正则表达式:
正则表达式测试工具,创建 一个正则表达式后,需要测试该正则表达式是否正确,使用正则表达式测试工具"Notepad++"来测试正则表达式。
操作步骤:打开"Notepad++"软件,点击"搜索"菜单下的查找,在弹出的对话框的左下角"查找模式"选项里点选"正则表达式",
在正上方的输入文本框里输入正则表达式即可搜索匹配的字符串了。
正则表达式 - 符号
+ :号代表前面的字符必须至少出现一次(1次或多次)
* :号代表字符可以不出现,也可以出现一次或者多次(0次、或1次、或多次)
?: 问号代表前面的字符最多只可以出现一次(0次、或1次)
[] :用方括号表示字符集合,反字符集可在字符前加^。例如[a-f]匹配a,b,c,d...f任意某一个字符,[^a-f]则匹配除a,b,c,d...f外的任意字符。字符集也只能匹配一个字符。
():用圆括号表示分组,多个圆括号表示一个分组或多个分组。
{}:用花括号表示限定符,例如{4}表示重复4次,{4,}表示至少重复4次,{4,10}表示重复至少4次,最多10次
{n,m}?或*?或+?: 对前面的分组进行非贪心匹配。
r: 表示后面的字符串为原始字符串
^:脱字符spam 表示字符串必须以 spam 开始。
$:spam$ 表示字符串必须以 spam 结束。
.:匹配所有字符,换行符除外。
\:反斜杠,可以匹配特殊字符本身
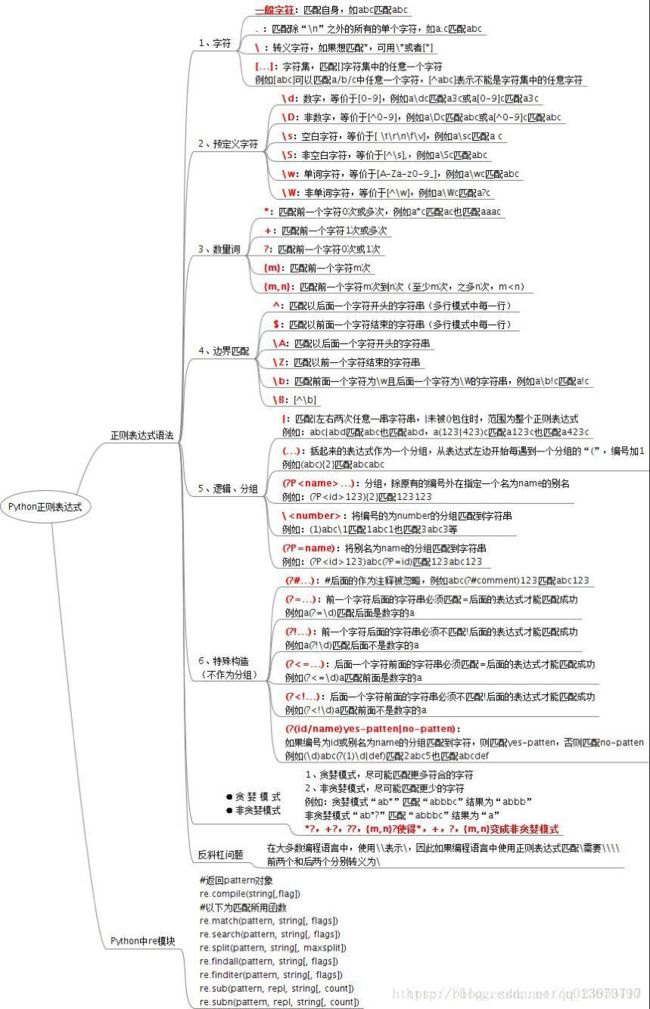
\d:匹配任意数字,等价于 [0-9]。
\w:匹配数字字母下划线,等价于 [0-9]
\s:匹配任意空白字符,等价于 [\t\n\r\f]。
\D:匹配任意非数字
\W:匹配非数字字母下划线
\S:匹配任意非空字符
[abc] 匹配方括号内的任意字符(诸如 a、b 或 c)。
[^abc] 匹配不在方括号内的任意字符。
re.match 从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
re.match(pattern, string, flags=0),参数pattern:匹配的正则表达式,string:要匹配的字符串。flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。可选标志
re.search 扫描整个字符串并返回第一个成功的匹配。
match和search都可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
re.sub(pattern, repl, string, count=0, flags=0),
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
- flags : 编译时用的匹配模式,数字形式。
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用
re.compile(pattern[, flags]),pattern : 一个字符串形式的正则表达式,flags 可选,表示匹配模式,比如忽略大小写,多行模式等。
findall在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。注意: match 和 search 是匹配一次 findall 匹配所有。
findall(string[, pos[, endpos]]),string 待匹配的字符串。pos 可选参数,指定字符串的起始位置,默认为 0。endpos 可选参数,指定字符串的结束位置,默认为字符串的长度
非负整数:^\d+$
正整数:^[0-9]*[1-9][0-9]*$
非正整数:^((-\d+)|(0+))$
负整数:^-[0-9]*[1-9][0-9]*$
整数:^-?\d+$
非负浮点数:^\d+(\.\d+)?$
正浮点数 : ^((0-9)+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)$
非正浮点数:^((-\d+\.\d+)?)|(0+(\.0+)?))$
负浮点数:^(-((正浮点数正则式)))$
英文字符串:^[A-Za-z]+$
英文大写串:^[A-Z]+$
英文小写串:^[a-z]+$
英文字符数字串:^[A-Za-z0-9]+$
英数字加下划线串:^\w+$
E-mail地址:^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$
URL:^[a-zA-Z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\s*)?$
或:^http:\/\/[A-Za-z0-9]+\.[A-Za-z0-9]+[\/=\?%\-&_~`@[\]\':+!]*([^<>\"\"])*$
邮政编码:^[1-9]\d{5}$
中文:^[\u0391-\uFFE5]+$
电话号码:^((\(\d{2,3}\))|(\d{3}\-))?(\(0\d{2,3}\)|0\d{2,3}-)?[1-9]\d{6,7}(\-\d{1,4})?$
手机号码:^((\(\d{2,3}\))|(\d{3}\-))?13\d{9}$
双字节字符(包括汉字在内):^\x00-\xff
匹配首尾空格:(^\s*)|(\s*$)(像vbscript那样的trim函数)
匹配HTML标记:<(.*)>.*<\/\1>|<(.*) \/>
匹配空行:\n[\s| ]*\r
提取信息中的网络链接:(h|H)(r|R)(e|E)(f|F) *= *('|")?(\w|\\|\/|\.)+('|"| *|>)?
提取信息中的邮件地址:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
提取信息中的图片链接:(s|S)(r|R)(c|C) *= *('|")?(\w|\\|\/|\.)+('|"| *|>)?
提取信息中的IP地址:(\d+)\.(\d+)\.(\d+)\.(\d+)
提取信息中的中国手机号码:(86)*0*13\d{9}
提取信息中的中国固定电话号码:(\(\d{3,4}\)|\d{3,4}-|\s)?\d{8}
提取信息中的中国电话号码(包括移动和固定电话):(\(\d{3,4}\)|\d{3,4}-|\s)?\d{7,14}
提取信息中的中国邮政编码:[1-9]{1}(\d+){5}
提取信息中的浮点数(即小数):(-?\d*)\.?\d+
提取信息中的任何数字 :(-?\d*)(\.\d+)?
IP:(\d+)\.(\d+)\.(\d+)\.(\d+)
电话区号:/^0\d{2,3}$/
腾讯QQ号:^[1-9]*[1-9][0-9]*$
帐号(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
中文、英文、数字及下划线:^[\u4e00-\u9fa5_a-zA-Z0-9]+$
匹配中文字符的正则表达式: [\u4e00-\u9fa5]
匹配双字节字符(包括汉字在内):[^\x00-\xff]
匹配空行的正则表达式:\n[\s| ]*\r
匹配HTML标记的正则表达式:/<(.*)>.*<\/\1>|<(.*) \/>/
sql语句:^(select|drop|delete|create|update|insert).*$
匹配首尾空格的正则表达式:(^\s*)|(\s*$)
匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*