阀值就对上面相互引用的对象进行检测,将相互引用的对象的计数减1,再标记清除垃圾,此时剩下的对象移到一代链条,当一代链条到达阀值就重复零代的检测方式,将剩下对象移到二代,就以此类推进行下去。