golang 高性能日志库zap架构分析
工欲善其事,必先利其器,一个高性能的日志库对于项目的重要性不言而喻。在选择日志组件的时候也有多方面的考量:详细的信息、及时的反馈是必不可少的,但是日志的性能往往是决定是否可以采用的重要条件,在一个注重性能的程序中,如果日志效率不高就会成为整个项目的瓶颈。zap是uber开源的Go高性能日志库,如果和lumberjack配合使用还可以实现日志文件按大小或者时间归档的功能,lumberjack也是zap官方推荐的配置。
我们将结合zap架构和源码来说明为zap可以实现高性能的日志,整体架构图:
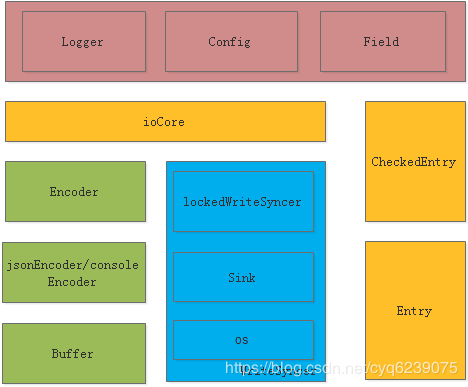
Zap将内部模块划分成4部分:
- API 接口部分,主要模块是Logger,Config,Field等模块,Config提供用户灵活配置接口,Logger实例化等接口。Logger模块主要提供用户一组写日志接口,Field提供一组kv值。
- 日志编码部分,主要的模块有Encoder、jsonEncoder/consoleEncoder、Buffer。Encoder提供编码管理,jsonEncoder/consoleEncoder提供具体的编解码功能,Buffer提供编码的数据载体。
- 写日志部分,这部分的主要模块有lockedWriteSyncer、Sink、os。lockedWriteSyncer是用来防止并发写,Sink是对os的一层包装。如果设置了hook会在这里将数据转入hook中
- 最后一部分是日志的管理,主要的模块有ioCore、CheckedEntry、Entry。其实就是管理日志编码和写日志文件。
-
API接口和log初始化
zap对外提供的是 logger 对象和 field和level。这是zap对外提供的基本语义:logger 对象打印log,field则是log的组织方式,level跟打印的级别相关。每个zapcore.Field其实就是一组键值对参数,使用Field时zap为了提供性能而放弃了部分易用性,正常的理解是使用fmt.Sprintf 来格式化输出我们想要的字符串,但是fmt.Sprintf是通过反射机制来识别我们传入的类型,反射过于耗时,所以为了提高性能zap需要用户自己指明类型。
先看log实例化过程:
func (cfg Config) Build(opts ...Option) (*Logger, error) {
enc, err := cfg.buildEncoder()//根据用户配置的编码器来构造编码器
if err != nil {
return nil, err
}
sink, errSink, err := cfg.openSinks()//根据用户配置的文件路径初始化写入文件
if err != nil {
return nil, err
}
//生成log实例
log := New(
zapcore.NewCore(enc, sink, cfg.Level),//io管理结构core
cfg.buildOptions(errSink)...,//将用户配置应用到log实例中
)
if len(opts) > 0 {
log = log.WithOptions(opts...)
}
return log, nil
}
编码器zap支持jsonEncoder和consoleEncoder,我们以用户配置json格式为例,实际设置编码器的位置:
func newJSONEncoder(cfg EncoderConfig, spaced bool) *jsonEncoder {
return &jsonEncoder{
EncoderConfig: &cfg,
buf: bufferpool.Get(),
spaced: spaced,
}
}
这里的bufferpool.Get() 是从buffer模块的内存池中申请一段buf,默认长度是1024
再来看日志文件是如何管理的,打开日志文件会用了WriteSyncer类型作为在各个接口之间的类型,WriteSyncer本身是个interface类型,首先是创建sink:
func newSink(rawURL string) (Sink, error) {
u, err := url.Parse(rawURL)
if err != nil {
return nil, fmt.Errorf("can't parse %q as a URL: %v", rawURL, err)
}
if u.Scheme == "" {
u.Scheme = schemeFile
}
_sinkMutex.RLock()
factory, ok := _sinkFactories[u.Scheme]
_sinkMutex.RUnlock()
if !ok {
return nil, &errSinkNotFound{u.Scheme}
}
return factory(u)
}
这里也是使用默认的本都文件schemeFile,实际的执行函数是newFileSink
func newFileSink(u *url.URL) (Sink, error) {
if u.User != nil {
return nil, fmt.Errorf("user and password not allowed with file URLs: got %v", u)
}
if u.Fragment != "" {
return nil, fmt.Errorf("fragments not allowed with file URLs: got %v", u)
}
if u.RawQuery != "" {
return nil, fmt.Errorf("query parameters not allowed with file URLs: got %v", u)
}
// Error messages are better if we check hostname and port separately.
if u.Port() != "" {
return nil, fmt.Errorf("ports not allowed with file URLs: got %v", u)
}
if hn := u.Hostname(); hn != "" && hn != "localhost" {
return nil, fmt.Errorf("file URLs must leave host empty or use localhost: got %v", u)
}
switch u.Path {
case "stdout":
return nopCloserSink{os.Stdout}, nil
case "stderr":
return nopCloserSink{os.Stderr}, nil
}
return os.OpenFile(u.Path, os.O_WRONLY|os.O_APPEND|os.O_CREATE, 0644)
}
函数很简单。在创建了sink后调用CombineWriteSyncers,然后是Lock函数:
func Lock(ws WriteSyncer) WriteSyncer {
if _, ok := ws.(*lockedWriteSyncer); ok {
// no need to layer on another lock
return ws
}
return &lockedWriteSyncer{ws: ws}
}
这么做有两个目的:1是在sink上封装一层便于做写互斥。2是可以将多个sink做个封装,毕竟用户可能会想向多个文件中写。
再回到build函数中,开始创建core,就是将上面创建好的enc和sink赋值给core。还有用户的配置信息没处理,在创建log实例前需要收集用户配置了哪些项,Config.buildOptions()完成此功能,也不再展开说,自己看看就明白。准备工作都完成开始进入new函数创建log实例:
func New(core zapcore.Core, options ...Option) *Logger {
if core == nil {
return NewNop()
}
log := &Logger{
core: core,
errorOutput: zapcore.Lock(os.Stderr),
addStack: zapcore.FatalLevel + 1,
}
return log.WithOptions(options...)//将用户配置应用到log实例
}
为了提供性能这里一是采用内存池分配buf和Field,二是避免使用反射机制。
zap 还在 logger 这层提供了丰富的工具包,这让整个 zap 库更加的易用:
grpc logger:封装 zap logger 可以直接提供给 grpc 使用,对于大多数的 Go 分布式程序,grpc 都是默认的 rpc 方案,grpc 提供了 SetLogger 的接口。 zap 提供了对这个接口的封装。
hook:作为 zap。Core 的实现,zap 提供了 hook。 使用方实现 hook 然后注册到 logger,zap在合适的时机将日志进行后续的处理,例如写 kafka,统计日志错误率 等等。
std Logger: zap 提供了将标准库提供的 logger 对象重定向到 zap logger 中的能力,也提供了封装 zap 作为标准库 logger 输出的能力。 整体上十分易用。
sublog: 通过创建 绑定了 field 的子logger,实现了更加易用的功能。
-
写日志流程
根据用户在config中的配置,不同的level控制不同的输出,例如:
debug可以打印出info,debug,warn;info级别可以打印warn,info;warn只能打印warn。我们以info为例:
func (log *Logger) Info(msg string, fields ...Field) {
if ce := log.check(InfoLevel, msg); ce != nil {
ce.Write(fields...)
}
}
check函数实现两个目的:1、过滤不符合等级的日志,2、将需要记录的日志封装CheckedEntry。
func (log *Logger) check(lvl zapcore.Level, msg string) *zapcore.CheckedEntry {
const callerSkipOffset = 2
ent := zapcore.Entry{//一条日志对应一条entry
LoggerName: log.name,
Time: time.Now(),
Level: lvl,
Message: msg,
}
ce := log.core.Check(ent, nil)//将entry转成CheckedEntry
willWrite := ce != nil
//设置终端行为
switch ent.Level {
case zapcore.PanicLevel:
ce = ce.Should(ent, zapcore.WriteThenPanic)
case zapcore.FatalLevel:
ce = ce.Should(ent, zapcore.WriteThenFatal)
case zapcore.DPanicLevel:
if log.development {
ce = ce.Should(ent, zapcore.WriteThenPanic)
}
}
if !willWrite {//如果不满足打印等级则返回
return ce
}
// 记录调用栈等信息
ce.ErrorOutput = log.errorOutput
if log.addCaller {
ce.Entry.Caller = zapcore.NewEntryCaller(runtime.Caller(log.callerSkip + callerSkipOffset))
if !ce.Entry.Caller.Defined {
fmt.Fprintf(log.errorOutput, "%v Logger.check error: failed to get caller\n", time.Now().UTC())
log.errorOutput.Sync()
}
}
if log.addStack.Enabled(ce.Entry.Level) {
ce.Entry.Stack = Stack("").String
}
return ce
}
生成CheckedEntry:
func (ce *CheckedEntry) AddCore(ent Entry, core Core) *CheckedEntry {
if ce == nil {
ce = getCheckedEntry()
ce.Entry = ent
}
ce.cores = append(ce.cores, core)
return ce
}
这里还是使用了内存池创建CheckedEntry,只不过从池中申请CheckedEntry时会进行reset,为什么在在申请是会reset而不是在put时呢?这也是为了提高性能,使用时才进行reset,避免无用的消耗。
日志编码是在写的流程中,顺着write一直看进入ioCore.Write:
func (c *ioCore) Write(ent Entry, fields []Field) error {
buf, err := c.enc.EncodeEntry(ent, fields)//日志编码
if err != nil {
return err
}
_, err = c.out.Write(buf.Bytes())//输出到文件
buf.Free()
if err != nil {
return err
}
if ent.Level > ErrorLevel {
// Since we may be crashing the program, sync the output. Ignore Sync
// errors, pending a clean solution to issue #370.
c.Sync()
}
return nil
}
进入日志编码EncodeEntry,以json格式为例:
func (enc *jsonEncoder) EncodeEntry(ent Entry, fields []Field) (*buffer.Buffer, error) {
final := enc.clone()
final.buf.AppendByte('{')
if final.LevelKey != "" {
final.addKey(final.LevelKey)
cur := final.buf.Len()
final.EncodeLevel(ent.Level, final)
if cur == final.buf.Len() {
// User-supplied EncodeLevel was a no-op. Fall back to strings to keep
// output JSON valid.
final.AppendString(ent.Level.String())
}
}
if final.TimeKey != "" {
final.AddTime(final.TimeKey, ent.Time)
}
if ent.LoggerName != "" && final.NameKey != "" {
final.addKey(final.NameKey)
cur := final.buf.Len()
nameEncoder := final.EncodeName
// if no name encoder provided, fall back to FullNameEncoder for backwards
// compatibility
if nameEncoder == nil {
nameEncoder = FullNameEncoder
}
nameEncoder(ent.LoggerName, final)
if cur == final.buf.Len() {
// User-supplied EncodeName was a no-op. Fall back to strings to
// keep output JSON valid.
final.AppendString(ent.LoggerName)
}
}
if ent.Caller.Defined && final.CallerKey != "" {
final.addKey(final.CallerKey)
cur := final.buf.Len()
final.EncodeCaller(ent.Caller, final)
if cur == final.buf.Len() {
// User-supplied EncodeCaller was a no-op. Fall back to strings to
// keep output JSON valid.
final.AppendString(ent.Caller.String())
}
}
if final.MessageKey != "" {
final.addKey(enc.MessageKey)
final.AppendString(ent.Message)
}
if enc.buf.Len() > 0 {
final.addElementSeparator()
final.buf.Write(enc.buf.Bytes())
}
addFields(final, fields)
final.closeOpenNamespaces()
if ent.Stack != "" && final.StacktraceKey != "" {
final.AddString(final.StacktraceKey, ent.Stack)
}
final.buf.AppendByte('}')
if final.LineEnding != "" {
final.buf.AppendString(final.LineEnding)
} else {
final.buf.AppendString(DefaultLineEnding)
}
ret := final.buf
putJSONEncoder(final)
return ret, nil
}
具体编码过程不再细说,编码完成后就可以写入文件:
func (s *lockedWriteSyncer) Write(bs []byte) (int, error) {
s.Lock()
n, err := s.ws.Write(bs)
s.Unlock()
return n, err
}