更新中。。。
第二章
2.2.2 交通规则
几种常见的渐近运行时间实例
| 时间复杂度 | 相关名称 | 相关示例及说明 |
|---|---|---|
| O(1) | 常数级 | 哈希表的查询与遍历 |
| O(lgn) | 对数级 | 二分搜索 |
| O(n) | 线性级 | 列表的遍历 |
| O(nlgn) | 线性对数级 | 任意值序列的最优化排序 |
| O($n^2$) | 平方级 | n 个对象相互比较 |
| O($n^3$) | 立方级 | Floyd-Warshall |
| O($n^k$) | 多项式级 | 基于 n 的 k 层嵌套循环 |
| O($k^n$) | 指数级 | 每 n 项产生一个子集 |
| O(n!) | 阶乘级 | 对 n 个只看进行全排列操作 |
2.2.4 三种重要情况
这里有一个 else 的例子,用法并不常见,下面的代码中,如果循环,没有被 break 语句提前终止,那么将会执行 else分支!
def sort_w_check(seq):
n = len(seq)
for i in range(n-1):
if seq[i] > seq[i+1]:
break
else:
return
排序算法的三种情况:
- 最好情况
- 最坏情况
- 平均情况
2.3 图与树的实现
图结构(graph) 算法学中最强大框架之一。在许多情况下,我们都可以把一个问题抽象为一个图,如果能抽象为一个图的话,那么该问题至少已经接近解决方案了。如果问题实例可以用树(tree)诠释的话,那么我们基本上已经拥有了一个真正有效的的解决方案了。
下面是一些关于图的术语:
- 图 G = (V,E) 通常由一组节点 V 及节点间的边 E 共同组成。如果这些边有方向,就称其为有向图。
- 节点之间通过边来实现彼此相连的。而这些边其实就是节点 v 与其邻居之间的关系。
- G = (V,E] 的子图结构将由 V 和 E 的子集共同组成。在 G 中,每一条路径(path)是一个子图结构,它们本质上都是一些由多个节点串联而成的边线序列。环路(cycle)的定义与路径基本相同,只不过它的最后一条边所连接的末节点同是是它的首节点。
- 如果我们将图 G 中的边与某种权值联系在一起,G 就成了一种加权图。在加权图中,一条路径或环路的长度等于各边上的权值之和,对非加权图来说,就直接等于该图的边数。
- 森林 (forest) 可以被认为是一个无环路图,而这样的连通图就是一棵树。换言之,森林就是由一棵或多棵树构成的。
2.3.1 邻接列表及其类似结构
对于图结构的实现来说,邻接列表是最直观的方式之一。
接下来,我们就要用数据结构来表示图。
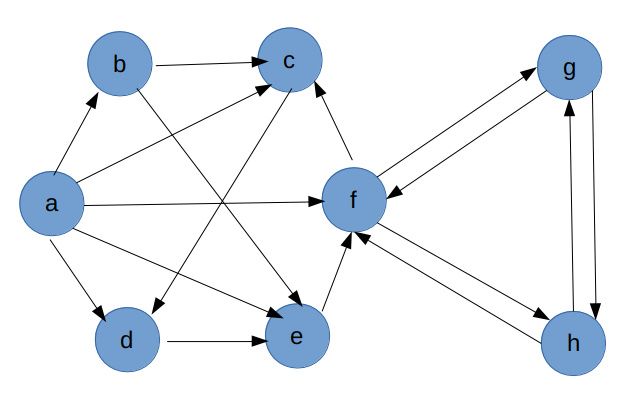
图 2-3
清单 2-1 简单明了的邻接集表示法
a, b, c, d, e, f, g, h = range(8)
N = [
{b, c, d, e, f}, # a 的所有出边,下同
{c, e}, # b
{d}, # c
{e}, # d
{f}, # e
{c, g, h}, # f
{f, h}, # g
{f, g} # h
]
In [9]: b in N[a] # b 是 a 的邻居
Out[9]: True
In [10]: len(N[f]) # f 有3个邻居
Out[10]: 3
清单 2-2 邻接列表
a, b, c, d, e, f, g, h = range(8)
N = [
[b, c, d, e, f], # a 的所有出边,下同
[c, e], # b
[d], # c
[e], # d
[f], # e
[c, g, h], # f
[f, h], # g
[f, g] # h
]
清单 2-3 加权邻接字典
a, b, c, d, e, f, g, h = range(8)
N = [
{b:2, c:1, d:3, e:9, f:4}, # a 的所有出边及权值,下同
{c:4, e:3}, # b
{d:8}, # c
{e:7}, # d
{f:5}, # e
{c:2, g:2, h:2}, # f
{f:1, h:6}, # g
{f:g, g:8} # h
]
以上三种邻接结构的主容器都属于列表类型,都是以节点编号为索引值。dict 更灵活。
2.3.2 邻接矩阵
图的另一种表示方法就是邻接矩阵了。它的不同之处在于,它不再列出每个节点的所有邻居节点,而是将所有可能的邻居位置排一行(也就是一个数组,用于对应图中每一个节点),然后使用某种值(True or False)来表示其是否为当前节点的邻居。与上面一样,依然使用最简单的列表来表示。同是为了让矩阵有较好的可读性,我们将使用1和0来表示真值。且节点的编号从0开始。
清单 2-5
a, b, c, d, e, f, g, h = range(8)
# a b c d e f g h
N = [[0, 1, 1, 1, 1, 1, 0, 0], # a
[0, 0, 1, 0, 1, 0, 0, 0], # b
[0, 0, 0, 1, 0, 0, 0, 0], # c
[0, 0, 0, 0, 1, 0, 0, 0], # d
[0, 0, 0, 0, 0, 1, 0, 0], # e
[0, 0, 1, 0, 0, 0, 1, 1], # f
[0, 0, 0, 0, 0, 1, 0, 1], # g
[0, 0, 0, 0, 0, 1, 1, 0]] # h
同是,其使用方法也略有不同[1],这里检查的不是 b 是否在 N[a]中,而是检查矩阵单元 N[a][b] 是否为真。同样,要获取相关节点的邻居数,改用 sum 函数即可,因为,所有行的长度是相等的!
In [6]: N[a][b]
Out[6]: 1
In [7]: sum(N[f])
Out[7]: 3
特点:
- 在不允许自循环的状态下,对角线上的值全为假。
- 无向图矩阵是一个对称矩阵
加权处理:
- 只需在存储真值的地方直接存储相应权值即可。
- 出于实践因素考虑,通常把实际不存在的边的权值设为无穷大(
float('inf'))
清单 2-6 对不存在的边赋予无限大权值的加权矩阵
a, b, c, d, e, f, g, h = range(8)
inf = float('inf')
W = [[ 0, 2, 1, 3, 9, 4, inf, inf], # a
[inf, 0, 4, inf, 3, inf, inf, inf], # b
[inf, inf, 0, 8, inf, inf, inf, inf], # c
[inf, inf, inf, 0, 7, inf, inf, inf], # d
[inf, inf, inf, inf, 0, 5, inf, inf], # e
[inf, inf, 2, inf, inf, 0, 2, 2], # f
[inf, inf, inf, inf, inf, 1, 0, 6], # g
[inf, inf, inf, inf, inf, 9, 8, 0]] # h
加权矩阵使得相关加权边的访问变得容易,但需要对相关无穷大值进行检测
In [23]: W[a][b]
Out[23]: 2
In [24]: W[c][e] < inf
Out[24]: True
In [25]: sum(1 for w in W[a] if w < inf) - 1
Out[25]: 5
这里减去 1 是排除掉对角线的 0
2.3.3 树的实现
一般来说,可以表示成图的方法都能用来表示树,树是图的特殊情况。
最简单的树: 带根树结构

此树的代码表示:
In [35]: T = [["a", "b"], ["c"], ["d", ["e", "f"]]]
In [36]: T[0][1]
Out[36]: 'b'
In [37]: T[2][1][0]
Out[37]: 'e'
清单 2-7 二叉树类
class Tree:
def __init__(self, left, right):
self.left = left
self.right = right
In [39]: t = Tree(Tree('a', 'b'), Tree('c', 'd'))
In [40]: t.right.left
Out[40]: 'c'
上例可描述为下图:

清单 2-8 多路搜索树
对于没有 list内置类型的语言,可以采用“先子节点,后兄弟节点的”的表示法!
class Tree:
def __init__(self, kids, next=None):
self.kids = self.val = kids
self.next = next
这里的 val 只是为相关的值提供更具描述性的名称,可以自行更换其他你喜欢的。
In [62]: t = Tree(Tree('a', Tree('b', Tree('c', Tree('d')))))
In [64]: t.kids.next.next.val
Out[64]: 'c'
In [77]: t.kids.val
Out[77]: 'a'
In [47]: t.kids.kids
Out[47]: 'a'
In [69]: t.kids.next.val
Out[69]: 'b'
In [72]: t.kids.next.next.next.val
Out[72]: 'd'
Bunch模式:
class Bunch(dict):
def __int__(self, *args, **kwds):
super(Bunch, self).__init__(*args, **kwds)
self.__dict__ = self
In [56]: t = T(left=T(left='a', right='b'), right=T(left='c'))
In [57]: t
Out[57]: {'left': {'left': 'a', 'right': 'b'}, 'right': {'left': 'c'}}
In [60]: t['left']['left']
Out[60]: 'a'
In [61]: 'left' in t['right']
Out[61]: True
In [62]: 'right' in t['right']
Out[62]: False
用处:
- 可以以命令行参数的形式创建相关对象并设置属性。
- 继承自
dict可以自然获得大量相关的内容。
2.3.4 多种表示法
图表示法的草见解:
- 图可以由邻接列表和邻接矩阵两种方法表示。
- 邻接矩阵速度快,但消耗资源多。二者的选择取决于哪种资源更重要。
2.4 请提防黑盒子
“黑盒子”: 项目中非自己所写的依赖。
提防陷阱的方法:
- 性能很重要时,要着重于实际分析而不是直觉。
- 正确性很重要时,使用不同的方法进行多次计算并交由不同的程序员编写
2.4.1 隐形平方级操作
In [63]: from random import randrange
In [64]: L = [randrange(10000) for i in range(1000)]
In [65]: 42 in L
Out[65]: False
In [66]: S = set(L)
In [67]: 42 in S
Out[67]: False
在 list 上构建 set貌似毫无意义。但如果是下面两中情况就会很适用:
- 执行多次查询时,
list是线性级,而set是常数级的。 - 向其中添加新值时,
list是平方级,而set是线性级!
res = []
for lst in lists:
res.extend(lst)
上式要优于
>>> lists = [[1, 2], [3, 4], [5, 6]]
>>> sum(lists, [])
2.4.2 浮点数的麻烦
不要对浮点数进行比较
第三章 计数初步
3.4.2
递归调用的一般形式:T(n) = a.T(g(n)) + f(n)。其中
a: 递归调用数量
g(n): 递归调用过程中,所要解决的子问题大小。
f(n): 函数的额外操作
一些基本递归式的解决方案及其实例
| 0 | 递归式 | 复杂度 | 实例 |
|---|---|---|---|
| 1 | T(n)=T(n-1)+1 | O(n) | 序列化处理问题,如归简操作 |
| 2 | T(n)=T(n-1)+n | O($n^2$) | 握手问题 |
| 3 | T(n)=2T(n-1)+1 | O($2^n$) | 汉诺塔问题 |
| 4 | T(n)=2T(n-1)+n | O($2^n$) | |
| 5 | T(n)=T(n/2)+1 | O(lgn) | 二分搜索 |
| 6 | T(n)=T(n/2)+n | O(n) | 随机问题 |
| 7 | T(n)=2T(n/2)+1 | O(n) | 树的遍历 |
| 8 | T(n)=2T(n/2)+n | O(nlgn) | 分治法排序 |
如遇到其他的递归式,可以尝试向如上基本式化简。来求得其复杂度!
3.5
侏儒排序
def gnome_sort(seq):
if len(seq) <= 1:
return seq
i = 1
while i < len(seq):
if i == 0 or seq[i-1] <= seq[i]:
i += 1
else:
seq[i], seq[i-1] = seq[i-1], seq[i]
i -= 1
return seq
if __name__ == '__main__':
seq = [5, 3, 6, 9, 8, 2]
print(gnome_sort(seq))
应该不用做过多解释!使用Python Tutor可以看到此排序执行步数是74次。反正是没有分治法的归并排序速度快。而且在最坏情况下,其复杂度为O($n^2$)
In [7]: def mergesort(seq):
...: mid = len(seq)//2
...: lft = seq[:mid]
...: rgt = seq[mid:]
...: if len(lft) > 1:
...: lft = mergesort(lft)
...: if len(rgt) > 1:
...: rgt = mergesort(rgt)
...:
...: res = []
...: while lft and rgt:
...: if lft[-1] >= rgt[-1]:
...: res.append(lft.pop())
...: else:
...: res.append(rgt.pop())
...:
...: res.reverse()
...: return (lft or rgt) + res
第四章 归纳、递归及归简
- 归简法指的是将某一问题转化成另一个问题。
- 归纳法则被用于证明某个语句对于某种大型对象类是否成立!
- 递归法则主要被用与函数自我调用时。
4.1 哦,这其实很简单
归简
假设从一个数字列表中找出两个彼此相近但不相等的数。
In [80]: from random import randrange
In [123]: seq = [randrange(10**10) for i in range(100)]
In [124]: dd = float("inf")
In [125]: for x in seq:
...: for y in seq:
...: if x == y: continue
...: d = abs(x-y)
...: if d < dd:
...: xx, yy, dd = x, y, d
...:
In [126]: xx, yy
Out[126]: (9733435205, 9734468535)
两层嵌套的循环,都对seq遍历,明显的平方级操作。接下来我们就优化下代码,先把列表排序,绝对值最小的两个数必然是相邻。于是代码如下。
In [87]: seq.sort()
In [124]: dd = float("inf")
In [125]: for x in seq:
...: for y in seq:
...: if x == y: continue
...: d = abs(x-y)
...: if d < dd:
...: xx, yy, dd = x, y, d
...:
In [126]: xx, yy
Out[126]: (9733435205, 9734468535)
这样算法更快了,但解决方案照旧!
归纳法证明了递归法的适用性,而递归法则是直接实现归纳法思维的一种简单方式。
4.3
再来两个排序。(虽然以前写过多次。)
1. 插入排序迭代版
def ins_sort(seq):
if len(seq) <= 1:
return seq
for i in range(1, len(seq)):
j = i
while j > 0 and seq[j-1] > seq[j]:
seq[j], seq[j-1] = seq[j-1], seq[j]
j -= 1
return seq
if __name__ == "__main__":
seq = [5, 3, 6, 9, 8, 2]
print(ins_sort(seq))
递归版插入排序
def ins_sort_rec(seq, i):
if i == 0:
return seq
j = i
while j > 0 and seq[j-1] > seq[j]:
seq[j], seq[j-1] = seq[j-1], seq[j]
j -= 1
return ins_sort_rec(seq, i-1)
if __name__ == "__main__":
seq = [5, 3, 6, 9, 8, 2]
print(ins_sort_rec(seq, 5))
2. 选择排序
def sel_sort(seq):
for i in range(len(seq)-1, 0, -1):
max_j = i # 预设最大索引 max_j
for j in range(i):
if seq[j] > seq[max_j]:
max_j = j # 实际最大的 max_j
seq[i], seq[max_j] = seq[max_j], seq[i] # 交换最大值
return seq
if __name__ == "__main__":
seq = [5, 3, 6, 9, 8, 2]
print(sel_sort(seq))
4~6行类似寻找一组数字中的最大值。这里是找最大的索引值!
递归版
def sel_sort_rec(seq, i):
if i == 0: return seq
max_j = i
for j in range(i):
if seq[j] > seq[max_j]:
max_j = j
seq[i], seq[max_j] = seq[max_j], seq[i]
return sel_sort_rec(seq, i-1)
if __name__ == "__main__":
seq = [5, 3, 6, 9, 8, 2]
print(sel_sort_rec(seq, 5))
4.4 基于归纳法(与递归法)的设计
4.4.1 寻找最大排列
有 a, b, c, d, e, f, g, h 八个人。在电影院更换座位的问题!
箭头指向就是他们想要的座位。我们可以从图中找出其映射关系。这里就是各元素(0, ... n-1)与其位置(0, ... n-1)之间的关联性。我们可以用一个简单的列表实现。(各元素选择的座位作为其值。)
>>> M = [2, 2, 0, 5, 3, 5, 7, 4]
接下来就可以简单的实现下了。
- 寻找最大排列问题的递归思路的朴素解决方案
In [8]: def naive_max_perm(M, A=None):
...: if A is None:
...: A = set(range(len(M)))
...: if len(A) == 1:
...: return A
...: B = set(M[i] for i in A)
...: C = A - B
...: if C:
...: A.remove(C.pop())
...: return naive_max_perm(M, A)
...: return A
In [10]: naive_max_perm(M)
Out[10]: {0, 2, 5}
这段代码中,函数naive_max_perm收到一个代表剩余人数的集合A, 并创建一个被指向座位的集合B。然后此函数会找出并删除集合A中某个不属于集合B的元素。之后,递归解决剩余人员。直至 A = B。
此程序是平方级操作,最浪费的操作就是每次递归时集合B都要重复创建。为此能解决这个问题,我们也就可以将其复杂度变成线性级了!
我们可以为各元素设置一个计数器,当有指向x座位的人被淘汰时,就递减该座位的计数器,并当x的计数器为0时,将编号为x的人和座位一同淘汰掉即可。
- 迭代版实现
def max_perm(M):
n = len(M)
A = set(range(n))
count = [0]*n
for i in M:
count[i] += 1 # 相当于 count = collections.Counter(M)
Q = [i for i in A if count[i] == 0]
while Q:
i = Q.pop()
A.remove(i)
j = M[i]
count[j] -= 1
if count[j] == 0:
Q.append(j)
return A
计数排序
from collections import defaultdict
def count_sort(seq, key=lambda x: x):
L, D = [], defaultdict(list)
for i in seq:
D[key(i)].append(i)
# D -- {0: [0], 2: [2, 2], 3: [3], 4: [4], 5: [5, 5], 7: [7]})
#这里顺序恰巧是排序好的,仅仅是巧合而已
for key in range(min(D), max(D)+1):
L.extend(D[key]) # 根据key来排序,而key的大小和value是对应的。当key不在D中时,返回 []
# key的值从小到大,不受D中元素的顺序影响
return L
M = [2, 2, 0, 5, 3, 5, 7, 4]
print(count_sort(M))
defaultdict 简化了处理不存在的键的场景。
w = ['a', 'b', 'w', 'r']
d = {}
for i in w:
if i in d:
d[i] += 1
else:
d[i] = 1
# use defaultdict
d = defaultdict()
for i in w:
d[i] += 1
下面是python官方文档的例子。
>>> s = [('yellow', 1), ('blue', 2), ('yellow', 3), ('blue', 4), ('red', 1)]
>>> d = defaultdict(list)
>>> for k, v in s:
... d[k].append(v)
...
>>> d.items()
[('blue', [2, 4]), ('red', [1]), ('yellow', [1, 3])]
4.4.2 明星问题
所谓明星简单说: 就是别人都认识ta,而ta不认识别人。此算法有以下几种用处:
- 处理
Linux中各种软件包的依赖问题! - 多线程的死锁问题
def naive_celeb(G): # 寻找 G 中的明星, G 是一个二维数组.
n = len(G)
for u in range(n): # 遍历每个数组
for v in range(n): # 遍历数组中的每个元素
if u == v: continue # 相同的人,跳过
if G[u][v]: break # 明星认识路人, 结束此次循环
if not G[v][u]: break # 路人不认识明星, 结束
else:
return u # u 是明星
return None
可以很明显的看出, naive_celeb 函数的两次循环致使此程序的复杂度 O($n^2$).现在我们就要使用归简法将问题的规模从 n 归简到 n-1,其实,对每个 u 都进行遍历是多余的,因为非明星认识不需再往下进行了,所以要做的就是排除掉非明星人士即可.下面就要解决这个问题,将其变为一个线性级的算法.
def celeb(G):
n = len(G)
u, v = 0, 1 # 假设 u 是明星
for c in range(2, n+1):
if G[u][v]: u = c # u 认识 v,说明 u 不是明星,循环变量 c 赋值给 u,遍历下一组.
else: v = c # u 是明星, c 赋值给 v 遍历G(u)中的下一个元素
if u == n: c = v # 最后一次遍历后,u == n 说明 u 不是明星,则 v 是.
else: c = u # u是明星,这是的 c 不是循环变量了.只是一个中间值,可以换成其他已声明的变量
for v in range(n):
if c == v: continue # 同一个人, 跳过
if G[c][v]: break # 明星 c 认识路人, 卡
if not G[v][c]: break # 路人不识明星, 卡
else:
return c
return None
接下来,就要构建一个随机图,来验证函数的正确与否!
In [273]: from random import randrange
...: n = 100
...: G = [[randrange(2) for i in range(n)] for _ in range(n)]
...: x = randrange(n) # 设置一个明星 x
...: for i in range(n):
...: G[i][x] = True # 所有人都认识明星 x
...: G[x][i] = False # 明星 x 不认识任何人
...:
In [274]: x
Out[274]: 19
In [275]: naive_celeb(G)
Out[275]: 19
In [276]: celeb(G)
Out[276]: 19
4.4.3 拓扑排序问题 #看不太懂, mark
定义:
在图论中,由一个有向无环图的顶点组成的序列,当且仅当满足下列条件时,称为该图的一个拓扑排序(英语:Topological sorting)。
- 每个顶点出现且只出现一次;
- 若A在序列中排在B的前面,则在图中不存在从B到A的路径。
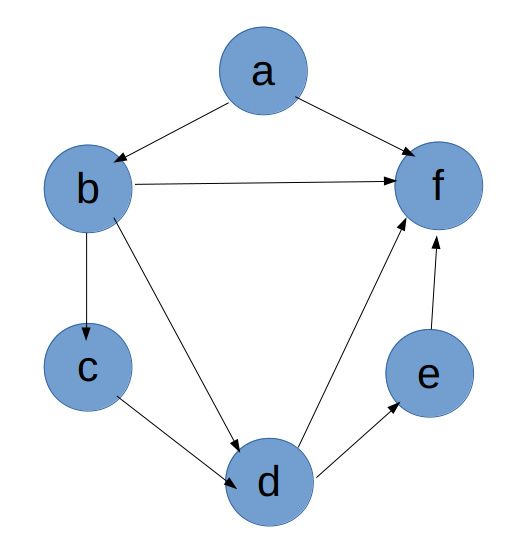
- 解决任务之间的依赖关系
当我使用 Debian 安装软件时,系统会提示缺少某个或某些组件,需要安装它们。对于这一类工作,相关组件必须按照一定的拓扑顺序来安装!接下来就实现下此算法。
清单 4-9 朴素版拓扑排序法
def naive_topsort(G, S=None):
if S is None: S = set(G) # all the nodes
if len(S) == 1: # single node, return
return list(S)
v = S.pop()
seq = naive_topsort(G, S)
min_i = 0
for i, u in enumerate(seq):
if v in G(u):
min_i = i + 1
seq.insert(min_i, v)
return seq
这是一个平方级算法,当每次任意选择一个节点时,其都要检查其余节点是否符合后续递归调用(线性操作)。因此,我们只要在递归调用之前找出被移除的节点即可。
def topsort(G):
count = dict((u, 0) for u in G)
for u in G:
for v in G(u):
count[v] += 1
Q = [u for u in G if count[u] == 1]
S = []
while Q:
u = Q.pop()
S.append(u)
for v in G[u]:
count[v] -= 1
if count[v] == 0:
Q.append(v)
return S
第五章 遍历:算法学中的万能钥匙
清单 5-1 遍历一个表示为邻接集的图结构的连通分量
def walk(G, s, S=set()): # G 是一邻接集的字典表示
P, Q = dict(), set()
P[s] = None
Q.add(s)
while Q:
u = Q.pop()
for v in G[u].difference(P, S): # v 是 set 对象
Q.add(v)
P[v] = u
return P
我们初开始可以找一个出发点作为根节点,然后从此节点开始走,我们可以往左走,可以往右走,随你。当我们走到一个死胡同时,就要进行回溯。
walk 函数所遍历的只是单个分量,下面这个该图的所有连通分量。
测试一下:
In [16]: G2 = {
...: 0:{1, 2},
...: 1:{1, 3},
...: 2:{2, 4},
...: 3:{0, 3},
...: 4:{4, 5},
...: 5:{2, 3}
...: }
In [26]: walk(G2, 1)
Out[26]: {0: 3, 1: None, 2: 0, 3: 1, 4: 2, 5: 4}
In [27]: walk(G2, 0)
Out[27]: {0: None, 1: 0, 2: 0, 3: 1, 4: 2, 5: 4}
清单 5-2 找出图的连通分量
def component(G):
comp = []
seen = set()
for u in G:
C = walk(G, u)
seen.update(C)
comp.append(C)
return comp
测试一下:
In [18]: component(G2)
Out[18]:
[{0: None, 1: 0, 2: 0, 3: 1, 4: 2, 5: 4},
{0: 3, 1: None, 2: 0, 3: 1, 4: 2, 5: 4},
{0: 3, 1: 0, 2: None, 3: 5, 4: 2, 5: 4},
{0: 3, 1: 0, 2: 0, 3: None, 4: 2, 5: 4},
{0: 3, 1: 0, 2: 5, 3: 5, 4: None, 5: 4},
{0: 3, 1: 0, 2: 5, 3: 5, 4: 2, 5: None}]
挺好的。
5.1 公园漫步
5.1.1 不允许出现环路
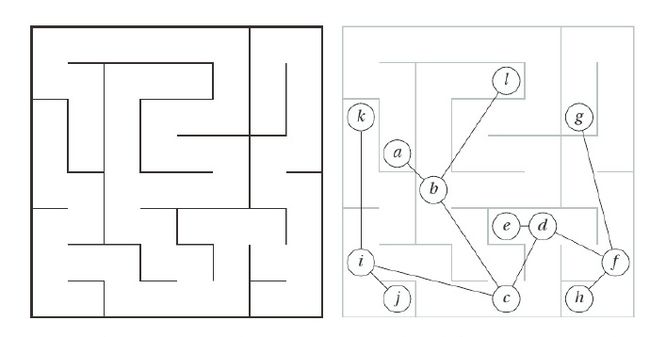
遍历一个没有环路的迷宫,其基本结构是一棵数。保持单手扶墙走就能遍历整个迷宫。其迷宫只有一面内墙,只要不出现环路,我们总能到达一个确定的地方。我们初开始可以找一个出发点作为根节点,然后从此节点开始走,我们可以往左走,可以往右走,随你。当我们走到一个死胡同时,就要进行回溯。顺着这样的策略,我们就能探索到所有节点,而且每条通道都会经过两次。下面是一个最基本的的实现。
清单 5-3 递归的树遍历算法
def tree_walk(T, r): # 从 r 开始遍历
for u in T[r]: # 对于每一子节点...
tree_walk(T, u) # ...遍历子树
5.1.2 停止循环遍历的方式
每次进入或离开一个十字路口时留下一个标志就行了。避免重复走同一条通道。下面是一个 Tremaux 算法。所使用的是深度优先搜索。(最基本最重要的遍历策略之一)
清单 5-4 递归版的深度优先搜索
def rec_dfs(G, s, S=None):
if S is None:
S = set()
S.add(s)
for u in G[s]:
if u in S:
continue
rec_dfs(G, u, S)
下面将递归操作转换成迭代版,以此来避免调用栈被塞满带来的问题。
清单 5-5 迭代版深度优先搜索
def iter_dfs(G, s):
S, Q= set(), []
Q.append(s)
while Q:
u = Q.pop()
if u in S: # 遍历过的就跳过
continue
S.add(u)
Q.extend(G[u])
yield u
用图2-3 的图结构测试一下测试看看
In [71]: a, b, c, d, e, f, g, h = range(8)
...: G = {
...: a: [b, c, d, e, f], # a 的所有出边,下同
...: b: [c, e], # b
...: c: [d], # c
...: d: [e], # d
...: e: [f], # e
...: f: [c, g, h], # f
...: g: [f, h], # g
...: h: [f, g] # h
...: }
In [73]: list(iter_dfs(G, 0))
Out[73]: [0, 5, 7, 6, 2, 3, 4, 1]
我们刚才是在一个有向图上进行的 DFS 。DFS或者其他遍历算法都适用于有向图上,但如果在有向图上进行遍历时,就不能指望它探索所有的连通分量了。比如下面:
In [74]: list(iter_dfs(G, 1))
Out[74]: [1, 4, 5, 7, 6, 2, 3
因为 a 节点不存在入边, 从 a 节点以外的任何一点出发都不能到达 a 节点!但我们可以有以下三种方法来找出有向图中的连通分量:
- 将有向图转换为无向图
- 直接为图中的所有边添加反向边
- 选择合适的起始节点
清单 5-6 通用性的图遍历函数
def traverse(G, s, qtype=set):
S, Q = set(), qtype()
Q.add(s)
while Q:
u = Q.pop()
if u in S:
continue
S.add(u)
for v in G[u]:
Q.add(v)
yield u
这里默认类型为 set ,我们也可以将其轻松定义成 stack 类型。使用的是一个是 List 的 append 和 pop 方法来模栈。
class stack(list):
add = list.append
测试下看看喽:
In [82]: list(traverse(G, 0, stack))
Out[82]: [0, 5, 7, 6, 2, 3, 4, 1]
5.2
深度优先的时间戳与拓扑排序
在 DFS 树中,任意 u 节点下的所有节点都应该在 u 被访问并完成回溯操作之间这段时间内处理完成。为此,我们为清单 5-6 的版本中的每个节点添加时间戳。
- d 代表它被探索的时间
- f 代表回溯的时间
def dfs(G, s, d, f, S=None, t=0):
if S is None:
S = set()
d[s] = t
t += 1
S.add(s)
for u in G[s]:
if u in S:
continue
t = dfs(G, u, d, f, S, t)
f[s] = t
t += 1
return t
我们还可以此 DFS 来进行拓扑排序,根据其递减的完成时间对节点进行排序。
清单 5-8
def dfs_topsort(G):
S, res = set(), []
def recurse(u):
if u in S:
return
S.add(u)
for v in G[u]:
recurse(v)
res.append(u)
for u in G:
recurse(u)
res.reverse()
return res
用 G 测试一下:
In [5]: G
Out[5]:
{0: [1, 2, 3, 4, 5],
1: [2, 4],
2: [3],
3: [4],
4: [5],
5: [2, 6, 7],
6: [5, 7],
7: [5, 6]}
In [14]: dfs_topsort(G)
Out[14]: [0, 1, 2, 3, 4, 5, 6, 7]
5.3
无限迷宫与最短(不加权)路径问题
清单5-9
清单 5-10 广度优先搜索
def bfs(G, s):
P, Q = {s: None}, deque([s])
while Q:
u = Q.popleft()
for v in G[u]:
if v in P:
continue
P[v] = u
Q.append(v)
return P
测试一下:
In [22]: from queue import deque
...: for i in range(8):
...: print(bfs(G, i))
...:
{0: None, 1: 0, 2: 0, 3: 0, 4: 0, 5: 0, 6: 5, 7: 5}
{1: None, 2: 1, 4: 1, 3: 2, 5: 4, 6: 5, 7: 5}
{2: None, 3: 2, 4: 3, 5: 4, 6: 5, 7: 5}
{3: None, 4: 3, 5: 4, 2: 5, 6: 5, 7: 5}
{4: None, 5: 4, 2: 5, 6: 5, 7: 5, 3: 2}
{5: None, 2: 5, 6: 5, 7: 5, 3: 2, 4: 3}
{6: None, 5: 6, 7: 6, 2: 5, 3: 2, 4: 3}
{7: None, 5: 7, 6: 7, 2: 5, 3: 2, 4: 3}
5.4 强连通分量
5.5 本章小结
通常情况下,一个图的遍历过程主要包括:
维护一个用来存放待探索节点的 to-do 列表,并从中除去已访问的节点,从遍历的起点开始,每次都访问 (并除去) 其中一个节点,并将其邻居节点加入到该列表中。在此列表中,项目的 (调度) 顺序很大程度上决定了我们实现的遍历类型。
比如:
- 采用 LIFO 队列执行的就是 DFS
- 采用 FIFO 队列执行的就是 BFS
第六章 分解、合并、解决
6.2 经典分治算法
清单 6-1 分治语义的一种通用性实现
def divide_and_conquer(S, divide, combine):
if len(S) == 1:
return S
L, R = divide(S)
A = divide_and_conquer(L, divide, combine)
B = divide_and_conquer(R, divide, combine)
return combine(A, B)
6.3 折半搜索
清单 6-2 二分搜索树的插入与搜索
class Node:
lft = None
rgt = None
def __init__(self, key, val):
self.key = key
self.val = val
def insert(node, key, val):
if node is None:
return Node(key, val)
if node.key == key:
node.val = val
elif node.key < key:
node.rgt = insert(node.rgt, key, val)
else:
node.lft = insert(node.lft, key, val)
def search(node, key):
if node is None:
raise KeyError
if node.key == key:
return node.val
elif node.key < key:
return search(node.rgt, key)
else:
return search(node.lft, key)
class Tree:
root = None
def __setitem__(self, key, val):
self.root = insert(self.root, key, val)
def __getitem__(self, key):
return search(self.root, key)
def __contains__(self, key):
try:
search(self.root, key)
except KeyError:
return False
return True
-
请看清单 2-1 ↩