eBPF Up & Running: Overview

凌云时刻 · 技术


导读:eBPF 技术是近几年 Linux 社区一颗闪亮的明星,如果你还没有开始接触并编写过 eBPF 程序,那么不要错过,接下来的一系列文章非常适合你。(本文为连载文章,上一篇:eBPF Internal: Instructions and Runtime)
作者 | 荣旸
来源 | 凌云时刻(微信号:linuxpk)
前言

eBPF Up & Running 系列文章目前主要包括下面三篇:
Overview 总览,你的第一个 eBPF 程序将会在这里诞生;
Tracing 跟踪,eBPF 如何在 tracing 场景大展身手;
Network 网络,如何使用 eBPF 增强内核网络;
接下来会随着 eBPF 的发展和大家的反响情况,不断丰富扩展更多的文章。废话不多说,让我们开始接下来的干货时间。
简介
在写第一行代码之前,首先让我们了解一下 eBPF 技术前世今生。
回到 1992 年,eBPF 的前身 BPF (Berkeley Packet Filter),现在被成为 cBPF (classic BPF) ,主要用于 tcpdump 和 seccomp,场景无外乎是一种灵活的 DSL + 虚拟机帮助用户筛选数据。用户的过滤条件会被编译为 cBPF 程序,程序由预先定义的指令组成,这些指令在内核中解释运行,并通过 JIT 加速执行速度,每当数据经过时,会触发程序执行并判断是否满足筛选条件。
时间很快来到了 2011 年,eBPF 在这一年诞生了。经过社区的不断迭代和完善,eBPF 在各个方面得到增强:
定义了全新的指令架构,复用了 cBPF 的 opcode 格式和命令,并引入了大量的寄存器;
LLVM 后端支持 BPF target,可以将 C 程序编译为 eBPF 字节码并在内核中运行;
引入了 bpf.h 等头文件的支持和丰富的 helpers 函数,简化了 eBPF 程序的编写;
eBPF 是如何在内核中的执行的?eBPF Internal: Instructions and Runtime 文章中有更详细的介绍,下图展示了 eBPF 程序的大体执行流程。
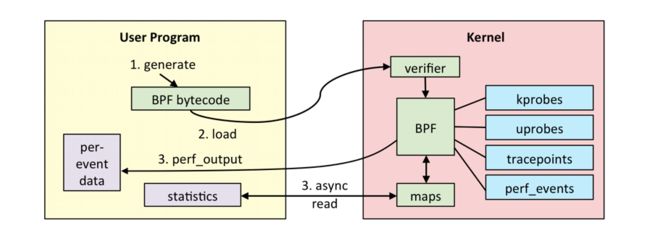
其实 eBPF 本身其实远没有想象中的复杂,我们可以把内核想象成一个庞大而复杂的电路,如果电路出现了异常,我们可以通过使用万用表测量电路,如果当前电路不能满足需求,但又不能推倒重新设计,我们需要串入其他元件。eBPF 之于电路,既是万用表,也是各种功能元件。再回到内核中的 eBPF,内核预先在各个关键路径埋设了 eBPF 程序入口,用户可以编写不同类型的 eBPF 程序,将 eBPF 程序 attach 在内核中不同路径中执行。
示例:流量协议统计
 搭建脚手架
搭建脚手架
在编写第一个程序之前,我们需要准备一个顺手的开发环境。内核源码仓库 samples/bpf 目录下包含了数十个典型的 eBPF 示例程序,除了可供学习和参考之外,我们可以将程序代码放在这个目录,无需自己额外花时间编写和调试 Makefile。
代码编写
eBPF 程序本质上是一种字节码,我们只需将编写的代码编译成 eBPF 字节码,即可在内核的 eBPF 虚拟机中运行。理论上我们可以使用各种现有的语言编写 eBPF 程序,只要确保这门语言具有对应的 LLVM 前端,帮助我们将其翻译为 LLVM IR 中间代码,并通过 LLVM 最终编译为 eBPF 字节码。通常情况下,推荐使用 C 进行编写,当前内核提供了完备的 C library。因此我们需要确保 clang 已经正确配置好,如果已经按照上面步骤正确配置了脚手架,我们无需再配置 clang 和 LLVM。
对于大部分场景下 eBPF 编程模型,eBPF 程序不是单独出现,而是由用户态控制平面 control plane 和内核态数据平面 data plane 两部分组成,经典的数据面和控制面分离。
接下来我们将以samples/bpf/{xdp1_kern.c,xdp1_user.c} 程序为例,这个示例不只是简单的打印,它可以统计网卡的数据报文的协议分布数量。
首先是内核态的 eBPF 代码:xdp1_kern.c,主要功能是从数据报文中解析并判断协议类型,统计数据报文中不同协议的数量分布情况。
/* 其他省略,完整源码请参考 samples/bpf/xdp1_kern.c */
/* 定义数据结构存放统计信息 */
struct bpf_map_def SEC("maps") rxcnt = {
.type = BPF_MAP_TYPE_PERCPU_ARRAY,
.key_size = sizeof(u32),
.value_size = sizeof(long),
.max_entries = 256,
};
SEC("xdp1")
/* eBPF XDP 类型程序的特定函数签名,ctx 包含数据包的上下文信息 */
int xdp_prog1(struct xdp_md *ctx)
{
/* 报文结束位置 */
void *data_end = (void *)(long)ctx->data_end;
/* 报文开始位置 */
void *data = (void *)(long)ctx->data;
struct ethhdr *eth = data;
long *value;
u16 h_proto;
u64 nh_off;
u32 ipproto;
nh_off = sizeof(*eth);
if (data + nh_off > data_end)
/* 对于非法报文直接返回 XDP_DROP 并丢弃 */
return XDP_DROP;
h_proto = eth->h_proto;
/* 接下来会根据数据报文依次解析协议类型 */
if (h_proto == htons(ETH_P_8021Q) || h_proto == htons(ETH_P_8021AD)) {
struct vlan_hdr *vhdr;
vhdr = data + nh_off;
nh_off += sizeof(struct vlan_hdr);
/* 判断数据包是否合法,否则直接丢弃 */
if (data + nh_off > data_end)
return XDP_DROP;
h_proto = vhdr->h_vlan_encapsulated_proto;
}
if (h_proto == htons(ETH_P_8021Q) || h_proto == htons(ETH_P_8021AD)) {
struct vlan_hdr *vhdr;
vhdr = data + nh_off;
nh_off += sizeof(struct vlan_hdr);
/* 判断数据包是否合法,否则直接丢弃 */
if (data + nh_off > data_end)
return XDP_DROP;
h_proto = vhdr->h_vlan_encapsulated_proto;
}
if (h_proto == htons(ETH_P_IP))
/* 从 payload 中解析 Ipv4 protocol */
ipproto = parse_ipv4(data, nh_off, data_end);
else if (h_proto == htons(ETH_P_IPV6))
/* 从 payload 中解析 Ipv6 protocol */
ipproto = parse_ipv6(data, nh_off, data_end);
else
ipproto = 0;
/* 统计不同协议的访问次数 */
value = bpf_map_lookup_elem(&rxcnt, &ipproto);
if (value)
*value += 1;
/* 返回 XDP_PASS 传递报文至下层处理逻辑 */
return XDP_PASS;
}
接下来是用户态代码:xdp1_user.c,主要功能是载入 eBPF 程序到内核中,并从内核共享的 map 中获得统计信息并展示。
/* 其他省略,完整源码请参考 samples/bpf/xdp1_kern.c */
static int ifindex;
static __u32 xdp_flags;
static void int_exit(int sig)
{
/* 将 XDP 与网卡解绑 */
bpf_set_link_xdp_fd(ifindex, -1, xdp_flags);
exit(0);
}
static void poll_stats(int map_fd, int interval)
{
unsigned int nr_cpus = bpf_num_possible_cpus();
const unsigned int nr_keys = 256;
__u64 values[nr_cpus], prev[nr_keys][nr_cpus];
__u32 key;
int i;
memset(prev, 0, sizeof(prev));
while (1) {
sleep(interval);
for (key = 0; key < nr_keys; key++) {
__u64 sum = 0;
/* 从 map 中获取统计信息 */
assert(bpf_map_lookup_elem(map_fd, &key, values) == 0);
for (i = 0; i < nr_cpus; i++)
sum += (values[i] - prev[key][i]);
if (sum)
printf("proto %u: %10llu pkt/s\n",
key, sum / interval);
memcpy(prev[key], values, sizeof(values));
}
}
}
int main(int argc, char **argv)
{
struct rlimit r = {RLIM_INFINITY, RLIM_INFINITY};
struct bpf_prog_load_attr prog_load_attr = {
/* 指定程序类型,这里为 XDP */
.prog_type = BPF_PROG_TYPE_XDP,
};
const char *optstr = "SN";
int prog_fd, map_fd, opt;
struct bpf_object *obj;
struct bpf_map *map;
char filename[256];
while ((opt = getopt(argc, argv, optstr)) != -1) {
switch (opt) {
case 'S':
/* XDP 两种工作模式,第三篇文章会详细展开 */
xdp_flags |= XDP_FLAGS_SKB_MODE;
break;
case 'N':
/* XDP 两种工作模式,第三篇文章会详细展开 */
xdp_flags |= XDP_FLAGS_DRV_MODE;
break;
default:
usage(basename(argv[0]));
return 1;
}
}
/* 省略不重要代码 */
snprintf(filename, sizeof(filename), "%s_kern.o", argv[0]);
prog_load_attr.file = filename;
/* 载入 eBPF 字节码至内核 */
if (bpf_prog_load_xattr(&prog_load_attr, &obj, &prog_fd))
return 1;
map = bpf_map__next(NULL, obj);
if (!map) {
printf("finding a map in obj file failed\n");
return 1;
}
/* 获得 eBPF 中定义的数据结构,用以获取统计信息 */
map_fd = bpf_map__fd(map);
/* 省略不重要代码 */
/* 设置 XDP 与网卡的绑定,eBPF 字节码将会在指定网卡收包路径执行 */
if (bpf_set_link_xdp_fd(ifindex, prog_fd, xdp_flags) < 0) {
printf("link set xdp fd failed\n");
return 1;
}
/* 定时从 map fd 中轮询统计数据 */
poll_stats(map_fd, 2);
return 0;
}
编译运行
在 Linux 源码仓库根目录执行 make samples/bpf/,编译完成后会在 samples/bpf 目录下会得到用户态可执行文件 xdp1 和 eBPF 字节码文件 xdp1_kern.o,直接在当前目录直接执行即可。如果是自己编写的代码,可以将文件放入 samples/bpf 目录下,并在 Makefile 中加入这对应文件的编译配置。
如果遇到了任何环境或者编译的问题,可以参考内核文档 samples/bpf/README.rst。
基础概念
通过上面的示例程序之后,想必大家已经对如何编写一个 eBPF 程序有了初步的印象。以刚才编写的程序为例,我们可以发现 eBPF 程序包含三个基础的概念:程序类型、数据结构和 helpers。
程序类型
eBPF 的程序类型 (program type),决定了 eBPF 程序如何载入内核,以及在内核哪些路径执行 eBPF 程序。例如需要 kprobe 跟踪函数执行,则需要在载入时指定 eBPF 程序的类型为 BPF_PROG_TYPE_KPROBE 。对于 XDP 则需要指定为 BPF_PROG_TYPE_XDP;
以 XDP 类型 eBPF 程序为例,用户通过 netlink 调用 dev_change_xdp_fd 为指定 dev 设置 eBPF 程序,例如 veth 网卡 XDP 的支持在 4.14 内核引入,通过 veth_xdp_set 为网卡绑定 eBPF 字节码,当 NAPI poll 执行时于每个 XDP frame 依次调用 veth_xdp_rcv_one,并执行对应的 eBPF 程序,根据 eBPF 程序的返回结果决定丢弃、通过或者重定向报文。
全量的程序类型定义在include/uapi/linux/bpf.h,如需了解详细的程序类型请参考:BCC 文档。
数据结构
对于任何程序而言,都离不开各种各样的数据结构。eBPF 提供了各种常用的数据结构,从而实现内核内部数据的组织,以及用户态和内核态的通信;
当前 eBPF 定义了26中基础的数据结构,涵盖了 hash、stack、array 和 ringbuf。以 hash 为例,可以指定 key、leaf 的数据类型以及大小,同时提供了相应的 helpers 操作函数 BPF_FUNC_map_lookup_elem()和 BPF_FUNC_map_push_elem() 等。
全量的数据结构定义在 include/uapi/linux/bpf.h,如需了解详细的数据结构列表请参考:BCC 文档。
Helpers
如同其他语言生态会提供丰富的 library,eBPF 也包含了各种常用的 helpers 函数,例如打印输出 BPF_FUNC_trace_printk 等;
eBPF 定义的 helpers 函数不仅为了简化复杂的 eBPF 操作,同时也会将部分危险的操作封装成安全的 helpers 函数,对于内核数据结构的访问和操作需要借助 helper 完成,确保了 eBPF 程序的安全性。
全量的 helpers 定义在include/uapi/linux/bpf.h,详细的 helps 列表请参考:BCC 文档
快速上手的应用
学习并掌握一门技术的最好方式是付诸于实践。现在你的脑海中可能已经迸发出各种各样的想法,迫不及待编写 eBPF 程序验证和实践。为了更方便的去验证和实践,除了上面提到的基于 samples/bpf 示例程序之外,我们还可以基于下面一些社区已有的可供我们快速上手的应用。
BCC
BCC 是一个包含丰富的内核跟踪分析的 eBPF 工具集,用户也可以基于 BCC 创建自己的 eBPF 工具。当前 BCC 工具提供了 Python / Lua 和 Go 语言的 binding,用户可以使用这三种语言编写自己的 eBPF 工具。BCC 提供一个非常友好的 tutorial 可供大家快速上手。其中 iovisor/gobpf 库,可以通过 Go 生态将 eBPF 与云原生、k8s 或各种运维工具相结合。
bpftrace
如果使用过 systemtap 动态跟踪分析内核,那么 bpftrace 是一个很好的替代方案。bpftrace 提供了一种类 awk 和 C 的语言,使用 bpftrace 语言编写各种跟踪和分析脚本,并编译成 eBPF 字节码与内核交互,从而实现动态跟踪 Linux 内核。使用文档可以参考:使用 bpftrace 分析内核,和 The bpftrace One-Liner Tutorial。
ubpf / generic-ebpf
假如对于 eBPF 字节码和虚拟机非常感兴趣,ubpf 提供了一个用户态实现的虚拟机,包含了解释运行和 JIT 特性。不仅帮助我们更好的理解 eBPF 虚拟机的实现,而且可以将 ubpf 嵌入到应用中,以执行编写好的 eBPF 程序,从而实现 Lua 或 WASM 的功能。generic-ebpf 则更进一步,提供了更完善的运行时机制和库函数,并将 eBPF 作为一种通用的字节码嵌入到交换机等硬件中并运用在生产环境。
总结
eBPF 为内核提供了更多的可能性,社区仍在不断拓宽 eBPF 的场景,通过这篇文章我们了解了如何编写 eBPF 程序,接下来几篇文章将会为大家带来 eBPF 在跟踪和网络方面的特性和应用。
END

往期精彩文章回顾

容器技术在企业落地的最佳实践
节约服务器成本50%以上,独角兽完美日记电商系统容器化改造历程
投入产出比增长2倍以上!银泰抛弃传统数据库转投阿里云PolarDB
阿里云SAE助力百富旅行实现Serverless+微服务完美结合
关于Kubernetes规划的灵魂N问
饿了么四年、阿里两年:研发路上的一些总结与思考
再启程,Service Mesh 前路虽长,尤可期许
数据湖:设计更好的架构,存储,安全和数据治理
RocketMQ助力编程猫构建稳定的业务系统
云上发展,唯快不破!IT部门是数字化转型的变革者

长按扫描二维码关注凌云时刻
每日收获前沿技术与科技洞见