python与R实现决策树算法和参数调整(基于ID3、CART、C4.5)
决策树算法的讲解网上有很多资料了,这个是我在B站上看到的视频讲解:
决策树算法
决策树python代码
随机森林算法和代码
讲得蛮好挺清楚的~所以这篇文章的重点就放在决策树算法在python和R上的实现,以及参数的调整上。
python与R实现决策树算法
- 一、基于python
- (一)绘图环境的配置(Graphviz安装)
- (二)分类树
- 1、模型拟合与决策树可视化
- 2、重要属性、接口
- 3、重要参数
- (三)回归树
- (四)总结
- 二、基于R
- (一)ID3算法
- (二)CART算法
- (三)C4.5算法
一、基于python
(一)绘图环境的配置(Graphviz安装)
为了要画出好看的决策树图像,要先安装Graphviz ,这是一个自动排版的作图软件,可以很方便的用来绘制结构化的图形网络,支持png、jpg等多种格式输出。而Graphviz 的输入是一个用 dot 语言编写的绘图脚本,通过对输入脚本的解析,分析出其中的点、边及子图,然后根据属性进行绘制。python中有一个graphviz库,可以将拟合好的决策树模型转化为编写好的dot文件,只要再用软件Graphviz解析该dot文件便可将决策树可视化了。
安装步骤如下所示:
1、python上安装graphviz库:
pip install graphviz
2、官网上安装Graphviz软件并配置环境变量:
Graphviz官网链接
下载msi文件:
 将bin文件夹和bin文件下dot.exe文件目录都添加至系统环境变量中:
将bin文件夹和bin文件下dot.exe文件目录都添加至系统环境变量中:

3、可以在命令行使用dot -version命令查看graphviz版本,或在python上编写dot脚本,得到流程图片
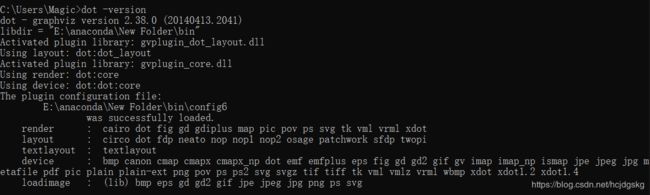
 至此绘制决策树的环境就搭建好了,进一步进行模型拟合:
至此绘制决策树的环境就搭建好了,进一步进行模型拟合:
(二)分类树
1、模型拟合与决策树可视化
以sklearn.datasets库中的load_wine红酒数据集来进行模型拟合,导入数据集:
from sklearn import tree
from sklearn.datasets import load_wine#红酒数据
from sklearn.model_selection import train_test_split
探索数据集,这是一个由13个特征与一个有3种类型的标签数据组成的数据集:
wine = load_wine() #数据实例化
import pandas as pd
pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)],axis=1)
划分训练集、测试集,并拟合模型
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3)
print(Xtrain.shape)
print(Xtest.shape)
clf = tree.DecisionTreeClassifier(criterion="entropy")
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest) #返回预测的准确度
score
决策树可视化:
import graphviz
feature_name=['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜 色强度','色调','od280/od315稀释葡萄酒','脯氨酸']
dot_data=tree.export_graphviz(clf,
feature_names = feature_name,
class_names=['琴酒','雪莉','贝尔摩德'],
filled=True,#是否填充颜色,不纯度越低颜色越深
rounded=True,
out_file = ".\Tree0.dot")
#中文会出现乱码,还需进行dot_data文件格式转换
import re
# 打开 dot_data.dot,修改 fontname="支持的中文字体"
f = open("./Tree0.dot", "r+", encoding="utf-8")
open('./Tree_utf8.dot', 'w', encoding="utf-8").write(re.sub(r'fontname=helvetica', 'fontname="Microsoft YaHei"', f.read()))
f.close()
在cmd运行以下代码(注意路径中不要有中文),生成png格式的图片:
dot -Tpng E:\py_machine\decision_tree\Tree_utf8.dot -o E:\py_machine\decision_tree\Tree0.png
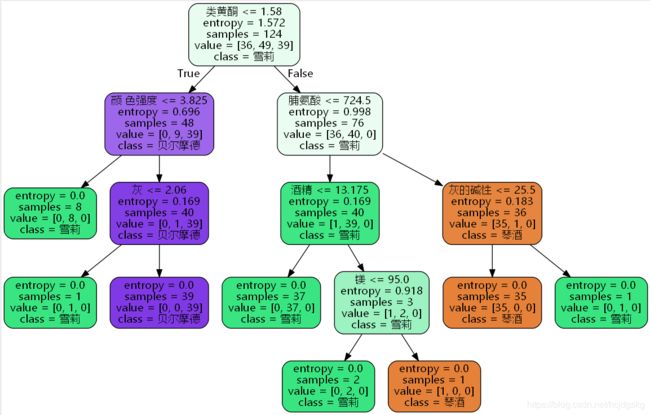 也可以在python上直接查看图片(不设置out_file参数):
也可以在python上直接查看图片(不设置out_file参数):
dot_data=tree.export_graphviz(clf,
feature_names = feature_name,
class_names=['琴酒','雪莉','贝尔摩德'],
filled=True,#是否填充颜色,不纯度越低颜色越深
rounded=True)#框的形状
graph=graphviz.Source(dot_data)
graph
2、重要属性、接口
1、查看特征重要性:feature_importances_
clf.feature_importances_
[*zip(feature_name,clf.feature_importances_)]

2、返回每个测试样本所在叶子节点的索引:apply
clf.apply(Xtest)
3、返回每个测试样本的分类/回归结果:predict
clf.predict(Xtest)
4、其他重要属性和接口:fit(拟合训练集数据)、score(获得准确率)
clf=clf.fit(Xtrain,Ytrain)
score=clf.score(Xtest,Ytest)
3、重要参数
1、 random_state & splitter 控制随机性
random_state用来设置分支中的随机模式的参数,输入任意整数,它会保证一直长出同一棵树,让模型稳定下来。
splitter也是用来控制决策树中的随机选项的,有两种输入值,输入”best",决策树在分支时虽然随机,但是还是会优先选择更重要的特征进行分支(重要性可以通过属性feature_importances_查看),输入“random",决策树在⽀支时会更加随机,树会因为含有更多的不必要信息而更深更大,并因这些不必要信息而降低对训练集的拟合,因此这也是防止过拟合的一种方式。
clf = tree.DecisionTreeClassifier(criterion="entropy",random_state=500,splitter="random")#random_state取任意整数
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest) #返回预测的准确度
#随机性增加,树也会明显变大
2、剪枝参数:
决策树可以很好地处理分类问题,但常会由于节点数过多致使过拟合问题的出现,于是出现了控制预剪枝、后剪枝等的剪枝参数,这也是决策树算法实现过程中需要调节的很重要的参数。
max_depth: 控制最大深度
min_samples_leaf: 限定一个节点在分枝后的每个子节点都必须包含至少min_samples_leaf个训练样本,否则分枝就不会发生,或者,分枝会朝着满足每个子节点都包含min_samples_leaf个样本的方向去发生 min_samples_split: 限定一个节点必须要包含至少min_samples_split个训练样本,这个节点才允许被分枝,否则分枝就不会发生
max_features:用暴力方法限制特征数量,相较而言要通过减少特征数量来防止过拟合的话,用PCA、随机森林等降维和特征选择方法更好
min_impurity_decrease:限制信息增益的大小,信息增益小于设定数值的分枝不会发生
clf=tree.DecisionTreeClassifier(criterion="entropy",random_state=500,splitter="random",max_depth=3,min_samples_leaf=10,min_samples_split=10)
clf=clf.fit(Xtrain,Ytrain)
dot_data=tree.export_graphviz(clf,feature_names = feature_name,
class_names=['琴酒','雪莉','贝尔摩德'],
filled=True,
rounded=True)
graph=graphviz.Source(dot_data)
graph
#出来的图就会小许多
画出max_depth参数的学习曲线,进行超参数的确定(其他参数同理):
import matplotlib.pyplot as plt
test=[]
for i in range(10):
clf=tree.DecisionTreeClassifier(max_depth=i+1,#其他参数也可以一一画出学习曲线
criterion="entropy",
random_state=30,
splitter="random"
)
clf=clf.fit(Xtrain,Ytrain)
score=clf.score(Xtest,Ytest)
test.append(score)
plt.plot(range(1,11),test,color="red",label="max_depth")
plt.legend()
plt.show()
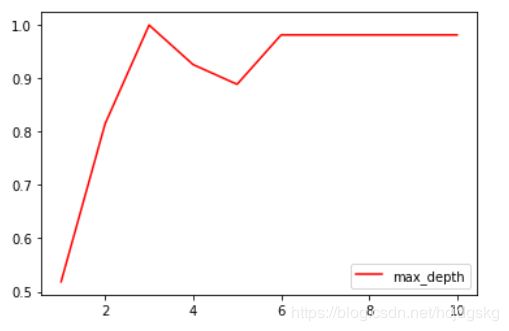
可看出将max_depth设置为3比较好
3、目标权重参数(针对非平衡数据):
class_weight & min_weight_fraction_leaf
在样本不平衡问题中,使用class_weight参数对样本标签进行一定的均衡,给少量的标签更多的权重,让模型更偏向少数类,向捕获少数类的方向建模。该参数默认None,此模式表示自动给与数据集中的所有标签相同的权重。 有了权重之后,样本量就不再是单纯地记录数目,而是受输入的权重影响了,因此这时候剪枝,就需要搭配min_weight_fraction_leaf这个基于权重的剪枝参数来使用。另请注意,基于权重的剪枝参数(例如min_weight_fraction_leaf)将比不知道样本权重的标准(比如min_samples_leaf)更少偏向主导类。如果样本是加权的,则使用基于权重的预修剪标准来更容易优化树结构,这确保叶节点至少包含样本权重的总和的一小部分。
(三)回归树
将DecisionTreeClassifier换成DecisionTreeRegressor即可;
from sklearn.datasets import load_boston
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeRegressor
boston = load_boston()
import pandas as pd
pd.concat([pd.DataFrame(boston.data),pd.DataFrame(boston.target)],axis=1)
regressor = DecisionTreeRegressor(random_state=0)
scores=cross_val_score(regressor, boston.data, boston.target, cv=10,scoring = "neg_mean_squared_error") #交叉验证cross_val_score的用法
import numpy as np
print('cv准确性:%.3f +/- %.3f'%(np.mean(scores),np.std(scores)))
(四)总结
参数和属性接口总结:
两个控制随机性参数(random_state,splitter)
五个剪枝参数(max_depth,min_samples_split,min_samples_leaf,max_feature,min_impurity_decrease)
一个属性:feature_importances_
四个接口:fit、score、array、predict
补充:criterion参数可取:entropy(信息熵—ID3)、gini(基尼系数—CART),即衡量不纯度的标准
决策树的优缺点总结:

二、基于R
在选择哪个自变量作为树叉时,根据采用的计算方式不同,可将决策树算法分为ID3、c4.5、CART等类型,ID3决策树分类的根据是样本集分类前后的信息增益,c4.5决策树分类的根据是样本集分类前后的信息增益率,CART决策树分类的根据是Gini指数,python的sklearn库中只有ID3和CART算法的,现用R来进行三个算法的实现,并分别进行预剪枝、后剪枝和可视化。
先下载各个包
install.packages('rpart')
install.packages('rJava')
install.packages('RWeka')
install.packages('partykit')
install.packages('grid')
install.packages('libcoin')
install.packages('mvtnorm')
C4.5算法使用RWeka包,RWeka包的安装需要依赖于rJava包,还需要安装java环境,下载jdk,配置环境变量。java环境的配置可以参考:百度经验 等其他文章
(一)ID3算法
library(rpart)
library(rpart.plot)
#读取数据
data<-read.csv("newdata.csv")
head(data)
#划分数据集
set.seed(123)
train_index<-sample(nrow(data),0.7*nrow(data))
train_index
train_set<-data[train_index,]
test_set<-data[-train_index,]
#构建ID3算法未剪枝决策树模型
TreeID3=rpart(train_set$是否违约~.,data=train_set,method="class",
parms=list(split="information"),minsplit=0)
#ID3未剪枝决策树
print(TreeID3)
printcp(TreeID3)
#ID3未剪枝决策树可视化
rpart.plot(TreeID3,branch=1,type=2, fallen.leaves=T,under=T,cex=0.9,sub="未剪枝ID3树")
#未剪枝决策树模型评价
TreeID3_pred=predict(TreeID3,test_set,type='class')
table(test_set$是否违约,TreeID3_pred,dnn=c("T","P"))
#显示样本数的图形
library(rpart.plot)
prp(TreeID3,type=1,extra=2,digits=3,col=rainbow(5),lwd=2,cex=1.2)
#构建ID3算法预剪枝模型
p_TreeID3=rpart(train_set$是否违约~.,data=train_set,method="class",
parms=list(split="information"),minsplit=14)
#ID3预剪枝决策树
print(p_TreeID3)
printcp(p_TreeID3)
#ID3预剪枝决策树可视化
rpart.plot(p_TreeID3,branch=1,type=5, fallen.leaves=T,under=T,cex=1, sub="预剪枝ID3树")
#预剪枝决策树模型评价
p_TreeID3_pred=predict(p_TreeID3,test_set,type='class')
table(test_set$是否违约,p_TreeID3_pred,dnn=c("T","P"))
#构建ID3算法后剪枝模型
a_TreeID3<-prune(TreeID3,cp=0.05)
#ID3后剪枝决策树
print(a_TreeID3)
printcp(a_TreeID3)
#ID3后剪枝决策树可视化
rpart.plot(a_TreeID3,branch=1,type=5, fallen.leaves=T,under=T,cex=1, sub="后剪枝ID3树")
#后剪枝决策树模型评价
a_TreeID3_pred=predict(a_TreeID3,test_set,type='class')
table(test_set$是否违约,a_TreeID3_pred,dnn=c("T","P"))
(二)CART算法
#构建CART算法未剪枝决策树模型
TreeCart=rpart(train_set$是否违约~.,data=train_set,method="class",
parms=list(split="gini"),minsplit=0)
#CART未剪枝决策树
print(TreeCart)
printcp(TreeCart)
#CART未剪枝决策树可视化
rpart.plot(TreeCart,branch=1,type=5, fallen.leaves=T,under=T,cex=0.9, sub="未剪枝Cart树")
#未剪枝决策树模型评价
TreeCart_pred=predict(TreeCart,test_set,type='class')
table(test_set$是否违约,TreeCart_pred,dnn=c("T","P"))
#构建CART算法预剪枝决策树模型
p_TreeCart=rpart(train_set$是否违约~.,data=train_set,method="class",
parms=list(split="gini"),minsplit=17)
#CART预剪枝决策树
print(p_TreeCart)
printcp(p_TreeCart)
#CART预剪枝决策树可视化
rpart.plot(p_TreeCart,branch=1,type=5, fallen.leaves=T,under=T,cex=1, sub="预剪枝Cart树")
#预剪枝决策树模型评价
p_TreeCart_pred=predict(p_TreeCart,test_set,type='class')
table(test_set$是否违约,p_TreeCart_pred,dnn=c("T","P"))
#构建CART算法后剪枝决策树模型
a_TreeCart<-prune(TreeCart,cp=0.05)
#CART后剪枝决策树
print(a_TreeCart)
printcp(a_TreeCart)
#CART后剪枝决策树可视化
rpart.plot(a_TreeCart,branch=1,type=2, fallen.leaves=T,under=T,cex=1, sub="后剪枝Cart树")
#后剪枝决策树模型评价
a_TreeCart_pred=predict(a_TreeCart,test_set,type='class')
table(test_set$y,a_TreeCart_pred,dnn=c("T","P"))
(三)C4.5算法
library(rJava)
library(RWeka)
library(partykit)
library(grid)
set.seed(123)
edata = data
names(edata)=c('Sepal.Length','Sepal.Width','Petal.Length','Petal.Width','Species')
newtrain_index=sample(nrow(edata),0.7*nrow(edata))
newtrain_set=edata[newtrain_index,]
newtest_set=edata[-newtrain_index,]
#读取数据
data<-iris
head(data)
#划分数据集
set.seed(123)
train_index<-sample(nrow(data),0.8*nrow(data))
train_set<-data[train_index,]
test_set<-data[-train_index,]
#构建C4.5算法未剪枝决策树模型
TreeC45=J48(factor(train_set$y)~.,data=train_set)
#C4.5未剪枝决策树
print(TreeC45)
#C4.5未剪枝决策树可视化
plot(TreeC45,main="未剪枝c45")
#C4.5未剪枝决策树可视化
TreeC45_pred=predict(TreeC45,test_set,type='class')
table(test_set$y,TreeC45_pred,dnn=c("T","P"))
#构建C4.5算法预剪枝决策树模型
p_TreeC45=J48(factor(train_set$y)~.,data=train_set,
control=Weka_control(U=F,M=5))
#C4.5预剪枝决策树
print(p_TreeC45)
#C4.5预剪枝决策树可视化
plot(p_TreeC45,main="预剪枝c45")
#C4.5预剪枝决策树可视化
p_TreeC45_pred=predict(p_TreeC45,train_set,type='class')
table(train_set$y,p_TreeC45_pred,dnn=c("T","P"))