机器学习理论与实战(十六)概率图模型04
04、概率图模型应用实例
最近一篇文章《Deformable Model Fitting by Regularized Landmark Mean-Shift》中的人脸点检测算法在速度和精度折中上达到了一个相对不错的水平,这篇技术报告就来阐述下这个算法的工作原理以及相关的铺垫算法。再说这篇文章之前,先说下传统的基于CLM(Constrained local model)人脸点检测算法的不足之处,ASM也属于CLM的一种,CLM顾名思义就是有约束的局部模型,它通过初始化平均脸的位置,然后让每个平均脸上的特征点在其邻域位置上进行搜索匹配来完成人脸点检测。整个过程分两个阶段:模型构建阶段和点拟合阶段。模型构建阶段又可以细分两个不同模型的构建:形状模型构建和Patch模型构建,如(图一)所示。形状模型构建就是对人脸模型形状进行建模,说白了就是一个ASM的点分布函数(PDM),它描述了形状变化遵循的准则。而Patch模型则是对每个特征点周围邻域进行建模,也就说建立一个特征点匹配准则,怎么判断特征点是最佳匹配。
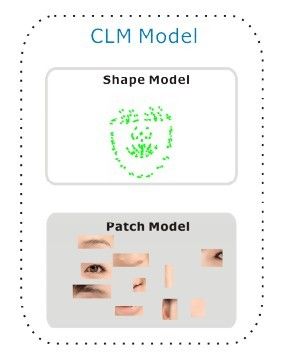
(图一) CLM模型:形状模型和Patch模型
下面就来详细说下CLM算法流程:
一、模型构建之形状模型构建(延续ASM的形状模型函数),如(公式一)所示:
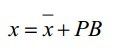
(公式一)
(公式一)中X-bar表示平均脸,P是形状变化的主成分组成的矩阵,它是一个关键的参数,下面就来看看它是如何得到的。假设我们有M张图片,每张图片有N个特征点, 每个特征点的坐标假设为(xi,yi),一张图像上的N个特征点的坐标组成的向量用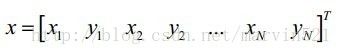 表示,所有图像的平均脸可用(公式二)求出:
表示,所有图像的平均脸可用(公式二)求出:
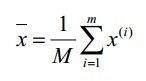
(公式二)
然后每张脸组成的向量都减去这个平均脸向量,就得到一个均值为0的形状变化矩阵X,如下表示:

一定要注意X此时是一个零均值的形状变化矩阵,因为每个行向量都减去了平均脸向量,也就是相对于平均脸的偏差,对XX’进行主成分分析,得到形状变化的决定性成分,即特征向量Pj以及相对应的特征值λj,选择前K个特征向量以列排放的方式组成形状变化矩阵P,这些特征向量其实就是所有样本变换的基,可以表述样本中的任意变化。有了形状变化矩阵P,(公式一)中的B就可以通过(公式三)得出:
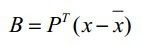
(公式三)
(公式三)中求出的B其实是形状变化的权重向量,决定哪些特征点起着关键作用。到这里就完成模型构建,当给定一个权重B时,我们就可以用(公式一)重建出一个形状,这个权重B在以后点拟合阶段起着关键作用。
二、模型构建之Patch模型构建
在构建好形状模型之后,我们就可以在检测到的人脸上初始化一个人脸形状模型,接下来的工作就是让每个点在其邻域范围内寻找最佳匹配点。传统的ASM模型就是沿着边缘的方向进行块匹配,点匹配等各种低级匹配,匹配高错误率导致ASM的性能不是很好。后续各种改进版本也就出来了,大部分做法都是对候选匹配特征点邻域内的块进行建模,我们统称他们为有约束的局部模型:CLM。这里先以基于SVM的匹配作为例子来说,因为这些都是铺垫知识,引出改进的算法。当我们初始化每个特征点后,用训练好的SVM对每个特征点周围进行打分,就像滤波器一样,得到一个打分响应图(response map),标识为R(X,Y),如(图二)所示:
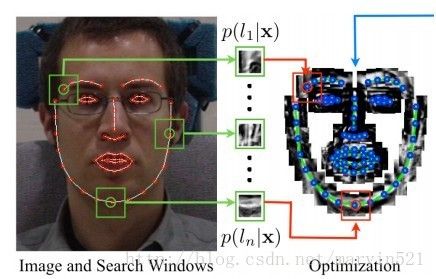
(图二) 特征点(左)其邻域响应图(右)
接下来就是对响应图拟合一个二次函数,假设R(X,Y)是在邻域范围内(x0,y0)处得到最大值,我们对这个位置拟合一个函数,使得位置和最大值R(X,Y)一一对应。拟合函数如(公式四)所示:

(公式四) 拟合最大响应位置二次函数
(公式四)中的a,b,c是我们要求的拟合二次函数的参数,求解方法就是使拟合函数r(x,y)和R(X,Y)之间的误差最小,即完成一个最小二乘法计算,如(公式五)所示:
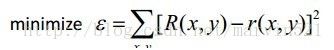
(公式五) 求取(公式四)的最小二乘法
通过(公式五)完成最小二乘法运算后得到(公式四)的参数a,b,c,有了参数a,b,c,那么r(x,y)其实就是一个关于特征点位置的目标代价函数,然后再加上一个形变约束代价函数就构成了特征点查找的目标函数,每次优化这个目标函数得到一个新的特征点位置,然后在迭代更新,直到收敛到最大值,就完成了人脸点拟合。目标函数如(公式六)所示:
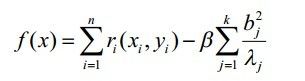
(公式六) 目标函数
在(公式六)的目标函数中第二项就是形状约束,b是上面说的形变成分的权重,而lambda则是形变成分(主成分分析中的空间轴)对应的幅度(主成分分析的特征值)。对于整个目标函数,你可以这样理解,第一项是拟合位置作为新特征点位置的代价,而这个位置的代价再减去平均形状的变化,这样就形成了位置和形状两种约束的制约,如果一个在一个歧义的位置得到的r(x,y)分很高,但是离平均脸很远,那么f(x)值也会很小,那就不是最优值。我们比较关心的是目标函数中的两项约束是否是一一对应,等比例增长的。这点不用担心,如果把(公式六)展开用矩阵的形式写出来的话,可以变成(公式七)的样子:
(公式七) 目标函数展开
其中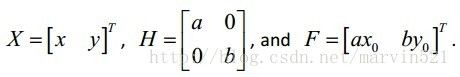
可以看出(公式七)是个关于特征点位置X的二次凸函数,有全局最优解。每次求出最优解,然后再计算邻域响应图,在求解直到收敛时就完成了特征点的拟合查找工作。
这个算法理论还是可以,但有几点不足:第一、从SVM里得到的响应图是否真实可靠?这点其实也正是要改进的地方。第二、每次迭代都要优化一个二次函数计算量也蛮大,这会拖慢速度,无法实时。第三、形变约束是否有争议,能否让你信服?而且形状模型根本没考虑到现实情况中的缩放,旋转和平移。
带着这三个问题,我们进入文章一开头就提到的那篇文章的算法,我们简称它为DMF_ MeanShift, DMF_MeanShift使用的点分布模型(形状模型)如(公式八)所示:
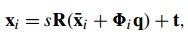
(公式八)点分布模型
(公式八)中的要求参数为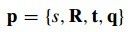 ,分别表示缩放,旋转,平移,主成分权重。而x-bar和fai则表示平均脸和形变主成分矩阵,和CLM中的一样。现在我们的目标仍然是优化一个有形变约束和匹配代价约束组成的目标函数,如(公式九)所示:
,分别表示缩放,旋转,平移,主成分权重。而x-bar和fai则表示平均脸和形变主成分矩阵,和CLM中的一样。现在我们的目标仍然是优化一个有形变约束和匹配代价约束组成的目标函数,如(公式九)所示:
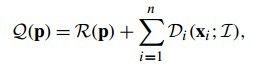
(公式九)
这里要注意一下,R(P)表示形变约束,对应CLM(公式六)中的第二项,D表示匹配代价,对应CLM(公式六)中的第一项。这两项在DMF_MeanShift中都要发生变化,不再使用CLM中的约束规则,而使用概率分布的形式来表述,全部在概率图模型的框架中完成推理求解,下面来看看是如何把(公式九)中的两项约束转换成概率约束的。
对于(公式九)中的求取形状模型参数的目标函数,在概率模型中可以描述成一个当所有特征点都匹配最优时模型参数的最大似然。意思就是说在训练样本中,给定所有样本点匹配最优时的最大似然估计。当给定图像块时,每个检测器之间是相互独立的(这个条件独立有争议,我现在还没有彻底推倒出来),那么这个似然函数可以写成(公式十)的形式:
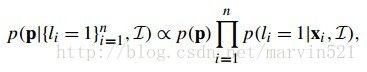
(公式十)
在(公式十)中,左边表示给定匹配点和图像块时,参数的似然函数,右边则是条件独立分解。其中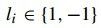 表示该特征点i是否是最优匹配点,1表示是,-1表示否。两边同时取自然对数后,乘法变加法,得到(公式十一):
表示该特征点i是否是最优匹配点,1表示是,-1表示否。两边同时取自然对数后,乘法变加法,得到(公式十一):
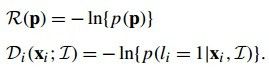
(公式十一)
(公式十一)中的两项就和CLM中的两项约束对应上了,而且转换到了概率空间,接下来的步骤就是对这两项的分布进行近似估计。估计的方法很多,而且很复杂,这里为了方便理解,先贴出几个估计方法的对比效果图,如(图三)所示:

(图三)
在(图三)中RES表示真实响应图,而ISO,ANI,GMM和KDE分别表示各向同性高斯估计、各向异性高斯估计、混合高斯估计和核密度估计,从(图三)中可以看出基于核密度估计得逼近分布和真实响应图最接近。由于前三个近似逼近方法效果不好,而且推导过程复杂,这里就不再说了,只简单说下效果最好的KDE逼近方法。
由于在(公式一)中的形变矩阵P扔掉了一些很小的成分,因此重建的形状点并不是百分百正确,有一定的误差,我们可以这个误差看成观察噪声,它服从同方差各向同性高斯分布,如(公式十二)所示:

(公式十二)
其中ρ表示噪声的协方差,可以通过(公式十三)求出(Moghaddam and Pentland1997):
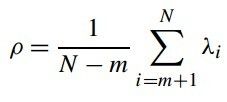
(公式十三)
其实就是主成分分析中特征值的算术平均,通过(公式十二)我们也可以得到给定Xi时yi的条件概率,如(公式十四)所示:
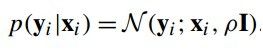
(公式十四)
(公式十四)的推倒是通过混合高斯分布推倒出来的,这里也不再推倒。假设特征点候选区域为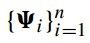 ,把真实特征点的位置看成隐变量y,那么特征点匹配的似然函数可以通过积分掉隐变量y得到,如(公式十五)所示:
,把真实特征点的位置看成隐变量y,那么特征点匹配的似然函数可以通过积分掉隐变量y得到,如(公式十五)所示:
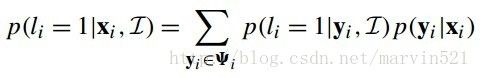
(公式十五)
综合(公式十四)和(公式十五),我们得到一个非参形式的响应图近似估计,如(公式十六)所示:
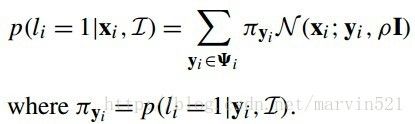
(公式十六)
把(公式十六)这个匹配代价约束带入(公式十)中,我们得到最一个关于参数P的似然概率分布函数,如(公式十七)所示:

(公式十七)
只要求解此最大似然函数就可以求出参数P,也就是求取使得关于参数P的边缘概率最大时对应的参数P,这是一个无向图模型,如果你不能抽象出图模型,可以参看(图四)所示:

(图四)
(图四)中Li表示观察,y表示隐藏变量,P表示参数。这个关于P的边缘概率可以通过概率图模型的中的BP算法求解,有兴趣的可以翻看参考文献[6]的Appendix。这里采用另外一种求解方法:EM算法。因为真实位置标签y我们不知道,是个隐变量,而且参数P也不知道,很自然的就想到了EM算法。EM算法的推倒也比较复杂,这里就直接贴图了,反正最后的结论才是我们想要的,如(图五)所示。

(图五)
(图五)中的等式(33)对应本文的(公式十七)。最后得到的等式(36)就是我们想要的梯度,有了梯度就可以更新参数P,而且也可以通过(公式十八)来更新候选特征点匹配的位置:

(公式十八)
(公式十八)的得出是在参考文献[6]的各向同性高斯逼近方法中推倒出来的,用的是泰勒展开方法,这里的推倒在后续有时间再补充。这样通过更新特征点匹配位置,有了新位置然后计算deltaP,然后更新参数P,重复上述过程直到参数P收敛为止,就完成了特征点匹配检测。整个过程有点像Mean-Shift算法,所以算法名中出现Mean-Shift。这个算法的好处就是融合进了各种形变参数,并且使得参数可以迭代更新,更新速度也挺快。
本篇文章只能算是介绍下概率图图模型的一个应用,了解人脸特征点检测详细原理需要阅读参考文献[6],欢迎提供关于各向同性高斯估计、各向异性高斯估计、混合高斯估计和核密度估计的相关资料和讨论。
转载请注明来源:http://blog.csdn.net/marvin521/article/details/11489453
参考文献:
[1] Gaussian mean-shift is an EM algo-rithm.Carreira-Perpinan, M. (2007)
[2] On the number of modes of a Gaussianmixture. Carreira-Perpinan, M., & Williams, C. (2003)
[3] Active shape models—‘smart snakes’.Cootes, T., & Taylor, C. (1992)
[4] Constrained Local Model for FaceAlignment. Xiaoguang Yan(2011)
[5] Face Alignment through SubspaceConstrained Mean-Shifts. Jason M. Saragih(2009)
[6] Deformable Model Fitting by RegularizedLandmark Mean-Shift. Jason M. Saragih(2011)
[7] Support vector tracking. Avidan, S.(2004)