解析Ceph: 存储引擎实现之一–FileStore
在 2014 年 01 月 11 日 上公布 作者为 麦子迈 文章分类 Ceph
Ceph作为一个高可用和强一致性的软件定义存储实现,去使用它非常重要的就是了解其内部的IO路径和存储实现。这篇文章主要介绍在IO路径中最底层的ObjectStore的实现之一FileStore。

ObjectStore
ObjectStore是Ceph OSD中最重要的概念之一,它封装了所有对底层存储的IO操作。从上图中可以看到所有IO请求在Clieng端发出,在Message层统一解析后会被OSD层分发到各个PG,每个PG都拥有一个队列,一个线程池会对每个队列进行处理。
当一个在PG队列里的IO被提出后,该IO请求会被根据类型和相关附带参数进行处理。如果是读请求会通过ObjectStore提供的API获得相应的内容,如果是写请求也会利用ObjectStore提供的事务API将所有写操作组合成一个原子事务提交给ObjectStore。ObjectStore通过接口对上层提供不同的隔离级别,目前PG层只采用了Serializable级别,保证读写的顺序性。
ObjectStore主要接口分为三部分,第一部分是Object的读写操作,类似于POSIX的部分接口,第二部分是Object的属性(xattr)读写操作,这类操作的特征是kv对并且与某一个Object关联。第三部分是关联Object的kv操作(在Ceph中称为omap),这个其实与第二部分非常类似,但是在实现上可能会有所变化。
目前ObjectStore的主要实现是FileStore,也就是利用文件系统的POSIX接口实现ObjectStore API。每个Object在FileStore层会被看成是一个文件,Object的属性(xattr)会利用文件的xattr属性存取,因为有些文件系统(如Ext4)对xattr的长度有限制,因此超出长度的Metadata会被存储在DBObjectMap里。而Object的omap则直接利用DBObjectMap实现。因此,可以看出xattr和omap操作是互通的,在用户角度来说,前者可以看作是受限的长度,后者更宽泛(API没有对这些做出硬性要求)。
FileJournal
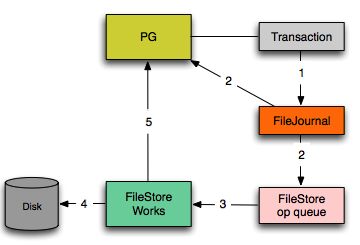
为了缩小写事务的处理时间,提高写事务的处理能力并且实现事务的原子性,FileStore引入了FileJournal,所有写事务在被FileJournal处理以后都会立即返回(上图中的第二步)。FileJournal类似于数据库的writeahead日志,使用O_DIRECT和O_DSYNC每次同步写入到journal文件,完成后该事务会被塞到FileStore的op queue。事务通常有若干个写操作组成,当在中间过程进程crash时,journal会OSD recover提供了完备的输入。FileStore会存在多个thread从op queue里获取op,然后真正apply到文件系统上对应的Object(Buffer IO)。当FileStore将事务落到disk上之后,后续的该Object的读请求才会继续(上图中的第五步)。当FileStore完成一个op后,对应的Journal可以丢弃这部分日志。
实际上并不是所有的文件系统都按照这个顺序,一般来说如Ceph推荐的Ext4和XFS文件系统会先写入Journal,然后再写入Filesystem,而COW(Copy on Write)文件系统如Btrfs和ZFS会同时写入Journal和FileSystem。
DBObjectMap

DBObjectMap是FileStore的一部分,利用KeyValue数据库实现了ObjectStore的第三部分API,DBObjectMap主要复杂在其实现了clone操作的no-copy。因为ObjectStore提供了clone API,提供对一个Object的完全clone(包括Object的属性和omap)。DBObjectMap对每一个Object有一个Header,每个Object联系的omap(kv pairs)对会与该Header联系,当clone时,会产生两个新的Header,原来的Header作为这两个新Header的parent,这时候无论是原来的Object还是cloned Object在查询或者写操作时都会查询parent的情况,并且实现copy-on-write。那么Header如何与omap(kv pairs)联系呢,首先每个Header有一个唯一的seq,然后所有属于该Header的omap的key里面都会包含该seq,因此,利用KeyValueDB的提供的有序prefix检索来实现对omap的遍历。
上面提到FileStore会将每个Object作为一个文件,那么Object的一些属性会与Object Name一起作为文件名,Object 所属的PG会作为文件目录,当一个PG内所包含的文件超过一定程度时(在目录内文件太多会造成文件系统的lookup性能损耗),PG会被分裂成两个PG。