数据分析入门之pandas数据预处理
文章目录
- 1、合并数据
- 1.1、横向表堆叠
- 1.2、纵向堆叠
- 1.2.1、concat函数
- 1.2.2、append方法
- 1.3、主键合并数据
- 1.3.1、merge函数
- 1.3.2、join方法
- 1.4、重叠合并数据
- 2、清洗数据
- 2.1、检测与处理重复值
- 2.1.1、记录重复
- 2.1.1.1、利用列表(list)去重
- 2.1.1.2、利用集合(set)的元素是唯一的特性去重
- 2.1.1.3、drop_duplicates去重方法
- 2.1.2、特征重复
- 2.1.2.1、corr函数
- 2.1.2.2、DataFrame.equals()函数
- 2.1、检测与处理缺失值
- 2.1.1、缺失值检测——利用isnull或notnull找到缺失值
- 2.1.2、处理缺失值
- 2.1.2.1、删除法
- 2.1.2.2、替换法
- 2.2、检测与处理异常值
- 2.2.1、异常值
- 2.2.2、3σ原则
- 2.2.3、箱线图分析
- 3、标准化数据
- 3.1、离差标准化数据
- 3.1.1、离差标准化公式
- 3.1.2、离差标准化的特点
- 3.2、标准差标准化数据
- 3.3、小数定标标准化数据
- 4、转换数据
- 4.1、哑变量处理类别数据
- 4.1.1、哑变量处理
- 4.1.2、get_dummies函数
- 4.1.3、哑变量处理的特点
- 4.2、离散化连续型数据
- 4.2.1、离散化
- 4.2.2、等宽法
- 4.2.3、等频法
- 4.2.4、基于聚类分析的方法
1、合并数据
导入数据:
import pandas as pd
from sqlalchemy import create_engine
engin = create_engine('mysql+pymysql://root:123456@localhost:3306/test?charset=utf8')
data = pd.read_sql('meal_order_detail1', con=engin)

1.1、横向表堆叠
- 横向堆叠,即将两个表在X轴向拼接在一起,可以使用concat函数完成,concat函数的基本语法如下:
- pandas.concat(objs, axis=0, join=‘outer’, join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, copy=True)
- 常用参数如下所示:
| 参数名称 | 说明 |
|---|---|
| objs | 接收多个Series,DataFrame,Panel的组合。表示参与链接的pandas对象的列表的组合。无默认 |
| axis | 接收0或1。表示连接的轴向,默认为0 |
| join | 接收inner或outer。表示其他轴向上的索引是按交集(inner)还是并集(outer)进行合并。默认为outer |
| join_axes | 接收Index对象。表示用于其他n-1条轴的索引,不执行并集/交集运算 |
| ignore_index | 接收boolean。表示是否不保留连接轴上的索引,产生一组新索引range(total_length)。默认为False |
| keys | 接收sequence。表示与连接对象有关的值,用于形成连接轴向上的层次化索引。默认为None |
| levels | 接收包含多个sequence的list。表示在指定keys参数后,指定用作层次化索引各级别上的索引。默认为None |
| names | 接收list。表示在设置了keys和levels参数后,用于创建分层级别的名称。默认为None |
| verify_integrity | 接收boolearn。表示是否检查结果对象新轴上的重复情况,如果发现则引发异常。默认为False |
- 当axis=1的时候,concat做行对齐,然后将不同列名称的两张或多张表合并。当两个表索引不完全一样时,可以使用join参数选择是内连接还是外连接。在内连接的情况下,仅仅返回索引重叠部分。在外连接的情况下,则显示索引的并集部分数据,不足的地方则使用空值填补。
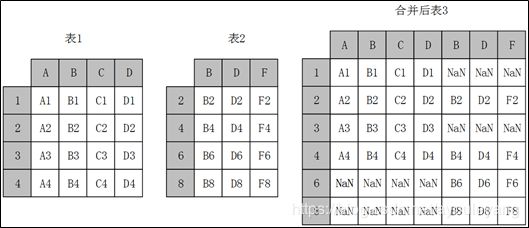
- 当两张表完全一样时,不论join参数取值是inner或者outer,结果都是将两个表完全按照X轴拼接起来。
a = data.iloc[:,:10]#所有行的前10列数据,按位置索引
b = data.iloc[:,10:]#所有行的10列后数据
pdcc = pd.concat([a,b], axis=1)#合并完成,axis=1表示横向,左右拼接
pdcc.shape
理解: data.iloc[:,:5] [纵 : 横],纵向全选,横向选5个截至。

1.2、纵向堆叠
1.2.1、concat函数
- 使用concat函数时,在默认情况下,即axis=0时,concat做列对齐,将不同行索引的两张或多张表纵向合并。在两张表的列名并不完全相同的情况下,可join参数取值为inner时,返回的仅仅是列名交集所代表的列,取值为outer时,返回的是两者列名的并集所代表的列,其原理示意如图:

- 不论join参数取值是inner或者outer,结果都是将两个表完全按照Y轴拼接起来。
a = data.iloc[:100,:]
b = data.iloc[100:,:]
pd.concat([a,b]).shape#axis=0,默认可以不写
(2779, 19)
1.2.2、append方法
- append方法也可以用于纵向合并两张表。但是append方法实现纵向表堆叠有一个前提条件,那就是两张表的列名需要完全一致。
- pandas.DataFrame.append(self, other, ignore_index=False, verify_integrity=False)
- 常用参数如下所示:
| 参数名称 | 说明 |
|---|---|
| other | 接收DataFrame或Series。表示要添加的新数据。无默认 |
| ignore_index | 接收boolean。如果输入True,会对新生成的DataFrame使用新的索引(自动产生)而忽略原来数据的索引。默认为False |
| verify_integrity | 接收boolean。如果输入True,那么当ignore_index为False时,会检查添加的数据索引是否冲突,如果冲突,则会添加失败。默认为False |
a.append(b).shape
(2779, 19)
1.3、主键合并数据
(1) 导入数据
order = pd.read_csv('./meal_order_info.csv',encoding='gbk')
order.head()

(2) 查看数据类型

(3) 转换数据类型
order['info_id'] = order['info_id'].astype(str)
1.3.1、merge函数
pd.merge(order, data, left_on='info_id', right_on='order_id')
1.3.2、join方法
- join方法也可以实现部分主键合并的功能,但是join方法使用时,两个主键的名字必须相同。
- pandas.DataFrame.join(self, other, on=None, how=‘left’, lsuffix=’’, rsuffix=’’, sort=False)
- 常用参数说明如下:
| 参数名称 | 说明 |
|---|---|
| other | 接收DataFrame、Series或者包含了多个DataFrame的list。表示参与连接的其他DataFrame。无默认 |
| on | 接收列名或者包含列名的list或tuple。表示用于连接的列名。默认为None |
| how | 接收特定string。inner代表内连接;outer代表外连接;left和right分别代表左连接和右连接。默认为inner |
| rsuffix | 接收string。表示用于追加到右侧重叠列名的末尾。无默认 |
| lsuffix | 接收sring。表示用于追加到左侧重叠列名的末尾。无默认 |
| sort | 根据连接键对合并后的数据进行排序,默认为True |
(1)更改order的主键名称
order.rename(columns={'info_id':'order_id'},inplace=True)

(2)按主键合并数据
data.join(order, on='order_id', rsuffix='1')
1.4、重叠合并数据
- 数据分析和处理过程中若出现两份数据的内容几乎一致的情况,但是某些特征在其中一张表上是完整的,而在另外一张表上的数据则是缺失的时候,可以用combine_first方法进行重叠数据合并,其原理如下:
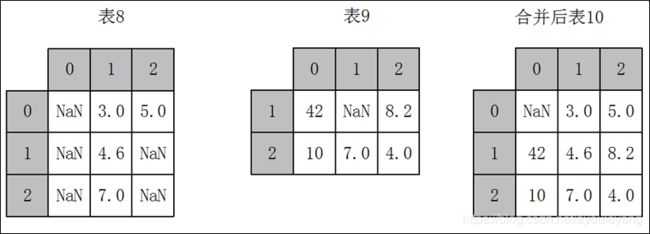
combine_first方法 - combine_first的具体用法如下:
- pandas.DataFrame.combine_first(other)
- 参数及其说明如下:
| 参数名称 | 说明 |
|---|---|
| other | 接收DataFrame。表示参与重叠合并的另一个DataFrame。无默认 |
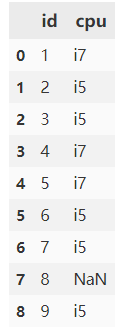
(1) 构造两个数组
import numpy as np
dis1 = {
'id':list(range(1,10)),
'cpu':['i7', 'i5', np.nan, 'i7', 'i7', 'i5', np.nan, np.nan,'i5']
}
a = pd.DataFrame(dis1)
dis2 = {
'id':list(range(1,10)),
'cpu':['i7', 'i5', 'i5', np.nan, 'i7', 'i5', 'i5', np.nan,'i5']
}
b = pd.DataFrame(dis2)

(2) 缺失值合并
a.combine_first(b)
2、清洗数据
2.1、检测与处理重复值
2.1.1、记录重复
- 记录重复,即一个或者多个特征某几个记录的值完全相同
2.1.1.1、利用列表(list)去重
def delRep(list1):
list2=[]
for i in list1:
if i not in list2:
list2.append(i)
return list2
2.1.1.2、利用集合(set)的元素是唯一的特性去重
dish_set = set(dishes)
比较上述两种方法可以发现,方法一代码冗长。方法二代码简单了许多,但会导致数据的排列发生改变。
2.1.1.3、drop_duplicates去重方法
- pandas提供了一个名为drop_duplicates的去重方法。该方法只对DataFrame或者Series类型有效。这种方法不会改变数据原始排列,并且兼具代码简洁和运行稳定的特点。该方法不仅支持单一特征的数据去重,还能够依据DataFrame的其中一个或者几个特征进行去重操作。
- pandas.DataFrame(Series).drop_duplicates(self, subset=None, keep=‘first’, inplace=False)
| 参数名称 | 说明 |
|---|---|
| subset | 接收string或sequence。表示进行去重的列。默认为None,表示全部列 |
| keep | 接收特定string。表示重复时保留第几个数据。First:保留第一个。Last:保留最后一个。False:只要有重复都不保留。默认为first |
| inplace | 接收boolean。表示是否在原表上进行操作。默认为False |
(1) 查看数据
data['dishes_name']
0 蒜蓉生蚝
1 蒙古烤羊腿
2 大蒜苋菜
3 芝麻烤紫菜
4 蒜香包
...
2774 白饭/大碗
2775 牛尾汤
2776 意文柠檬汁
2777 金玉良缘
2778 酸辣藕丁
Name: dishes_name, Length: 2779, dtype: object
(2) 数据单列去重
data['dishes_name'].drop_duplicates()
0 蒜蓉生蚝
1 蒙古烤羊腿
2 大蒜苋菜
3 芝麻烤紫菜
4 蒜香包
...
1024 海带结豆腐汤
1169 冰镇花螺
1411 冬瓜炒苦瓜
1659 超人气广式肠粉
2438 百里香奶油烤紅酒牛肉
Name: dishes_name, Length: 145, dtype: object
(3) 数据整体去重
data.drop_duplicates().shape
(2779, 19)
(4) 数据并列去重
data.drop_duplicates(subset=['order_id','emp_id']).shape
(278, 19)
2.1.2、特征重复
2.1.2.1、corr函数
- 结合相关的数学和统计学知识,去除连续型特征重复可以利用特征间的相似度将两个相似度为1的特征去除一个。在pandas中相似度的计算方法为corr,使用该方法计算相似度时,默认为“pearson”法 ,可以通过“method”参数调节,目前还支持“spearman”法和“kendall”法。
data[['counts','amounts']].corr()

- 但是通过相似度矩阵去重存在一个弊端,该方法只能对数值型重复特征去重,类别型特征之间无法通过计算相似系数来衡量相似度。
2.1.2.2、DataFrame.equals()函数
sim_dis = pd.DataFrame([],
index=['counts','amounts','dishes_name'],
columns=['counts','amounts','dishes_name'])
for i in ['counts','amounts','dishes_name']:
for j in ['counts','amounts','dishes_name']:
sim_dis.loc[i,j] = data[i].equals(data[j])
print (sim_dis)
counts amounts dishes_name
counts True False False
amounts False True False
dishes_name False False True
2.1、检测与处理缺失值
2.1.1、缺失值检测——利用isnull或notnull找到缺失值
- 数据中的某个或某些特征的值是不完整的,这些值称为缺失值。
- pandas提供了识别缺失值的方法isnull以及识别非缺失值的方法notnull,这两种方法在使用时返回的都是布尔值True和False。
- 结合sum函数和isnull、notnull函数,可以检测数据中缺失值的分布以及数据中一共含有多少缺失值。
- isnull和notnull之间结果正好相反,因此使用其中任意一个都可以判断出数据中缺失值的位置。
data.isnull()

- 它们返回的数值都是一样的,所以它们的数据都不存在空值,平时只需要使用一个就可以判断了。

2.1.2、处理缺失值
dis1 = {
'id':list(range(1,10)),
'cpu':['i7', 'i5', np.nan, 'i7', 'i7', 'i5', np.nan, np.nan,'i5']
}
a = pd.DataFrame(dis1)

2.1.2.1、删除法
-
删除法分为删除观测记录和删除特征两种,它属于利用减少样本量来换取信息完整度的一种方法,是一种最简单的缺失值处理方法。
-
pandas中提供了简便的删除缺失值的方法dropna,该方法既可以删除观测记录,亦可以删除特征。
-
pandas.DataFrame.dropna(self, axis=0, how=‘any’, thresh=None, subset=None, inplace=False)
-
常用参数及其说明如下:
| 参数名称 | 说明 |
|---|---|
| axis | 接收0或1。表示轴向,0为删除观测记录(行),1为删除特征(列)。默认为0 |
| how | 接收特定string。表示删除的形式。any表示只要有缺失值存在就执行删除操作。all表示当且仅当全部为缺失值时执行删除操作。默认为any |
| subset | 接收类array数据。表示进行去重的列∕行。默认为None,表示所有列/行 |
| inplace | 接收boolean。表示是否在原表上进行操作。默认为False |
#默认横向删除
a.dropna()
#删除指定列缺失数据
a.dropna(subset=['id'])
#删除缺失的列
a.dropna(axis=1)

注意: 这样删除缺失值并不会对原数据造成影响,需要变化的话可以加上inplace=True。
2.1.2.2、替换法
- 替换法是指用一个特定的值替换缺失值。
- 特征可分为数值型和类别型,两者出现缺失值时的处理方法也是不同的。
- 缺失值所在特征为数值型时,通常利用其均值、中位数和众数等描述其集中趋势的统计量来代替缺失值。
- 缺失值所在特征为类别型时,则选择使用众数来替换缺失值。
- pandas库中提供了缺失值替换的方法名为fillna,其基本语法如下:
- pandas.DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None)
| 参数名称 | 说明 |
|---|---|
| value | 接收scalar,dict,Series或者DataFrame。表示用来替换缺失值的值。无默认 |
| method | 接收特定string。backfill或bfill表示使用下一个非缺失值填补缺失值。pad或ffill表示使用上一个非缺失值填补缺失值。默认为None |
| axis | 接收0或1。表示轴向。默认为1 |
| inplace | 接收boolean。表示是否在原表上进行操作。默认为False |
| limit | 接收int。表示填补缺失值个数上限,超过则不进行填补。默认为None |
(1) 指定替换为某值
a['cpu'].fillna('i7')

(2) 查看众数

(3) 利用众数填充
a['cpu'].fillna(a['cpu'].value_counts().index[0])
0 i7
1 i5
2 i7
3 i7
4 i7
5 i5
6 i7
7 i7
8 i5
Name: cpu, dtype: obje
(4) 利用均值替换
- 够着一个数值型数组
import numpy as np
dis1 = {
'id':list(range(1,10)),
'num':[7, 7, np.nan, 5, 4, 6, np.nan, np.nan,7]
}
a = pd.DataFrame(dis1)
a

a['num'].fillna(a['num'].mean())
0 7.0
1 7.0
2 6.0
3 5.0
4 4.0
5 6.0
6 6.0
7 6.0
8 7.0
Name: num, dtype: float64
(5) 插值法
-
删除法简单易行,但是会引起数据结构变动,样本减少;替换法使用难度较低,但是会影响数据的标准差,导致信息量变动。在面对数据缺失问题时,除了这两种方法之外,还有一种常用的方法—插值法.
-
常用的插值法有线性插值、多项式插值和样条插值等:
- 线性插值是一种较为简单的插值方法,它针对已知的值求出线性方程,通过求解线性方程得到缺失值。
- 多项式插值是利用已知的值拟合一个多项式,使得现有的数据满足这个多项式,再利用这个多项式求解缺失值,常见的多项式插值法有拉格朗日插值和牛顿插值等。
- 样条插值是以可变样条来作出一条经过一系列点的光滑曲线的插值方法,插值样条由一些多项式组成,每一个多项式都是由相邻两个数据点决定,这样可以保证两个相邻多项式及其导数在连接处连续。
-
从拟合结果可以看出多项式插值和样条插值在两种情况下拟合都非常出色,线性插值法只在自变量和因变量为线性关系的情况下拟合才较为出色。
-
而在实际分析过程中,自变量与因变量的关系是线性的情况非常少见,所以在大多数情况下,多项式插值和样条插值是较为合适的选择。
-
SciPy库中的interpolate模块除了提供常规的插值法外,还提供了例如在图形学领域具有重要作用的重心坐标插值(BarycentricInterpolator)等。在实际应用中,需要根据不同的场景,选择合适的插值方法。
线性插值法:
x = np.array([1,2,3,6,7])
y = np.array([3,5,6,9,13])
from scipy.interpolate import interp1d
model = interp1d(x,y,kind='linear')
model([4,5])
结果:
array([7., 8.])
- 数据可视化表示
import matplotlib.pyplot as plt
plt.scatter(x,y)#蓝色的点
plt.plot(x, model(x),'r-')#插值后红色的线
plt.show()
拉格朗日插值法:
from scipy.interpolate import lagrange
f_lag = lagrange(x,y)
f_lag([4,5])
结果:
array([6.5, 7.2])
数据可视化:
import matplotlib.pyplot as plt
plt.scatter(x,y)#蓝色的点表示原数据
plt.plot(x, y,'c-')#浅绿色的线表示原数据
plt.scatter([4,5],model([4,5]),c='r')#红点表示线性插值点
plt.scatter([4,5],f_lag([4,5]),c='b')#红点表示拉格朗日插值点
#支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.legend(['原点','原线','线性插值','拉格朗日插值'])
plt.show()

样条插值法:
from scipy.interpolate import BSpline
y_bs = BSpline(x, y, k=1)
y_bs([4,5])
array([5.33333333, 5.66666667])
2.2、检测与处理异常值
2.2.1、异常值
- 异常值是指数据中个别值的数值明显偏离其余的数值,有时也称为离群点,检测异常值就是检验数据中是否有录入错误以及是否含有不合理的数据。
- 异常值的存在对数据分析十分危险,如果计算分析过程的数据有异常值,那么会对结果会产生不良影响,从而导致分析结果产生偏差乃至错误。
- 常用的异常值检测主要为3σ原则和箱线图分析两种方法。
2.2.2、3σ原则
- 3σ原则又称为拉依达法则。该法则就是先假设一组检测数据只含有随机误差,对原始数据进行计算处理得到标准差,然后按一定的概率确定一个区间,认为误差超过这个区间的就属于异常值。
- 这种判别处理方法仅适用于对正态或近似正态分布的样本数据进行处理,如下表所示,其中σ代表标准差,μ代表均值,x=μ为图形的对称轴。
- 数据的数值分布几乎全部集中在区间(μ-3σ,μ+3σ)内,超出这个范围的数据仅占不到0.3%。故根据小概率原理,可以认为超出3σ的部分数据为异常数据。

u = data['counts'].mean()
o = data['counts'].std()
index = data['counts'].apply(lambda x: x > u+3*o or x < u-3*o)#遍历查询(u-3*o,u+3*o)之外的数据,返回True和False
data.loc[index,'counts']#索引出异常值
94 5.0
176 3.0
238 4.0
270 4.0
346 4.0
...
2370 3.0
2458 3.0
2459 4.0
2461 6.0
2501 7.0
Name: counts, Length: 62, dtype: float64
2.2.3、箱线图分析
- 箱型图提供了识别异常值的一个标准,即异常值通常被定义为小于QL-1.5IQR或大于QU+1.5IQR的值。
- QL称为下四分位数,表示全部观察值中有四分之一的数据取值比它小。
- QU称为上四分位数,表示全部观察值中有四分之一的数据取值比它大。
- IQR称为四分位数间距,是上四分位数QU与下四分位数QL之差,其间包含了全部观察值的一半。
- 箱线图依据实际数据绘制,真实、直观地表现出了数据分布的本来面貌,且没有对数据做任何限制性要求,其判断异常值的标准以四分位数和四分位数间距为基础。
- 四分位数给出了数据分布的中心、散布和形状的某种指示,具有一定的鲁棒性,即25%的数据可以变得任意远而不会很大地扰动四分位数,所以异常值通常不能对这个标准施加影响。鉴于此,箱线图识别异常值的结果比较客观,因此在识别异常值方面具有一定的优越性。
(1)箱线图分析
import matplotlib.pyplot as plt
plt.boxplot(data['counts'])
plt.show()

- 上图表明:data[‘counts’]的数据大多数都在1上,上面出现的黑圈为异常值,实际为用户点餐超过1份的客户。
(2)取出异常值
p = plt.boxplot(data['counts'])
p['fliers'][0].get_ydata()
array([ 2., 2., 2., 2., 5., 2., 2., 2., 2., 2., 3., 2., 2.,
2., 2., 4., 2., 4., 4., 4., 2., 4., 10., 4., 6., 2.,
6., 6., 8., 2., 2., 2., 6., 6., 4., 3., 4., 6., 2.,
6., 6., 2., 8., 3., 2., 2., 2., 4., 2., 2., 2., 2.,
3., 6., 8., 2., 2., 2., 2., 5., 2., 2., 5., 3., 4.,
2., 3., 2., 2., 4., 8., 2., 2., 3., 3., 2., 2., 2.,
4., 4., 2., 2., 2., 4., 6., 2., 3., 3., 3., 2., 2.,
2., 2., 2., 2., 3., 2., 3., 3., 2., 3., 2., 4., 6.,
2., 2., 2., 2., 2., 2., 2., 2., 2., 2., 4., 7., 2.,
2., 4., 8., 8., 4., 3., 3., 3., 2., 2., 2., 2., 2.,
2., 3., 4., 6., 7., 2., 2., 2., 2., 2., 2.])
3、标准化数据
3.1、离差标准化数据
导入数据:
import pandas as pd
data = pd.read_csv('./detail.csv', encoding='gbk')
data.head()

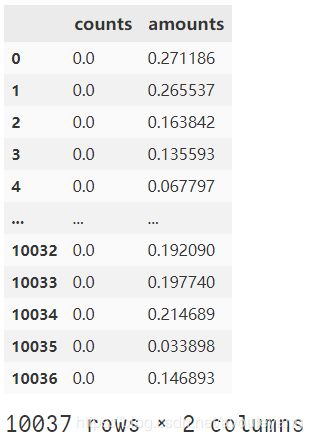
3.1.1、离差标准化公式

def MinMaxScale(data):
return (data - data.min()) / (data.max()-data.min())
a = MinMaxScale(data['counts'])
b = MinMaxScale(data['amounts'])
pd.concat([a,b],axis=1)
3.1.2、离差标准化的特点
- 数据的整体分布情况并不会随离差标准化而发生改变,原先取值较大的数据,在做完离差标准化后的值依旧较大。
- 当数据和最小值相等的时候,通过离差标准化可以发现数据变为0。
- 若数据极差过大就会出现数据在离差标准化后数据之间的差值非常小的情况。
- 同时,还可以看出离差标准化的缺点:若数据集中某个数值很大,则离差标准化的值就会接近于0,并且相互之间差别不大。若将来遇到超过目前属性[min,max]取值范围的时候,会引起系统出错,这时便需要重新确定min和max。
3.2、标准差标准化数据
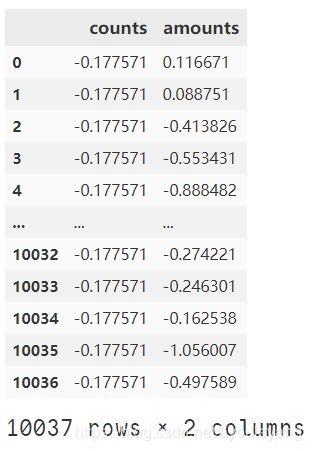
标准差标准化的公式及特点

def StandScale(data):
return (data - data.mean()) / data.std()
a = StandScale(data['counts'])
b = StandScale(data['amounts'])
pd.concat([a,b],axis=1)
3.3、小数定标标准化数据
小数定标标准化公式及对比:

import numpy as np
def DecimalScale(data):
return data / 10**(np.ceil(data.abs().max()))
a = DecimalScale(data['counts'])
b = DecimalScale(data['amounts'])
pd.concat([a,b],axis=1)

4、转换数据
4.1、哑变量处理类别数据
4.1.1、哑变量处理
- 数据分析模型中有相当一部分的算法模型都要求输入的特征为数值型,但实际数据中特征的类型不一定只有数值型,还会存在相当一部分的类别型,这部分的特征需要经过哑变量处理才可以放入模型之中。
- 哑变量处理的原理示例如图:

4.1.2、get_dummies函数
- Python中可以利用pandas库中的get_dummies函数对类别型特征进行哑变量处理。、
- pandas.get_dummies(data, prefix=None, prefix_sep=’_’, dummy_na=False, columns=None, sparse=False, drop_first=False)
| 参数名称 | 说明 |
|---|---|
| data | 接收array、DataFrame或者Series。表示需要哑变量处理的数据。无默认 |
| prefix | 接收string、string的列表或者string的dict。表示哑变量化后列名的前缀。默认为None |
| prefix_sep | 接收string。表示前缀的连接符。默认为‘_’ |
| dummy_na | 接收boolean。表示是否为Nan值添加一列。默认为False |
| columns | 接收类似list的数据。表示DataFrame中需要编码的列名。默认为None,表示对所有object和category类型进行编码 |
| sparse | 接收boolean。表示虚拟列是否是稀疏的。默认为False |
| drop_first | 接收boolean。表示是否通过从k个分类级别中删除第一级来获得k-1个分类级别。默认为False |
pd.get_dummies(data['dishes_name'])

4.1.3、哑变量处理的特点
- 对于一个类别型特征,若其取值有m个,则经过哑变量处理后就变成了m个二元特征,并且这些特征互斥,每次只有一个激活,这使得数据变得稀疏。
- 对类别型特征进行哑变量处理主要解决了部分算法模型无法处理类别型数据的问题,这在一定程度上起到了扩充特征的作用。由于数据变成了稀疏矩阵的形式,因此也加速了算法模型的运算速度。
4.2、离散化连续型数据
4.2.1、离散化
- 某些模型算法,特别是某些分类算法如ID3决策树算法和Apriori算法等,要求数据是离散的,此时就需要将连续型特征(数值型)变换成离散型特征(类别型)。
- 连续特征的离散化就是在数据的取值范围内设定若干个离散的划分点,将取值范围划分为一些离散化的区间,最后用不同的符号或整数值代表落在每个子区间中的数据值。
- 因此离散化涉及两个子任务,即确定分类数以及如何将连续型数据映射到这些类别型数据上。其原理如图:

4.2.2、等宽法
- 将数据的值域分成具有相同宽度的区间,区间的个数由数据本身的特点决定或者用户指定,与制作频率分布表类似。pandas提供了cut函数,可以进行连续型数据的等宽离散化,其基础语法格式如下:
- pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False)
| 参数名称 | 说明 |
|---|---|
| x | 接收数组或Series。代表需要进行离散化处理的数据。无默认 |
| bins | 接收int,list,array,tuple。若为int,代表离散化后的类别数目;若为序列类型的数据,则表示进行切分的区间,每两个数间隔为一个区间。无默认 |
| right | 接收boolean。代表右侧是否为闭区间。默认为True |
| labels | 接收list,array。代表离散化后各个类别的名称。默认为空 |
| retbins | 接收boolean。代表是否返回区间标签。默认为False |
| precision | 接收int。显示的标签的精度。默认为3 |
- 使用等宽法离散化的缺陷为:等宽法离散化对数据分布具有较高要求,若数据分布不均匀,那么各个类的数目也会变得非常不均匀,有些区间包含许多数据,而另外一些区间的数据极少,这会严重损坏所建立的模型。
pd.cut(data['amounts'],bins=5)
0 (36.4, 71.8]
1 (36.4, 71.8]
2 (0.823, 36.4]
3 (0.823, 36.4]
4 (0.823, 36.4]
...
10032 (0.823, 36.4]
10033 (0.823, 36.4]
10034 (36.4, 71.8]
10035 (0.823, 36.4]
10036 (0.823, 36.4]
Name: amounts, Length: 10037, dtype: category
Categories (5, interval[float64]): [(0.823, 36.4] < (36.4, 71.8] < (71.8, 107.2] < (107.2, 142.6] < (142.6, 178.0]]
统计频数:
pd.cut(data['amounts'],bins=5).value_counts()
(0.823, 36.4] 5461
(36.4, 71.8] 3157
(71.8, 107.2] 839
(142.6, 178.0] 426
(107.2, 142.6] 154
Name: amounts, dtype: int64
4.2.3、等频法
- cut函数虽然不能够直接实现等频离散化,但是可以通过定义将相同数量的记录放进每个区间。
- 等频法离散化的方法相比较于等宽法离散化而言,避免了类分布不均匀的问题,但同时却也有可能将数值非常接近的两个值分到不同的区间以满足每个区间中固定的数据个数。
def samefreq(data, k):
w = data.quantile(np.arange(0,1 + 1/k, 1/k))
return pd.cut(data, w)
samefreq(data['amounts'], k=5).value_counts()
(18.0, 32.0] 2107
(39.0, 58.0] 2080
(32.0, 39.0] 1910
(1.0, 18.0] 1891
(58.0, 178.0] 1863
Name: amounts, dtype: int64
4.2.4、基于聚类分析的方法
- 一维聚类的方法包括两个步骤:
- 将连续型数据用聚类算法(如K-Means算法等)进行聚类。
- 处理聚类得到的簇,将合并到一个簇的连续型数据做同一标记。
- 聚类分析的离散化方法需要用户指定簇的个数,用来决定产生的区间数。
- k-Means聚类分析的离散化方法可以很好地根据现有特征的数据分布状况进行聚类,但是由于k-Means算法本身的缺陷,用该方法进行离散化时依旧需要指定离散化后类别的数目。此时需要配合聚类算法评价方法,找出最优的聚类簇数目。